Polygon zkEVM-Hermez 2.0简介
1. 引言
前序博客有:ZK-Rollups工作原理
近期,Polygon团队开源了其Hermez 2.0 zkEVM代码,公开测试网即将上线:https://github.com/0xpolygonhermez(Go/C++等等)
上图源自 Jordi 2022年10月分享Technical Details of the Opcode Compatible zkEVM by Jordi Baylina | Devcon Bogotá。
使用ZK proofs对以太坊扩容的基本方法是构建ZK rollup,这是一种Layer 2协议,它“rollup”了大量交易,并使用单个ZK validity proof 向以太坊主网证明了所有交易。
采用ZK rollup实现以太坊扩容的优势明显:
- 1)以单笔交易 代替了 很多笔交易
- 2)增加了交易吞吐量
- 3)节约了手续费
- 4)降低了延迟等待
Polygon Hermez 2.0 zkEVM与以太坊主网EVM兼容。可将以太坊主网的智能合约部署在Polygon zkEVM中,可共用以太坊现有的开发工具和套件。
2. 何为Hermez 2.0?
Hermez 1.0为以太坊第一个去中心化ZK Rollup,于2021年3月上线,可实现2000tps,足以满足ETH及ERC-20 token转账需求。
Hermez 2.0定位为zero-knowledge Ethereum Virtual Machine(zkEVM)—— 可以透明方式运行以太坊交易 并 为智能合约附加zero-knowledge-proof validations。为此,需要重建 透明部署现有以太坊智能合约的所有EVM opcodes。
相比于Hermez 1.0,Hermez 2.0的最主要功能是提供智能合约支持。
Polygon Hermez 2.0总体架构为:
Polygon zkEVM中包含的主要元素有:
- 1)共识算法
- 2)zkNode软件
- 3)zkProver
- 4)LX-to-LY Bridge
- 5)Sequencers和Aggregators(需要这2个角色 以达成网络共识)
- 6)Hermez 2.0网络中的活跃用户,以创建交易
根据Asif Khan 2023年2月10日twitter,上面Polygon zkEVM架构中主要有四大部分组成:
1)zkNode(Synchronizer、Sequencer&Aggregator角色,以及GRPC):客户端可启用Sequencer角色synchronization,或者是,Aggregator角色synchronization。
- 1.1)Synchronizer:负责获取Sequencers所提交的所有数据(transactions) + 获取Aggregators所提交的所有数据(validity proofs)。
- 1.2)Sequencers:以Sequencer模式运行zkEVM节点,可为Trusted或Permissionless模式。
- 1.2.1)Sequencers会:接收L2交易+L2用户支付的交易手续费 -》 对L2交易进行排序 -》生成batches -》 以sequences的形式将batches提交到Consensus Contract的storage slots。
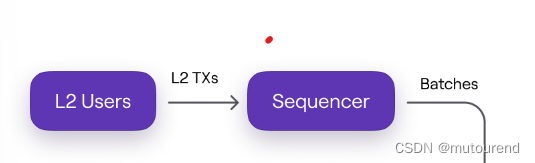
- 1.2.2)Sequencers的经济模型为:向L1提交有效交易,以获利。
- transaction pool中会采用排序算法,选择利润最丰厚的交易进行处理。
- 向L1提交batches时,需以MATIC支付手续费。
- 1.3)Aggregators:以Aggregator模式运行zkEVM节点。
- 1.3.1)Aggregators会:从L1中获取Sequencer提交的L2 batches -》将这些L2 batches发送给zkProver -》生成ZK proof以证明该batch的完整性。
Aggregator会使用特殊的链下EVM解析器来生成ZK proofs。
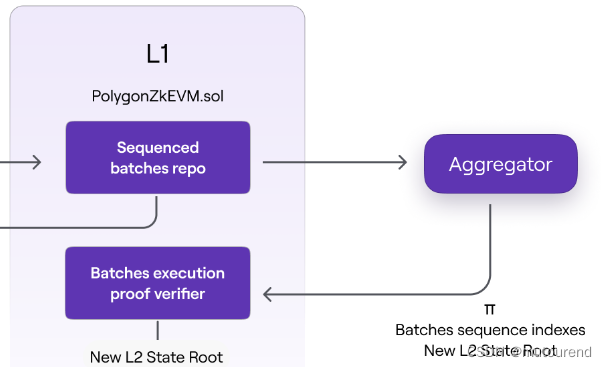
- 1.3.2)Aggregators的经济模型为:
- Sequencers提交L2 batch所支付的MATIC手续费,将给为该batch提供ZK proof的Aggregator。
- 随着需求的增加,所需的MATIC手续费将增加,从而激励Aggregators生成可验证的validity proof
- Aggregators需平衡2方面的成本:向L1提交validity proof交易成本;运行aggregator节点和zkProver服务器成本- 2)Consensus Contract(PolygonZkEVM.sol):会将Sequencers提交的L2 batches存储在PolygonZkEVM.sol合约内,创建a repo of sequences。支持Aggregator公开验证L2 State root的变化。
在向Consensus Contract commit新L2 State root之前,需对validity proof进行验证。verified proof可作为一组batches引起变更到特定L2 State 的不可否认的证据。
3)zkProver:Polygon zkProver是真正的游戏改变者,是区别于其它rollups的关键所在,由Polygon Zero、Polygon Miden、Polygon Hermez共同加持。原因在于:
