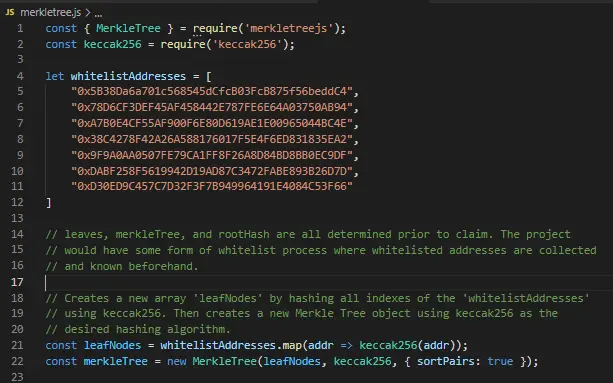
0.简介
在这个系列的教程中,我们将学习如何调试和逆向 EVM 智能合约。
你可能已经知道,当一个智能合约在区块链中没有被验证时,你无法读取它的实体代码,只有字节代码被显示。
问题是很难从字节码中完全 "反编译(de-compile)",以重建编译前的solidity代码。
但是不用担心,在这一系列的教程中,我将清楚地教你所有的技术,以逆向区块链中的任何智能合约。
与不知道的人相比,学习这项技术有几个好处:
你将能够阅读不透明的智能合约(即使源代码没有被验证)。
你会对EVM有深刻的理解,从而成为一个更好的开发者/智能合约审计。(从而赚更多的钱:))。
你会在你的智能合约中更有效地调试代码,避免在出现错误时浪费大量的时间。(特别是如果顶层错误是通用的,如:"执行被回退(Execution reverted)")
本文是关于通过逆向和调试理解EVM系列的第1篇,本系列包含 7 篇文章:
1. 简介
下面是我们将进行逆向/调试的智能合约:
// SPDX-License-Identifier: UNLICENSED
pragma solidity ^0.8.0;
contract Test {
function test() external { }
function test2() external { }
