一、介绍
有人把Tendermint当成一个共识,有人把它当成一个通信组件。这都是可以理解的。Tendermint融合了共识和网络通信部分。它类似于一个软件包,通过使用Tendermint可以很容易的开发一个和Cosmos相兼容的区块链(当然,如果使用Cosmos-sdk会更简单,但是会屏蔽更多的细节)。可以把它理解成Cosmos的一个底层架构,提供类似于基础服务的一个平台。Tendermint可以提供一个Cosmos标准的跨链的基础应用。
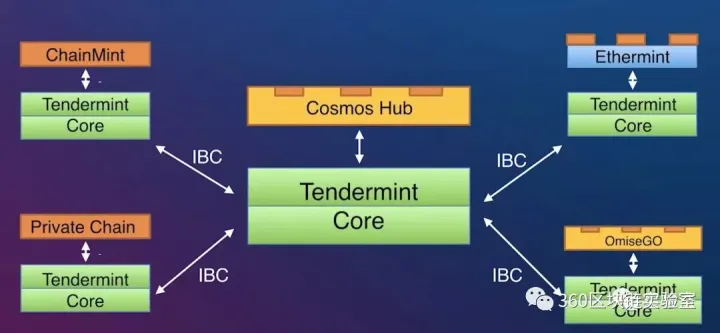
通过上面这个图可以看出Tendermint在整个Cosmos生态中的位置。Tendermint Core是所有Cosmos生态中区块链的核心(上图中的淡绿色部分),提供了DPOS+BFT的共识机制。Cosmos Hub提供了不同区块链的之间的交互和价值转移。各个区块链应用之间通过IBC接口进行通信。
二、整体架构
1、BFT
Tendermint使用的共识算法是拜占庭容错共识协议,它是来源于DLS共识算法。使用这种算法的目的是可以简单方便的解决区块链的分叉机制。这种BFT的机制要求有固定的一组验证人,然后他们会尝试在某个区块上达成共识。每个区块的共识轮流进行,每一轮都有一个提议者来发起区块,之后由验证人来决定是否接受区块或者进入下一轮投票。
Tendermint采用由绝对多数的选票(三分之二)待定的最优拜占庭算法。因此它可以确定的做到:
如果想做恶,必须要有三分之一以上的选票出现问题,并且提交了两个值。
如果任何验证组引起安全问题,就会被发现并对冲突进行投票,同时广播有问题的那些选票。
因为使用了BFT,所以其共识的速度在所有的共识中最相当快速的,很容易达到并维持每秒千笔交易的速度。
2、P2P
Tendermint中的网络底层通信,使用的是一种普通的反应器,它通过参数来查找需要连接的P2P节点,在Tendermint的节点连接中,维护着两组映射来管理连接自己和自己连接的对象,分别称做inbound,outbound.
outbound中,有两种连接,一种是连接时指定的seed,一种是在初始化时检测出来的节点。一般情况下,outbound的数量少于10个。而inbound控制在50个左右的连接。
既然是基于反应器的,那么编程的复杂性就大大降低了。只需要服务监听就可以了。这里不再细节赘述网络通信部分。
网络在启动时,会启动一个协程,定时轮询outbound的数量,来控制连接的稳定性。
3、架构
Tendermint的设计目的是为了创建一个统一的区块链开发的基础组件。通过将区块链中主要的P2P和共识抽象出来,实现区块链开发过程中的组件式管理。这样做的优势有以下几点:
一个是代码重用。对通用的网络通信和共识就不必再重复的造轮子。