- 工业级别的生成证明时长最低之一
- 采用zk virtual machine来仿真EVM
Polygon zkEVM中交易的验证和证明均由zkProver处理。zkProver会以多项式和汇编语言形式执行复杂的数学计算,所生成的proof最终在合约内验证。
zkProver有独立的线程,其高性能涉及的因素很多,后续将更新。
- 4)LX-to-LY Bridge:为智能合约,使得用户可在LX与LY层之间进行资产转移。如zkEVM中的(L1-L2)为去中心化bridge,用于安全的存入和取出资产。LX-to-LY Bridge由2个合约组成:
- Bridge L1 Contract:部署在以太坊筑网上,用于管理rollups之间的资产转移。
- Bridge L2 Contract:部署在某特定的rollup上,负责主网与该rollup之间的资产转移
3. Hermez 2.0 共识算法——PoE
Hermez设计为去中心化的,不同于Hermez 1.0中的Proof-of-Donation(PoD)共识算法,Hermez 2.0将采用Proof of Efficiency(PoE)共识算法。
在zk-rollups中实现去中心化共识是充满挑战的,因为在Layer2中PoS共识存在leader选举的一些问题(如无法硬分叉、少量%质押可能引起的攻击——如恶意一直产空块等)。
Hermez 2.0中的节点需要高效生成zk validity proofs(对于prover来说是计算密集型的),使得整个L2层正常工作,将产batch(L2区块)的权利给随机的validator是无法满足该要求的。
Proof of Donation/Proof of Burn(PoD/PoB)是一种去中心化竞价模式,以获得特定时间段的产块权利。此时,需要设置经济激励以使validators是very efficient的 以 具备竞争力,这是一个很大的改进。
但是Proof of Donation/Proof of Burn(PoD/PoB)共识主要存在以下问题:
- 1)对于某个特定时间,网络由单一actor控制,其可能作弊,即使有办法来减轻影响,也无法保证L2 service层不受一丝影响,特别是在bootstrapping阶段。
- 2)对于coordinators/validators来说,竞价协议是昂贵和辅助的,也是当前最有效的激励方式。由于拍卖需要提前一段时间进行竞标,因此很难对它们进行自动化,而且预测的复杂性很高。
- 3)选出”the best“ operator使得”赢家通吃“的问题 。使得稍差性能的运营商无法参与竞争,结果就是,控制网络的运营商变得非常集中,从而产生抗审计限制。
L2 zk-rollup共识算法应满足如下要求:
- 1)无权限访问生产L2批次。
- 2)效率是网络性能的关键。
- 3)避免任何一方的控制。
- 4)防止恶意攻击。
- 5)总的验证工作量与网络中的价值成正比。
Proof-of-Efficiency(PoE)共识算法分2步实现,可由不同的参与者完成:
- 1)第一步的参与者称为Sequencer。sequencer可能是a wallet app、an exchange、或者a game等等。sequencer之间可相互协作,也可不协作。负责将L2的交易打包为batches并添加到L1的PoE智能合约中。
- 2)第二步的参与者称为Aggregator。Aggregator之间是竞争的。负责检查transaction batches的有效性,并提供validity proofs。
为此,PoE智能合约有2个基本的接口:
- 1)sendBatch:用于接收Sequencer的batches
- 2)validateBatch:用于接收Aggregator的validity proof,进行validate batches
PoE智能合约对Sequencer的要求为
- 1)任何运行zkNode(为运行Hermez 2.0 node所必须的软件),均可成为Sequencer。
- 2)每个Sequencer都必须以$Matic token来支付fee,以此来获得创建和提交batches的权利。
- 3)提交了有效batches(由有效交易组成)的Sequencer,受交易请求者(网络用户)支付的手续费激励。
- 4)Sequencer收集L2交易,将其预处理为a new L2 batch,然后将该batch作为a valid L1交易提交到PoE智能合约。
PoE智能合约对Aggregator的要求为:
- 1)Aggregator负责为由Sequencer已提交的L2交易生成validity proof。
- 2)Aggregator除了运行Hermez 2.0 zkNode软件之外,还需要专业的硬件来创建zero-knowledge validity proof。在此称为zkProver。
- 3)第一个为某个batch或某些batches提交validity proof的Aggregator,可赚取Sequencer为其batch支付的Matic费用。
- 4)Aggregator仅需表明其验证交易的意图,并按照其自身的策略来生成validity proof参与竞争。
3.1 PoE共识中的Sequencer
Sequencer负责收集用户的L2交易。
Sequencer在网络中选择并预处理a new L2 batch,然后将所选中的所有L2交易 为data 发送一笔L1 TX。
任何人都可成为Sequencer,这是无需许可的角色,包含了a gateway to the network。
有趣的点在于:
- 对于zk-rollup模式,这些提议的batches会记录在L1交易内;