function test3() external { }
}
看上去很简单,对吗?
是的,我们就从简单合约开始。
-
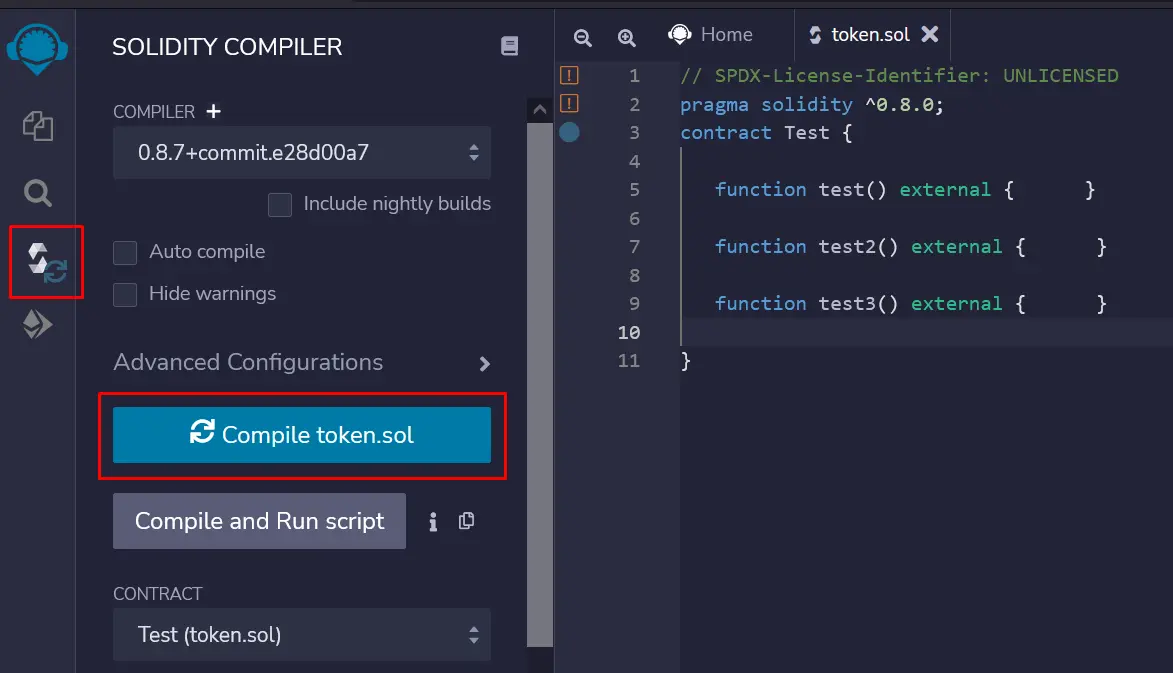
在Remix IDE中编译(0.8.7版) https://remix.ethereum.org
-
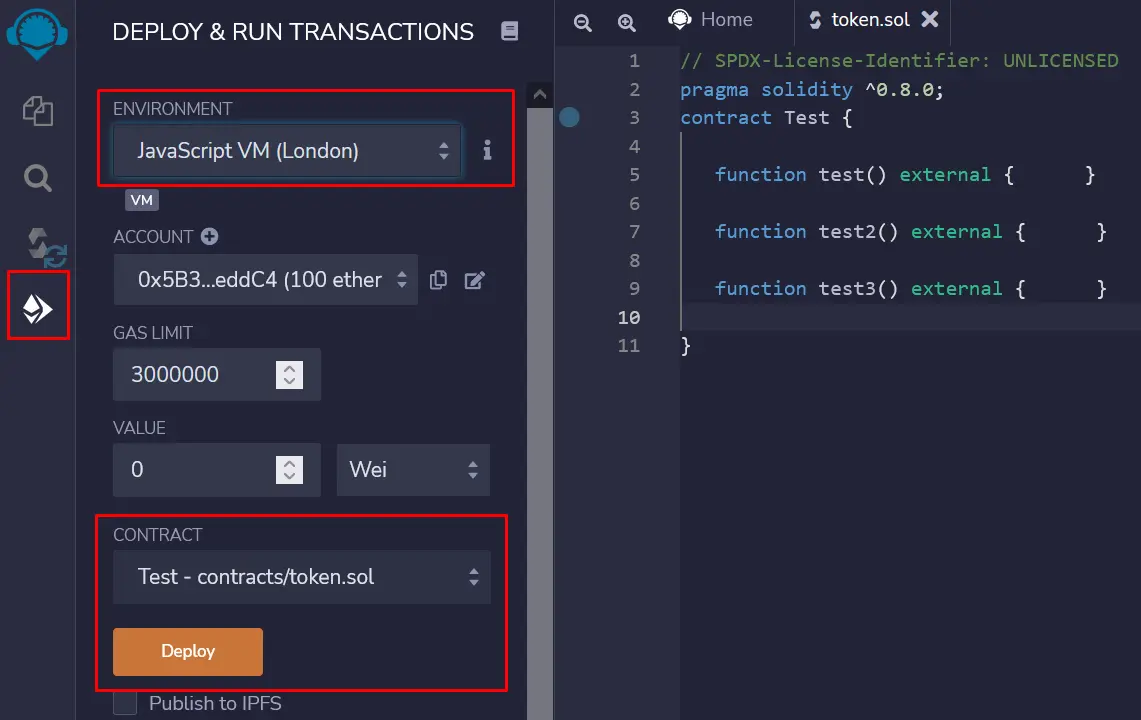
部署(选择JavaScript London虚拟机)
-
调用 test() 函数并点击蓝色的调试按钮,以显示调试器。
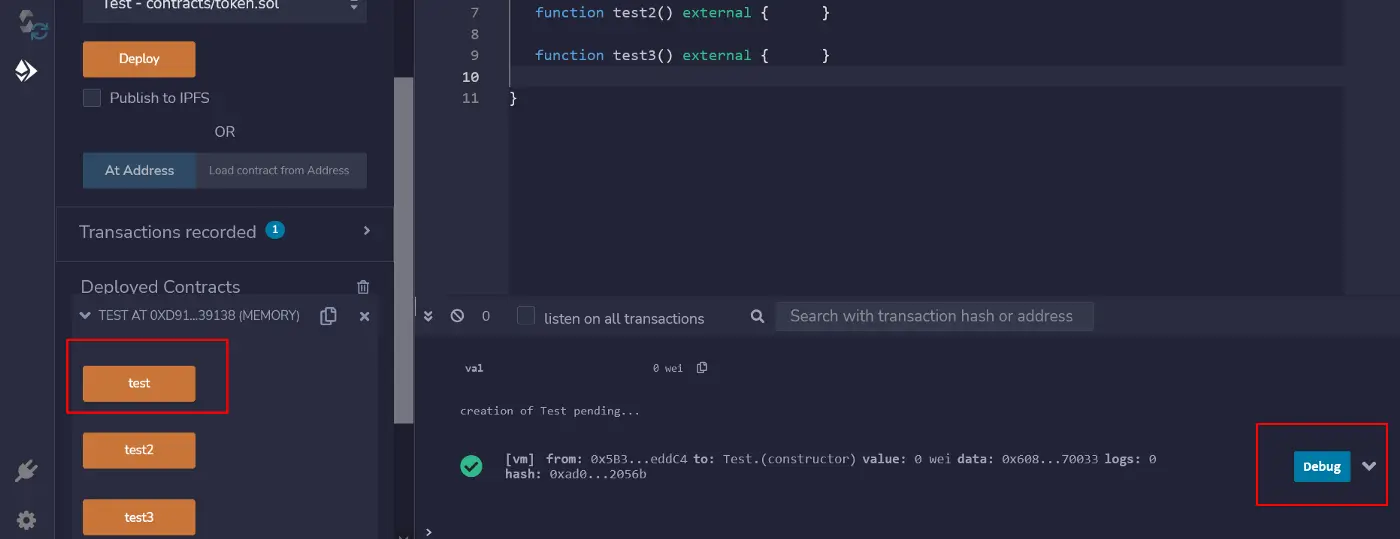
-
一旦完成,你应该在Remix中看到调试标签。
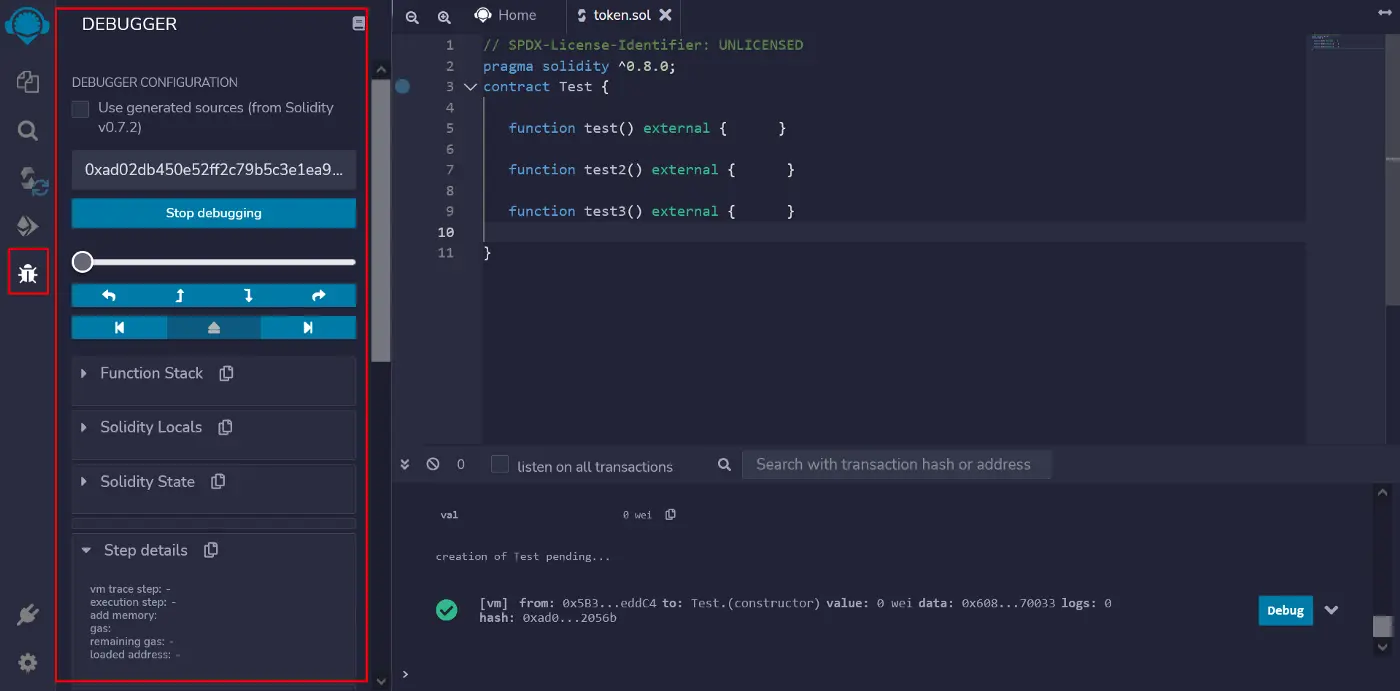
我们90%的工作将在这里进行。
在深入研究这个问题之前,这里有一些前备知识,你需要了解:
- 一些solidity开发经验
- 十六进制数字和基本的计算机科学知识
- Remix IDE的基础知识。
- 兴趣和可能(很多)的咖啡。
2. 什么是字节码/汇编?
每个智能合约都是由字节码构成的,例如,这是我们在文章开头创建的智能合约的字节码(十六进制):
0x6080604052348015600f57600080fd5b5060043610603c5760003560e01c80630a8e8e0114604157806366e41cb7146049578063f8a8fd6d146051575b600080fd5b60476059565b005b604f605b565b005b6057605d565b005b565b565b56fea2646970667358221220d28f98515dc0855e1c6f5aa3747ff775f1b8ab6545f14c70641ff9af67c2465164736f6c63430008070033
这个字节码的每一个字节都对应着汇编语言中的一条指令。你可能已经知道,EVM并不直接理解solidity语言,它只理解汇编中的指令,这是一种低级语言。
在编译的时候,编译的作用只是把 solidity 代码翻译成汇编代码。
汇编是一种非常原始的 "语言",只有指令和参数, 例如:
000 PUSH 80
041 PUSH1 00
056 DUP1
智能合约中第00字节(第一个指令)的指令是PUSH 80(在字节码操作码中翻译为6080)。
第41字节的指令是PUSH1 00(并且有1个参数是00)(在字节码操作码中是6000)。
第56字节的指令是DUP1 没有参数(字节码操作码为80)。
在后面,我们将逐步解释这些指令的内部作用。
在EVM中,大约有100条有效指令,有些是很容易猜到其含义,比如:
