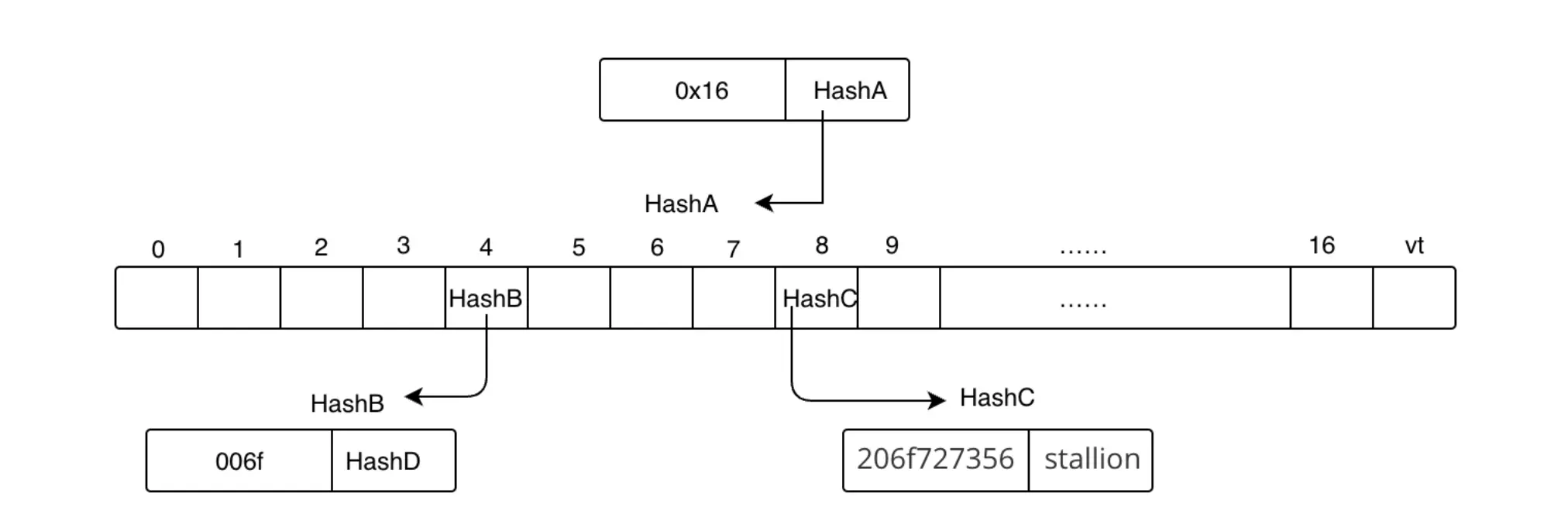
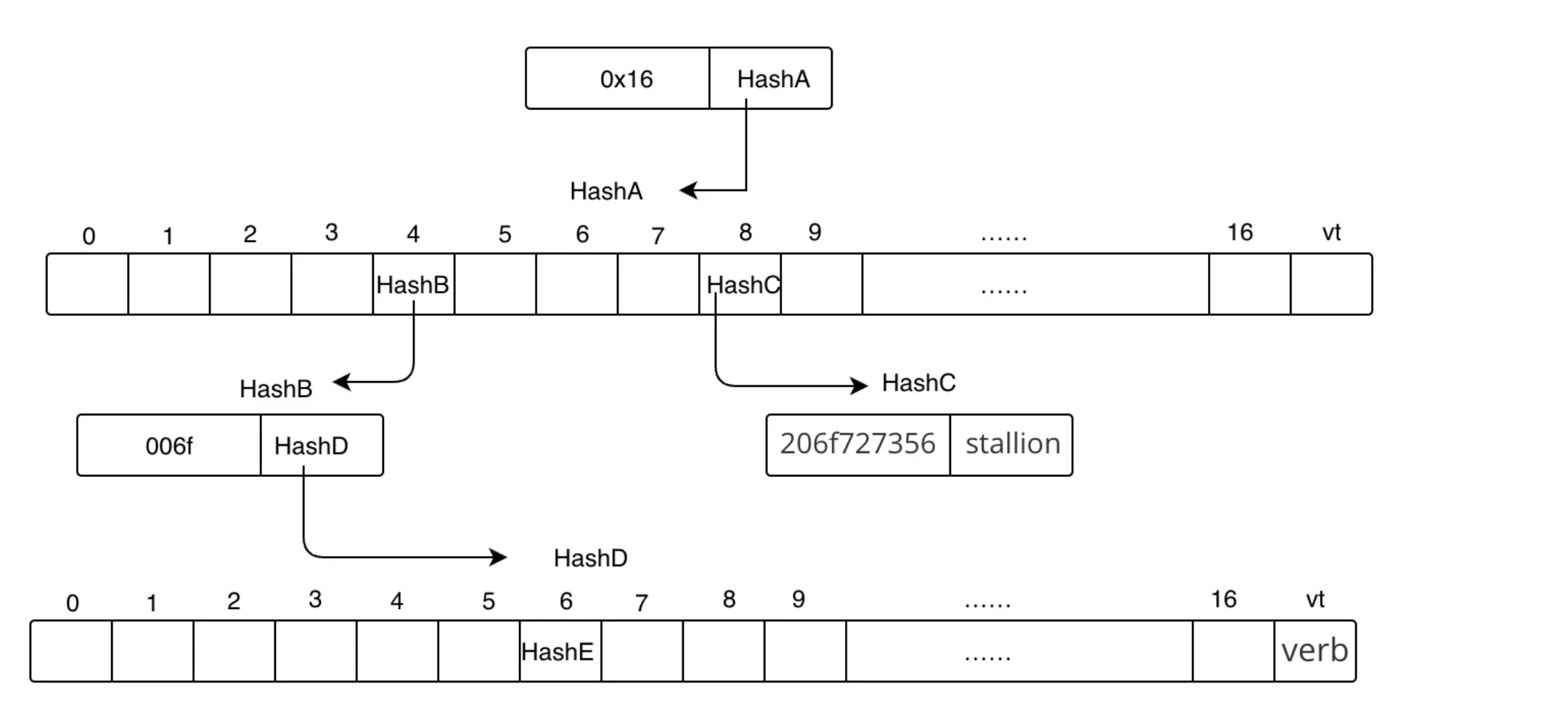
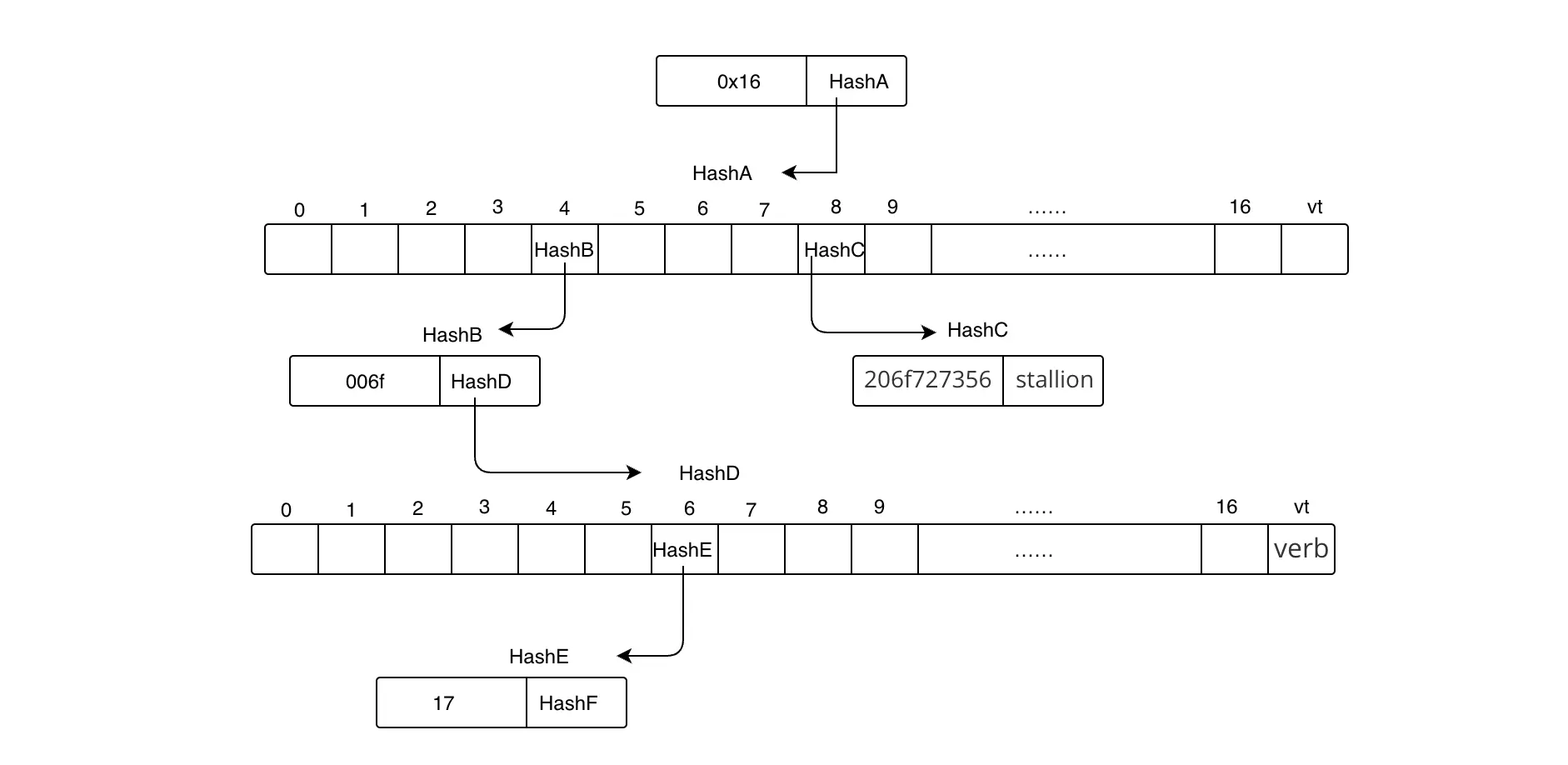
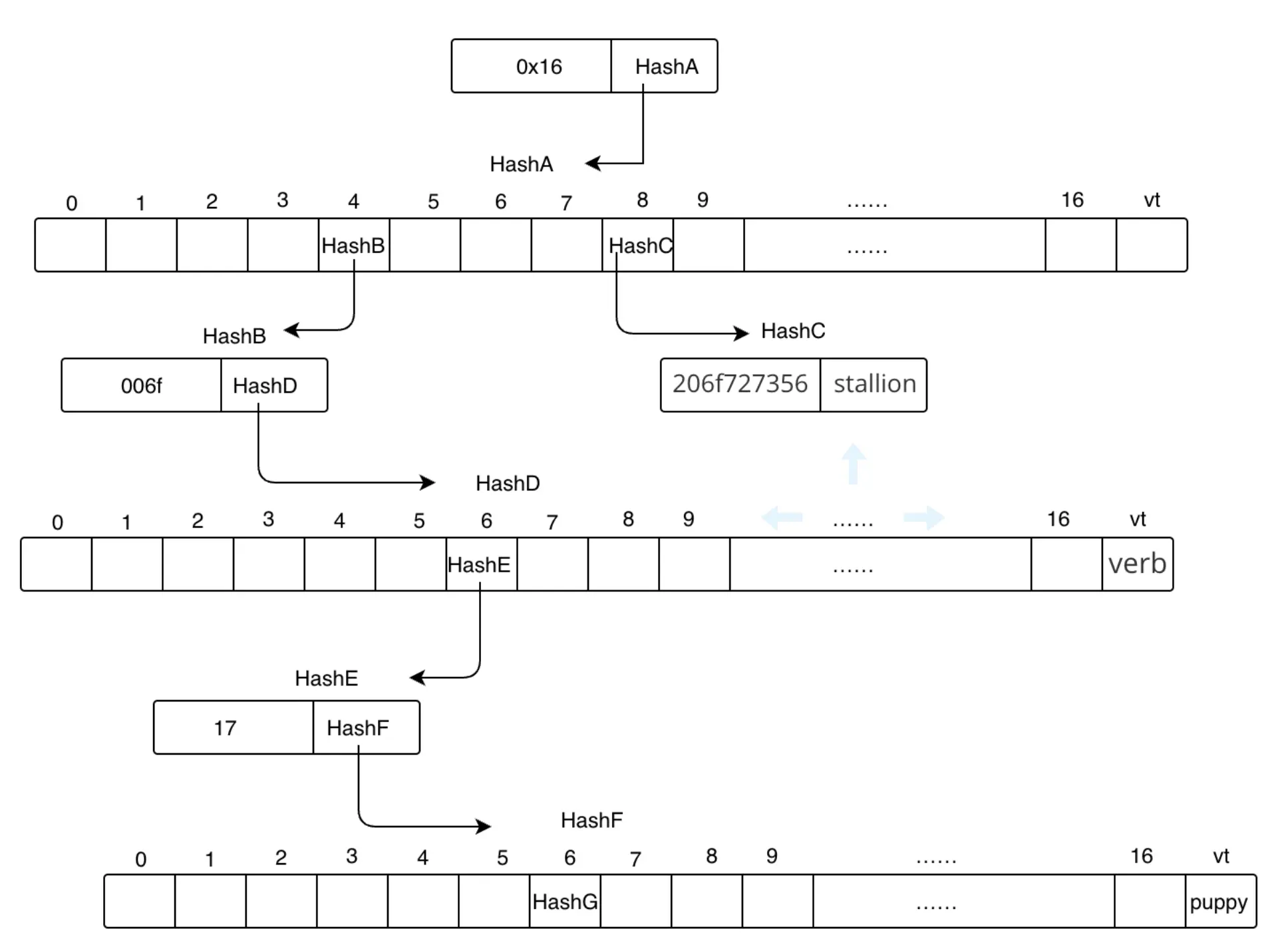
什么是Uniswap?
uniswap是一个进行自动化做市商的项目,该项目的特点是公平,去中心,抗审查,安全。并且uniswap并不会存在特殊群体,参与项目的每个人都是平等的不论你是LP还是Trader。
V1的特点:
- 支持不同的ERC20token进行交换
- 可以加入流动矿池成为LP并获取奖励费用
- 利用公式进行自动定价,每次交易过后都会进行计算定价
- 支持私人定制的交换
每个LP按照一定比例输入ERC20-ERC20的数量之后,会获得一定数量LPtoken,用来表示贡献度,可以根据贡献度来领取池中的奖励(奖励的来源为每次交易收取的费用)。如果想退出的话,可以将LPtoken进行销毁,销毁后会按照LPtoken的比例将两种资金进行返回。
同时可以设置限价单和限时单。
Uniswap如何进行计算
无交易费推导
在整个计算过程中uniswap使用的是x-y-k的模型,即为无论怎样进行交易,保持交易后x * y = k,两种代币的乘积不变。根据这个思想,进行推导
设要用Δx数量的x代币交换Δy代币,则有
(x + Δx) * (y - Δy) = k = x * y
设 α = Δx / x, β = Δy / y,将其代入上式可得
∴ (x + α * x) * (y - β * y) = x * y