- 对于Validium模式,这些提议的batches会记录在另一data availability network。
Sequencer提议batches的动机在于:
- 其pool内交易的经济值
- 或 满足用户的要求(Sequencer可要求改变手续费)
为向L1网络提议新batch,Sequencer需要发起一笔包含了所有batch transactions data的L1交易并支付相应的gas费,同时,协议中定义了 其必须存入以$MATIC token支付的额外费用。这样,可激励Sequencer提议有效的batches以及有效的交易。
根据网络负载情况,batch fee将是可变的,可根据protocol合约中的某个参数来计算。
L1交易内的batches,是以CALLDATA形式存在的,将用作L2网络的data availability,且任何新的、无许可的节点都可同步和重构该状态。
一旦L1交易被mined,其中定义的L2 TXs的data availability将按指定顺序执行,从而构建了确定性的new state,网络节点可将其计算为a virtual future state。当该new state 的 valid proof(ZKP)生成并在L1 mined时,该new state即settled了。这就是共识协议的第二步。
3.2 PoE共识中的Aggregator
zk-rollups的主要优势在于,validity proof所提供的交易的快速finality。而PoE中的第二步用于强化这些proof的有效性。
与Sequencer类似,Aggregator也是PoE中任何人都可参与、无需许可的参与方。
第一个为L2 new state 创建validity proof的aggregator即获得了创建validity proof的权利,以及部分交易手续费。
具体为:
- Sequencer提议的batches按其在L1中的顺序排序,且在L1中包含了相应的transaction data。
- PoE智能合约验证第一个validity proof通过后,即接受并更新到a new valid state,该new valid state中可包含一个或多个proposed batches。
aggregator需要自己指定触发proof生成的标准,并基于自己的策略参与竞争。
如,若对于包含了少量TXs的batches,某些aggregator会认为不值得为其生成proof,直到有更多的价值后,才会为N NN个proposed batches生成proof证明相应的状态改变。而另外一些aggregator可能采用不同的策略。
对于提交晚了的proof,智能合约会执行Revert操作。所以,如果不是第一个提交validity proof的aggregator,其损失的生成proof的开销,但是大部分gas费都可收回。
当然,当且仅当aggregator正确处理了proposed batches时(按顺序处理batch内的所有交易),该validity proof才有效。该机制类似于Polygon Hermez v1.0中的 ”Force tx“,有助于避免审查。
这种机制有助于避免L2被单一方控制,以及可避免许多潜在攻击,尽管任何Sequencer都可提议a batch,但是也要承担相应的费用。
而Aggregator也可 以非许可的方式参与进来,因为总会有某个经济价值点,使得有人有兴趣来生成并提交validity proof。
Polygon Hermez网络会启动一个Boot Aggregator backing up,使得在bootstrapping阶段,可 以特定频率来生成new validity proof。
3.3 PoE的经济模型
手续费的分发规则为:
- 1)L2 TXs的手续费将由创建并提交validity proof的aggregator处理并分发。
- 2)所有TX手续费将发送到提交每个batch的相应Sequencer。
- 3)创建a batch的deposited fee 将发送给 将该batch包含在validity proof中的Aggregator。
即:
- Sequencer赚L2的交易手续费,但是只有相应的validity proof提交后,Sequencer才能获得其所提交的batch内的L2交易手续费;
- Sequencer向L1提交batch时,除L1交易手续费之外,还需额外支付一个以MATIC token支付的费用,这笔MATIC token费用将由 提交了该batch对应的validity proof的Aggregator获得。即Aggregator赚取Sequencer支付的batch MATIC手续费。
4. zkNode软件
网络中需发布一个客户端,以实现同步并覆盖参与者角色——如Sequencer或Aggregator。zkNode就是相应的客户端,为运行Hermez 2.0 node所必须的软件。
Hermez 2.0参与者可自行决定其参与方式:
- 1)仅作为一个简单的节点,以获悉网络状态。
- 2)以Sequencer或Aggregator角色参与batch production。
Aggregator除运行zkNode之外,还需要使用zkEVM的核心部分来进行验证。zkEVM的该核心部分称为zkProver(又名Prover)。
Hermez 2.0 zkNode模块化架构流程图为:
上图中的:
- 1)Synchronizer:
除sequencing和validating进程之外,zkNode中还支持对batches和validity proofs的同步,仅在batches和validity proofs提交到L1之后才做相应的同步。该子模块称为Synchronizer。