- ADD/SUB/OR/XOR
- 但其他的则需要更多的解释。
提示。每次有不明白的指令,你可以去https://www.ethervm.io/,这个网站总结了所有以太坊指令,显示了参数和返回值。
3. Solidity中的存储
你可能已经知道,在solidity中有3种类型的存储。
solidity中有3种类型的存储。
- 存储(storage),直接存储在区块链中,使用32字节数字 "槽(slot)"来标识,。一个槽的大小是32个字节(或64个十六进制数字)。
- "内存(memory)",在智能合约执行结束时被清除,由一个名为 "十六进制数字 "的地址来标识。
- 还有栈,它是一个LIFO(后进先出)类型的队列,当每个项由一个数字标识(以0开始)。
4. LIFO栈是如何工作的?
默认情况下,在智能合约开始的时候,堆栈是空的,它包含的内容是不存在的!
现在有2种方法可以操作堆栈,可以通过使用指令PUSH或POP。
4.1 PUSH
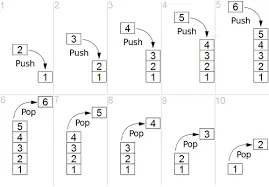
它将数据推在第0位,并将每个数据往前推1个位置。例如,如果我们使用PUSH指令在堆栈中写入0xff。
Stack before (3 elems): |Place 0: 0x50|Place 1: 0x17|Place 2: 0x05|
----------------------------
Stack after PUSH ff: |Place 0: 0xff|Place 1: 0x50|Place 2: 0x17|Place 3: 0x05|
0xff被写在0位,0x50从0位到1位,0x17从1位到2位,0x05从2位到3位,现在栈包含4个元素而不是3个。
让我们看看另一个例子:
Stack before (0 elems, empty): ||
----------------------------
Stack after PUSH 33: |Place 0: 0x33|
堆栈现在包含1个元素。最后一个例子:
Stack before (0 elems, empty): |Place 0: 0x33|
----------------------------
Stack after PUSH 00: |Place 0: 0x00|Place 1: 0x33|
堆栈现在包含2个元素,就像这样简单。
4.2 POP
POP指令,做逆向操作:弹出第0槽中的数据,并将每个数据向后推1槽。
Stack before (3 elems): |Place 0: 0x50|Place 1: 0x17|Place 2: 0x05|
----------------------------
Stack after POP (2 elems): |Place 0: 0x17|Place 1: 0x05|
第0位的数据被删除了,0x17的位置从1位变成了0位,同样,0x05的位置从2位变成了1位。栈现在包含2个元素