∴ (1 + α) * (1 - β) = 1
∴ α = β / (1 - β), β = α / (1 + α)
∴ Δy = α / (1 + α) * y = Δx / (x + Δx) * y
Δx = β / (1 - β) * x = Δy / (y - Δy) * x带手续费交易
在实际情况中,每一次交易都会收取一定的手续费用来交易LP,通常手续费为交易量的0.3%,这就表明你输入的Δx并不是全用于计算,实际的计算值为Δx * 0.97%,剩下的作为手续费放入交易池中奖励LP,下面是实际的推导过程:
设要用Δx数量的x代币交换Δy代币,则有
设手续费的比例为ρ, 1 - ρ为γ
(x + Δx * γ) * (y - Δy) = k = x * y
设 α = Δx / x, β = Δy / y,将其代入上式可得
∴ (x + α * x * γ) * (y - β * y) = x * y
∴ (1 + α * γ) * (1 - β) = 1
∴ α = β / ((1 - β) * γ), β = (α * γ) / (1 + α * γ)
∴ Δy = (α * γ / (1 + α * γ)) * y = ((Δx * γ) / (x + Δx * γ)) * y
Δx = β / (1 - β) * x = Δy / (y - Δy) * (1 / γ) * x
//我们假设ρ = 0.3%,所以γ = 997 / 1000
∴ 上述结果可以表示为:
Δy = (997 * Δx * y) / (1000 * x + 997 * Δx)