二是解放了区块链编程的语言。比如以太坊用go,c++,但是通过Tendermint的抽象后,可以使用任何语言(觉得和当初JAVA才提出时一次编译的想法有些相似啊)。特别是对于智能合约,这个优点就更显得明显了。
4、Tendermint的共识过程
Tendermint共识机制中通过作验证人(Validators)来对区块达成共识,这个在前面已经介绍过,一组验证人负责对每一轮的新区块进行提议和投票。整个共识达成的过程如下图所示。
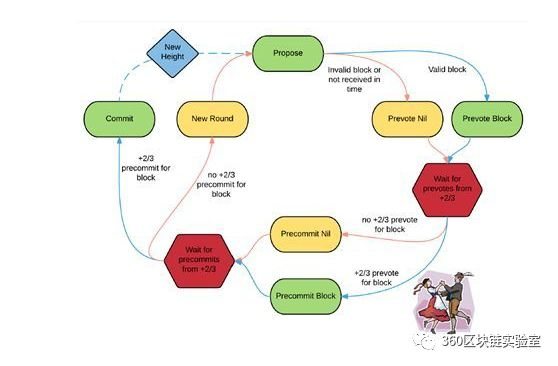
每一轮的开始(New Round),节点对新一轮的区块进行提议。之后,合格的提议区块首先经过一轮预投票(Prevote)。在提议区块获得2/3以上的投票后,进入下一轮的预认可(Precommit),同样是待获得2/3以上的验证人预认可后,被提议区块就正式获得了认可(Commit)。而得到认可的这个区块就被添加的到区块链中。
下面为详细的过程:

在Tendermint算法中,如果遇到对同一特定区块的同意及否决信息同时超过2/3的情况,需要启用外部的维护机制去核查是否存在超过1/3的验证节点伪造签名或者投出双重选票。
5、Tendermint的交易流程
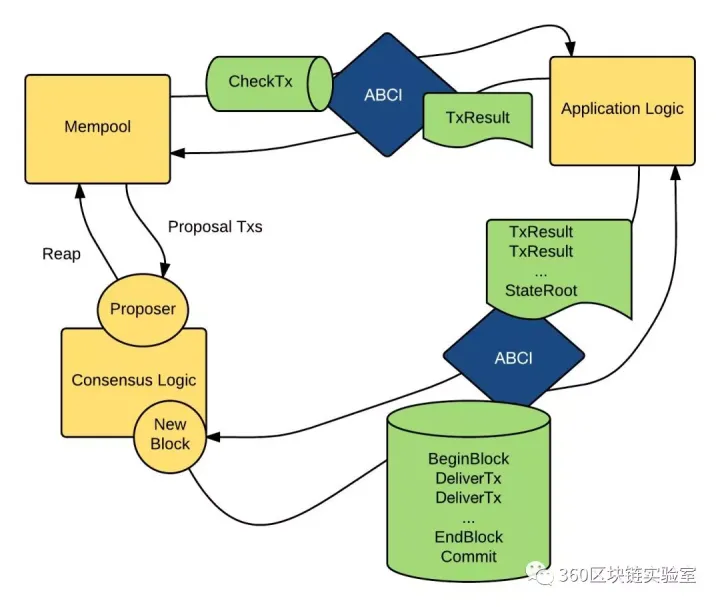
当一个Tx进来时, Tmcore的mempool(MP)会通过mempool connection(一个socket连接,由abci-server提供)调用Application Logic(AL:也就是abci-app,我们自己用任何语言编写的APP逻辑)里的checkTx方法,AL向MP返回验证结果。MP根据验证结果通过或者拒绝该Tx。
Tendermint(TM)把tx暂存在内存池(mempool)里,并把这条Tx通过P2P网络复制给其它TM节点。TM发起了对这条Tx的拜占庭共识投票,所有Tendermint节点都参与了。投票过程分三轮,第一轮预投票(PreVote),超过2/3认可后进入第二轮预提交(PreCommit),超过2/3认可后进入最后一轮正式提交(Commit)
TM提交Tx时依次通过Consensus Connection(一个socket连接,由abci-server提供)向ABCI-APP发送指令BeginBlock-->多次DeliverTx-->EndBlock-->Commit,提交成功后会将StateRoot(application Merkle root hash)返回给TM,TM New出一个区块。
如下图所示的交易流程图:
三、总结
通过上面的分析可以看到,其实Tendermint的重点在于共识和P2P,将二者抽象出来的有利之处在于,可以让开发者忽略对网络通信和共识的复杂性。直接进行业务层面的开发,而SDK的封装,进一步减少了业务上对非相关的逻辑的考虑,大大减少了开发者生产一条区块链的复杂度,而这也恰恰是Tendermint和cosmos-sdk所想达到的目的。