下面是另一个例子:
Stack before (1 elems): |Place 0: 0x33|
----------------------------
Stack before POP (0 elems, empty): ||
如果你理解了这一点,也就这么简单。你理解了LIFO类型的存储,你就可以更进一步了:)
在EVM(以及其他汇编)中,堆栈通常用于存储函数和指令的参数 + 返回值。
在这个系列的文章中,我们将使用以下表示:
- Stack(0) = 堆栈中的第一个值(在位置0)。
- Stack(1) = 堆栈中的第二个值(在位置1处)。
- Stack(n) =堆栈中的第n+1个值(在位置n处)。
每次我解释一条指令时,堆栈的内容以这种格式: |0x15|0x25|0x00| , 这里:
- 0x15是Stack(0),是堆栈中的第一个值,位置为0
- 0x25是Stack(1),是Stack的第二个值
- 0x00是Stack(2)。
- 以此类推,如果堆栈里有更多的值的话
5. 汇编的第一行
一旦你理解了这些概念,现在就可以开始了, 点击下面的按钮,重新启动智能合约的执行:(默认情况下,remix在函数test()的开始处启动调试会话,因为在执行函数之前有一些代码,我们需要改变这一点)
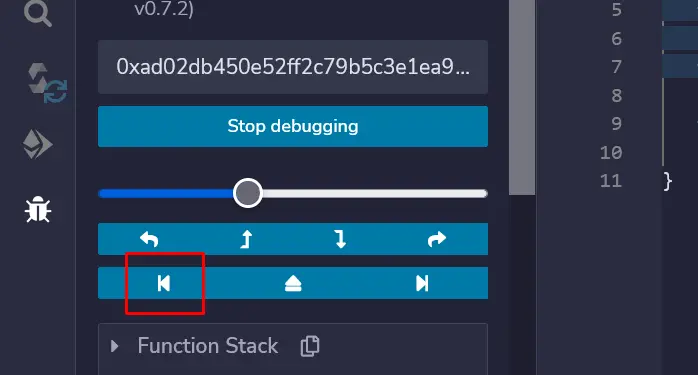
如果一切顺利,第一批指令应该弹出,可以通过点击这些箭头在指令之间逐一导航。
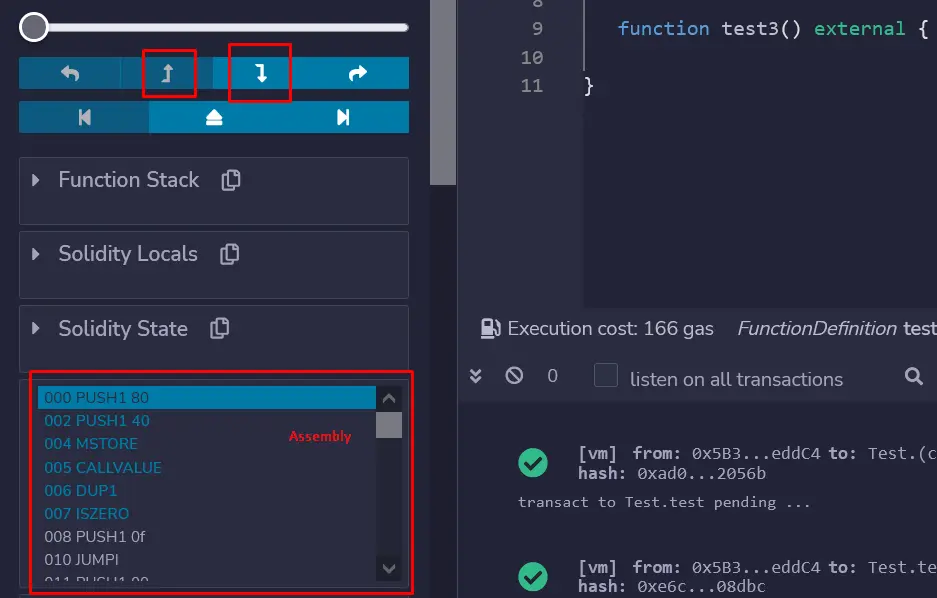
第一条指令是:
000 PUSH 80 | 0x80 |
002 PUSH 40 | 0x40 | 0x80 |
004 MSTORE ||
EVM在堆栈中PUSH 80和PUSH 40,结果它看起来像:
| 0x40 | 0x80 |。
在第4字节:MSTORE需要2个参数(offset,value): Stack(0) 和 Stack(1)
MSTORE将Stack(1)的值存储在内存中的Stack(0)位置中。
因此,EVM将0x80存储在内存的0x40地址,在调试标签的内存部分,你应该看到:
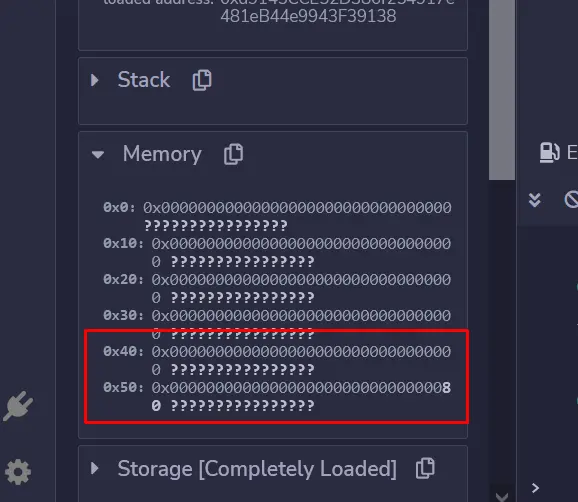
由于内存中的每一个插槽都是32个字节的长度(使用小端序的十六进制0x20),因此插槽40的内存位于0x40和0x40+0x20=0x60之间(我们将其记为内存[0x40:0x60]。
这就是为什么0x80在最后(0x5f位置)。
“????? "是内存中的字节的ASCII表示。
内存中的 "0x40 "槽在EVM中被命名为空闲内存指针,当需要内存时,它被用来分配内存的新槽。(我将在后面解释为什么它是有用的)。
重要的是:注意在一条指令之后,堆栈中所有需要的参数都会从堆栈中清除,并被返回值所取代。
由于MSTORE在堆栈中占用了2个参数,在MSTORE指令完成后,这2个参数会从堆栈中删除。