Δx = (1000 * Δy * x) / ((y - Δy) * 997))通过上面推导可以看出当ρ为0时就成为了无手续费模式,并且可以发现一个问题,代入手续费之后整个池子的k只会略微变大,这是因为会有部分的费用作为手续费进入池子并不会进入交易当中。也可以理解为,你输入的Δx = 手续费 + 实际的交易的数量
在实际的交易中,会出现以下两种情况:
- 给出交易的x代币数量,计算出y代币的数量
在这种情况下,输入的x代币会有一部分作为手续费放入池中,其余部分才会被用来做交换。计算时可参考上面手续费交易的结果。 - 给出想要的y代币数量,计算出所需要的x代币数量
给出想要获取的y代币,计算所需的x代币数量,同时x代币中包含了手续费和实际交换数量。计算时可参考上面手续费交易的结果。
流动性计算
用户不仅可以进行代币的交换,同时还可以成为LP(Liquidity provider),获取LPtoken用来获取池子中的利息。流动性计算的推导如下
设l = x * y表示两种代币的数量,则有
//提供流动性推导
设α = Δx / x,则有
∴ Δy = Δx / x * y + 1
Δl = Δx / x * y
∴ x' = x + Δx
y' = y + Δx * t / x + 1 //这是考虑到solidity语法在计算时的小数会进行向下取整
l' = l + Δx * l / x
//取消流动性
设β = Δl / l
∴ Δx = Δl * x / l
Δy = Δl * y / l
∴ x' = x - Δx
y' = y - Δy
l' = l - Δl由于存在向下取整的计算方式,我们将提供和取消两种结合起来看之后会发现,在取消之后剩余的x,y的数量大于提供流动性之前,这是为了保证避免投资者通过这种方式进行获利。如果不使用向下取整的计算方式的话,其实提供和取消之后x,y的数量不会发生变化。同时在提供流动性之后,LP会获取LPtoken,LPtoken数量等于两种代币之积(代币数量更新之后)再开根号。