Synchronizer负责监听以太坊链上事件,包括new batches,以保持state的完全同步。从events中读取的信息必须存储在database中。Synchronizer还必须处理可能的reorgs——通过检查last ethBlockNum 和 last ethBlockHash 是否已同步。
- 2)RPC(remote procedure calls)接口:
为与以太坊兼容的JSON RPC接口。支持将zkEVM与现有工具集成,如Metamask、Etherscan、Infura。RPC向Pool添加交易,通过只读方法与State交互。
- 3)State子模块:
实现了Merkle Tree并连接到DB后台。会:
- 在block level检查integrity(即,关于gas、block size等相关信息),
- 检查某些交易相关信息(如签名、足够的balance等)
- 将smart contract(SC)代码存储到Merkle tree中,并使用EVM来处理交易。
5. zkProver
Hermez 2.0采用了最先进的零知识技术。它将使用一个称为zkProver的零知识验证程序,该程序旨在在任何服务器上运行,并且正在设计为与大多数消费类硬件兼容。
每个Aggregator将使用zkProver来验证batches并提供validity proofs。
Hermez 2.0 zkProver的总体架构为:
zkProver包含了:
- 1)Main State Machine Executor。
- 2)一系列secondary State Machines,每个secondary State Machine有其自己的executor。
- 3)STARK-proof builder
- 4)SNARK-proof builder
简而言之,zkEVM以多项式形式表示状态变化。因此,每个proposed batches必须满足的约束实际上是多项式约束或多项式恒等式。也就是说,所有有效batches必须满足某些多项式约束。
zkProver的简化数据流为:
5.1 zkProver的Main State Machine Executor
Main Executor负责处理zkEVM的执行,会:
- 使用一种Polygon团队特意开发的新的zero-knowledge Assembly language(zkASM)来解析EVM Bytecodes。
- 会设置多项式约束,要求每个有效的transaction batch都必须满足相应的多项式约束条件。
- 使用另一种Polygon团队开发的Polynomial Identity Language(PIL)来对多项式约束进行编码。
5.2 zkProver的一系列secondary State Machines
zkEVM中证明交易正确性的每一步计算都是一个state machine。
zkProver是整个项目中最复杂的部分,包含了多个state machines:
- 一些执行bitwise function的state machines(如XOR/Padding等等)
- 执行哈希运算的的state machines(如Keccak、Poseidon等等)
- 执行验签的state machines(如ECDSA等等)
因此,二级状态机的集合是指zkProver中所有状态机的集合。它本身不是一个子组件,而是单个二级状态机的各种执行器的集合。具体的二级状态机有:
- Binary SM
- Memory SM
- Storage SM
- Poseidon SM
- Keccak SM
- Arithmetic SM
根据每个SM负责的具体操作,一些SM同时使用zkASM和PIL,而另一些SM仅使用一种。
Hermez 2.0 state machines之间的依赖关系为:
5.3 zkProver的STARK-proof builder
STARK,为Scalable Transparent ARgument of Knowledge的简称,是一种无需可信设置的proof system。
STARK-proof builder负责生成zero-knowledge STARK-proofs,以证明所有的多项式约束条件都满足。
State machines负责生成多项式约束。
zk-STARKs用于证明batches满足这些多项式约束条件。特别地,zkProver使用Fast Reed-Solomon Interactive Oracle Proofs of Proximity(RS-IOPP),俗称为FRI,来对zk-STARK证明加速。
5.4 zkProver的SNARK-proof builder
SNARK,为Succinct Non-interactive ARgument of Knowledge的简称,是一种proof system。
由于STARK-proof的size要大于SNARK-proof的size,Hermez 2.0 zkProver使用SNARK-proof来证明STARK-proof的正确性。结果是,将SNARK-proof做为validity proof,使得可更便宜地在L1上验证该validity proof。
目标是生成CIRCOM circuit,将CIRCOM circuit用于生成SNARK proof 或 用于验证SNARK proof。
最终是采用PLONK SNARK proof还是GROUTH16 SNARK proof还暂未确定。