所以堆栈现在什么都不包含。
6. MSG.VALUE
005 CALLVALUE |msg.value|
006 DUP1 |msg.value|msg.value|
007 ISZERO |0x01|msg.value|
008 PUSH1 0f |0x0f|0x01|msg.value|
010 JUMPI |msg.value|
011 PUSH1 00 |0x00|msg.value| (if jumpi don't jump to 0f)
013 DUP1 |0x00|0x00|msg.value|
014 REVERT
CALLVALUE指令把msg.value(发送给智能合约的以太币)放在堆栈中。
由于我们没有向智能合约发送任何以太币,堆栈中的值是:| 0x00 |
DUP1指令将Stack(0)推入堆栈,我们可以说它 "复制"了堆栈开头的第一个指令:
|0x00 |0x00 |
注意还有DUP2, DUP3...DUPn(直到DUP16),它们将第n个值(Stack n-1)推到堆栈中。
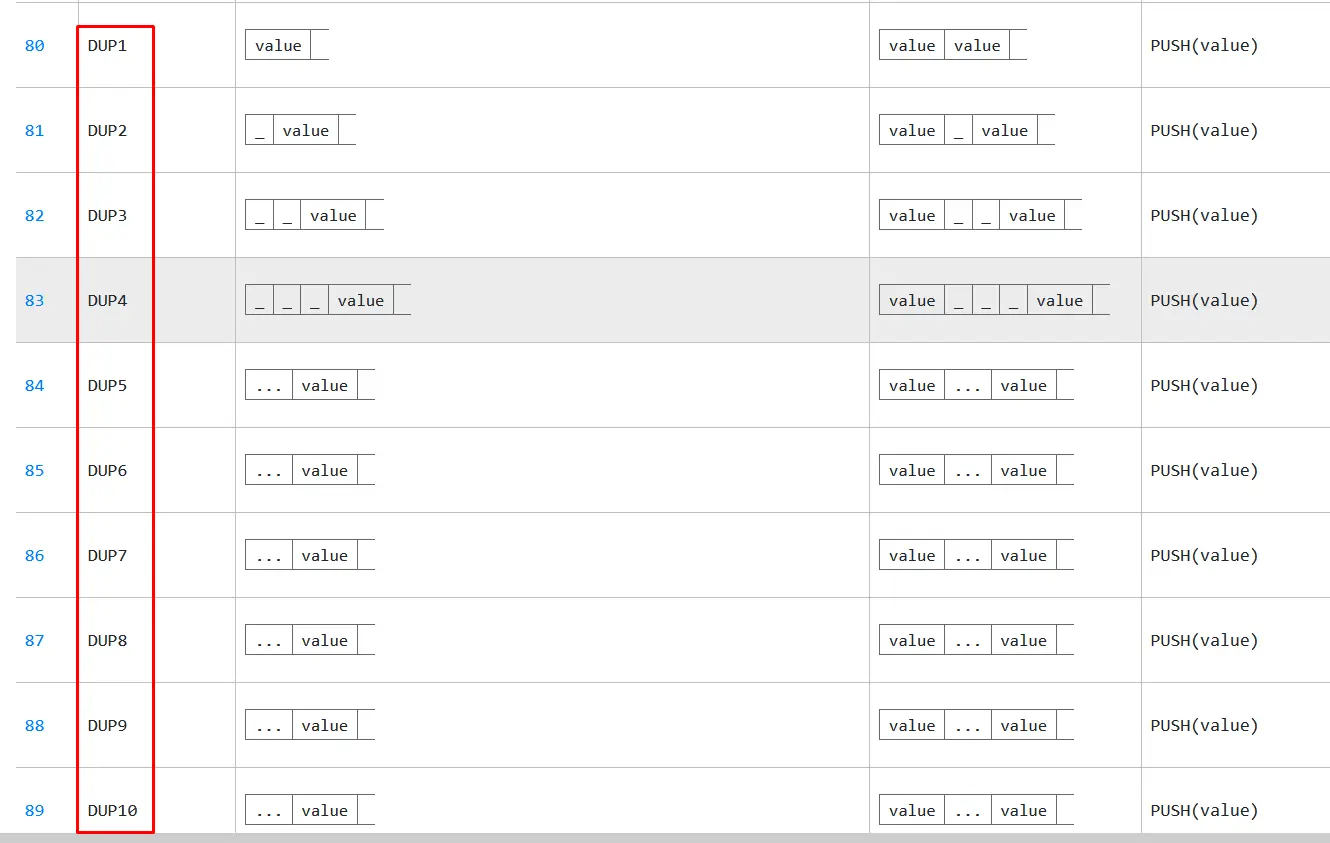
而EVM在第7字节调用ISZERO,ISZERO使用Stack中的1个参数(它是Stack(0))。
顾名思义,ISZERO验证Stack(0)是否等于0,如果是,EVM在第一个槽中推送 "1 "的值,即True。
| 0x01 | 0x00 |
EVM还删除了第一个0x00,因为它是ISZERO的参数。
之后在第8个指令,EVM将0x0f推到堆栈中 : | 0x0f | 0x01 | 0x00 |。
接下来我们有一个条件跳转(JUMPI),如果Stack(1)是1,EVM直接进入字节数Stack(0)所在的位置(因为Stack(0)=0f,十进制15),因此Stack(1)=1,EVM直接跳转到第15个指令
如果不是,EVM继续执行它的路径,执行PUSH**、DUP1和最后在第14字节的REVERT指令一样,以一个错误停止执行。
但是在这里,一切都很好!因为Stack(1)=1,所以在执行过程中会出现错误。由于Stack(1)=1,所以EVM跳到了0x0f(相当于15的十进制)。
我们将尝试理解在第5个指令和第14个指令之间发生了什么。
请注意,我们声明函数test()是非 payable 的,而且合约中没有receive()或fallback()函数可以接收以太币。
因此,这个合约不能接收到任何以太币(除了一个特定的情况,但在这里并不重要),所以如果我们发送以太币,它就会回退!。汇编中的代码相当于:
005 CALLVALUE load msg.value
006 DUP1 duplicate msg.value
007 ISZERO verify if msg.value is equal to 0
008 PUSH1 0f push 0f in the Stack (the byte location after the REVERT byte location)