滑点问题
由于Uniswap是在区块链上的操作,所以可能会导致你看到的价格和实际的价格会有所不同,这是由于交易的确认需要时间,并且交易的顺序不清楚。这样就会导致产生交易滑点,通常为0.5%的滑点保护。而对于滑点的计算我们通常使用(实际成交价格 - 交易时输入的价格) / 交易时输入的价格。当计算出的值满足设定的比例时,即可完成交易。
手续费问题
由于在每笔交易时都会收取一定的手续费,这些手续费会按照LP的持有的token的比例进行分发。这是为了激励用户成为LP并且投入更多的资金,创造更多的流动性。从理论上来说当每一一笔交易发生的时候要将手续费分发给LP,在进行分发的时候可能会使用一个大循环进行分配。但是在实际中这样对用户消耗的gas是很多的,所以这样的方法是不可行的。所以在代码中将手续费的分配放在LP提供流动性和移除流动性的部分,并且维持手续费公平分配的与那里很简单。每次用户进行交易的时候交易的手续费会将每单位的LPtoken的代币的价值提高,而LP在提供流动性的时候会按照当前每单位的LPtoken的代币的价值进行买入LPtoken(变相地理解),举例说明:用户A提供流动性的时候获取了100LPtoken,池子中有1000tokenA,1000tokenB,这时候1LPtoken的价值分别是10tokenA和10tokenB,在经过多次买卖后池子里面有1100tokenA和1500tokenB,这时候1LPtoken对应11tokenA和15tokenB,多出来的这部分即为手续费收益。当用户B想要增加流动性的时候,会按照1LPtoken对应11tokenA和15tokenB的比例进行生成LPtoken,然后按照上面所说的再进行手续费的收益。