6. LX-to-LY Bridge
典型的Bridge智能合约由2个智能合约组成,一个智能合约部署在链A,另一个部署在链B。
Hermez 2.0的L2-to-L1 Bridge智能合约也是由2个合约组成:
- Bridge L1 Contract:部署在以太坊主网,用于管理rollups之间的资产转移。
- Bridge L2 Contract:部署在某个特定的rollup,负责主网与该rollup之间的资产转移。
除了部署位置不同外,这两个合约实际上是相同的。
通常Bridge智能合约是L2-to-L1 Bridge,但是Hermez 2.0 Bridge更灵活且可互操作。可作为任意2个L2链(L2_A和L2_B)之间的bridge,或者任意L2(如L2_X)与L1(如以太坊)之间的bridge。从而支持资产在多个rollups之间转移,从而将其命名为"LX-to-LY Bridge"。
6.1 Bridge L1 Contract
Bridge L1 Contract负责2个操作:
- 1)bridge:将资产由一个rollup转移到另一个rollup。
- 2)claim:当合约从任意rollup claim时,使用claim操作。
为满足以上2种操作,Bridge L1 Contract需要有2棵Merkle tree:
- 1)globalExitTree:包括了所有rollups的exit trees的所有信息。
- 2)mainnet exit tree:包含了用户与主网交互的交易信息。
名为global exit root manager L1的合约负责管理跨越多个网络的exit roots。
exit tree结构为:
6.2 Bridge L2 Contract
Bridge L2 Contract部署在L2 with Ether on it。将Ether设置在genesis上是为了实现native Ether的mint或burn。
Bridge L2 Contract还需要包含在globalExitTree Merkle Tree内的所有rollups的exits trees的所有信息。此时,一个名为global exit root manager L2的合约负责管理跨越多个网络的exit roots。
注意,当某batch在L1 PoE智能合约内验证通过后,global exit root manager L1内相应的rollup exit root将更新。
Bridge L2 Contract负责:
- 处理rollup端的bridge和claim操作
- 与globalExitTree和rollup exit tree交互以更新exit roots
7. Hermez 2.0设计思想
以上为达成Hermez 2.0设计思想的工程化实现。
Hermez 2.0的设计思想为:
- 1)Permissionless-ness:任何人只要运行Hermez 2.0软件即可参与到网络中。共识算法支持每个人选择成为Sequencer或Aggregator。
- 2)Decentralized(Data availability):data availability对于实现去中心化来说是最至关重要的,使得每个用户都有足够的数据,以重构出某rollup的所有状态。如上所述,Polygon团队仍在探索最优的data availability配置。目标是保证没有censorship,也没有任何一方可控制网络。
- 3)Security:作为L2解决方案,Hermez 2.0的大部分安全性继承自以太坊。
- 4)Efficient and with verifiable block data:智能合约将保证任何执行状态更改的人必须:首先,正确地做;其次,创建证明状态更改有效性的proof;第三,在链上对validity proof进行验证。
8. 效率及总体策略
效率是网络性能的关键。Hermez 2.0采用了多个实现策略来保证效率:
- 1)第一个策略为:部署PoE,以激励效率最高的aggregator参与到生成proof的进程中。
- 2)第二个策略为:将所有计算链下执行,仅在链上保持必要的data和zk-proofs。
在Hermez 2.0系统的特定组件内还实现了多种其它策略,如:
- 1)Bridge smart contract内实现了:以UTXO模式来settle accounts,仅使用the Exit Tree Roots。
2)在zkProver中使用专门的密码学原语 来加速计算 并 使proof size最小化:
- 2.1)运行一种特殊的zero-knowledge Assembly language(zkASM)来解析字节码;
- 2.2)使用零知识证明工具如zk-STARKs——证明速度快但proof size巨大,因此,相比于将庞大的zk-STARK proof作为validity proof,替换为,用a zk-SNARK来证明zk-STARK proof的正确性,将zk-SNARK proof作为state changes的validity proof,可将验证validity proof的gas开销由500万降低为35万。
参考资料
[1] 2022年5月博客 Polygon ZK: Deep Dive Into Polygon Hermez 2.0
[2] 2022年7月博客 The Future is Now for Ethereum Scaling: Introducing Polygon zkEVM
转载自:https://blog.csdn.net/mutourend/article/details/126034757