010 JUMPI jump to this location if msg.value is not equal to 0
011 PUSH1 00 push 00 in the Stack
013 DUP1 duplicate 00 in the Stack
014 REVERT revert the execution
用 Solidity 表示,等价于:
if (msg.value > 0) {
revert();
} else {
// Jump to byte 15
}
所以这第二部分的代码只是验证是否有任何以太币发送到合约中,否则它就会被回退。
在第15个指令时,堆栈为 | 0x00 | (因为JUMP在堆栈中使用了2个参数,EVM将它们删除)
7. CALLDATASIZE
015 JUMPDEST | 0x00 |
016 POP ||
017 PUSH1 04 | 0x04 |
019 CALLDATASIZE | msg.data.size | 0x04 |
020 LT | msg.data.size > 0x04 |
021 PUSH1 3c | 0x3c | msg.data.size > 0x04 |
023 JUMPI || (JUMPI takes 2 arguments)060 JUMPDEST ||
061 PUSH1 00 |0x00|
063 DUP1 |0x00|0x00|
064 REVERT ||
JUMPDEST没有任何作用。它只是表示一条JUMP或JUMPI指令指向这里,如果EVM跳到一个没有标记为 "JUMPDEST"的地址(比如16号是POP),它就会自动回退。
接下来,EVM将堆栈的最后一个元素POP出来,然后PUSH 04,因此在第17个指令之后,堆栈内只有一个元素: | 0x04 |
EVM调用CALLDATASIZE,等于msg.data.size(以太坊交易中数据字段的大小),现在堆栈是:| 0x04 | 0x04 |
(当一个函数被调用时没有参数msg.data.size = 4,这4个字节被称为函数 "签名")
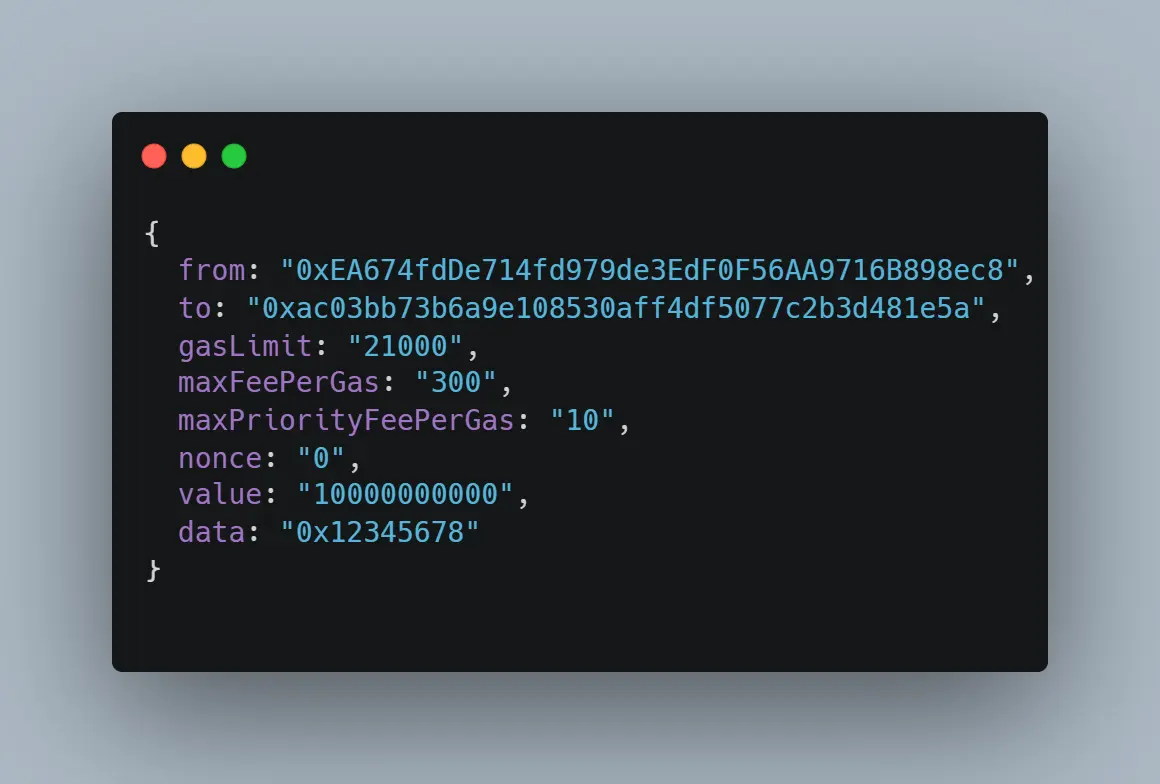
例如这里msg.data等于"0x12345678",msg.data.size=4(8个十六进制数字)。
后来在第20个指令,EVM调用LT(小于),它比较堆栈上的两个值(如果Stack(0) < Stack(1),那么我们写1,否则写0)。
在我们的例子中,它是假的! 4不小于4(运算符LT是严格的)。
所以EVM不会跳到3c(因为Stack(0) = 3c和Stack(1) = 0),EVM继续执行流程,就像什么都没发生一样。
但是如果CALLDATASIZE小于4(如0、1、2或3),那么Stack(1)=1,然后EVM跳到0x28(十进制的40),EVM 回退 !