质押性挖矿
质押挖矿,在项目中LP可以通过质押自己的LPtoken通过质押一定的时间可以获取质押合约中的奖励代币。再uniswap中LP可以质押自己的LPtoken去获取UNI代币,获取的UNI代币可以去交易所兑换其他的代币,也可以用于参与uniswap的治理,可以通过持有的UNI数量进行投票。
质押挖矿的算法推导
在质押挖矿合约中会进行规定每经过一段时间就会生成一定数量的奖励代币,并且将这些奖励代币按照LP质押的token的数量进行分配给LP。正常思路下我们在分配的时候,会采用循环将质押的用户进行遍历分配。但是在智能合约中使用循环便利的话会消耗大量的gas,这样是不明智的。所以我们要换一种思路来进行奖励的分配。
我们假设质押合约中每秒的奖励为R,合约中质押的代币总数为T,用户A的质押代币数量为a,T包含a
∴ 每秒每一代币的奖励数量为R / T, 用户A每秒获取的代币数量为 a * R / T
我们假设用户A在6秒后取出质押的代币
∴ A所获得的奖励代币数量为:a * R / T * 6
我们再假设B用户在A用户质押4秒后质押了b数量的代币
∴ A所获得的奖励代币数量为:
a * R / T * 4 + a * R / (T + b) * 2 = a * (R / T + R / T + R / T + R / T + R / (T + b) + R / (T + b))
按照这种思路,我们再进行假设
假设质押的总时长为6秒,A用户在第2秒质押a数量代币,B用户在第4秒质押b数量代币,A用户质押前的代币总数为T'
∴ A所获得的奖励代币数量为:
a * R / T * 2 + a * R / (T + b) * 2 = a * (R / T + R / T + R / (T + b) + R / (T + b)) = a * (R / T' + R / T' + R / T + R / T + R / (T + b) + R / (T + b)) - a * (R / T' + R / T')通过最终的推导式,我们可以得到用户A获得的奖励代币数量等于结算时的累计每份质押代币对应的奖励代币数量之和减去加入时累计每份质押代币对应的奖励代币数量之和再乘以A代币的数量。这样计算的前提是用户A的质押代币的数量不会进行更改,那么问题来了,如果用户对质押代币的数量进行更改了,如何进行计算呢?
其实解决方法很简单,在每次更改数量的时候,对先前数量的质押代币获取的奖励进行结算,然后将变换后的质押代币数量重新进行上述的数量不变的推导。这就是uniswap质押合约代码的逻辑结构,详细的代码可以参考https://github.com/Uniswap/liquidity-staker
问题
- 质押挖矿的算法推导是不存在问题的,但是在使用时要结合实际情况来进行考虑。由于solidity中对于除法计算使用的是向下取整,所以在上述推导公式中对于每份质押代币对应的奖励代币数量的计算可能会出现结果为0的情况,虽然uniswap的代码中将每秒奖励的数量扩大10**18倍,但是还要考虑扩大之后如果还是小于总的质押代币数量,这个时候可能会出现用户在这段时间的收益为0的情况。这是由于语言特性产生的bug问题。
- 也要考虑额质押代币数量为0的情况,此时计算收益会出现问题。