下面是发生的情况:
015 JUMPDEST
016 POP pop
017 PUSH1 04 store 0x04 in the stack
019 CALLDATASIZE get msg.data.size in the stack
020 LT verify if msg.data.size < 0x04
021 PUSH1 3c push 0x3c (60 in dec)
023 JUMPI jump to 60 if msg.data.size < 0x04060 JUMPDEST
061 PUSH1 00
063 DUP1
064 REVERT revert the execution
这意味着msg.data不能小于4,你会在下一节明白为什么!
if (msg.data.size < 4) { revert(); }
8. 函数选择器
一旦所有事先验证完成。
我们需要调用函数test()并执行它的代码。但在我们的合约中有几个函数(test() test2() 和 test3()),如何找出EVM需要执行的函数呢?
这就是函数选择器的作用。
下面是接下来的反汇编步骤
024 PUSH1 00 |0x00| (the stack was previously empty in byte 23)
026 CALLDATALOAD |0xf8a8fd6d0000000.60zeros.000000000|
027 PUSH1 e0 |0xe0|0xf8a8fd6d0000000.60zeros.000000000|
029 SHR |0xf8a8fd6d|
030 DUP1 |0xf8a8fd6d|0xf8a8fd6d|
031 PUSH4 0a8e8e01 |0x0a8e8e01|0xf8a8fd6d|0xf8a8fd6d|
036 EQ |0x0|0xf8a8fd6d|0xf8a8fd6d|
037 PUSH1 41 |0x41|0x1|0xf8a8fd6d|
039 JUMPI |0xf8a8fd6d|
040 DUP1 |0xf8a8fd6d|0xf8a8fd6d|
041 PUSH4 66e41cb7 |0x66e41cb7|0xf8a8fd6d|0xf8a8fd6d|
046 EQ |0x0|0xf8a8fd6d|
047 PUSH1 49 |0x49|0x1|0xf8a8fd6d|
049 JUMPI |0xf8a8fd6d|
050 DUP1 |0xf8a8fd6d|0xf8a8fd6d|
051 PUSH4 f8a8fd6d |0xf8a8fd6d|0xf8a8fd6d|0xf8a8fd6d|
056 EQ |0x1|0xf8a8fd6d|
057 PUSH1 51 |0x51|0x1|0xf8a8fd6d|
059 JUMPI |0xf8a8fd6d|
你可能已经知道什么是以太坊的函数签名:它是函数名称的哈希值的前4个字节,对于test()来说,它是 :
bytes4(keccak256(”test()”)) = 0xf8a8fd6d
CALLDATALOAD 接受1个参数Stack(0)作为偏移量,并将msg.data之后的在参数位置(这里是Stack(0))的下一个32字节存储在堆栈中Stack(0)
在此案例中,它存储msg.data的前32字节(因为Stack(0) = 0)。
但只有4个字节(如前所述),因此堆栈将是这样的:
| 0xf8a8fd6d00000000000000000000000000000000000000000000000000000 |
下一个操作码是PUSH e0和SHR位于第27指令(使用2个参数),它通过Stack(0)(这里是c0)向右(>>)执行二进制移位,堆栈(在SHR之前)的值为:
|0xc0|0xf8a8fd6d00000000000000000000000000000000000000000000000000000 |
下面是用SHR进行的详细计算(如果你愿意可以跳过):
A place in stack is of length 32 bytes = 256 bits
In binary Stack(1) = 11111000101010001111110101101101 and 192 zeros after that
c0 = 192 in decimal, so we will shift 192 time to the right
0 times : 11111000101010001111110101101101..... + 192 zeros
1 times : 011111000101010001111110101101101.... + 191 zeros
2 times : 0011111000101010001111110101101101... + 190 zeros
192 times : 192 zeros + 0011111000101010001111110101101101...
= 0x00000000000000000000000000000000000000000000000000000f8a8fd6d
= 0x00..60zeros00f8a8fd6d
在DUP操作码之后,堆栈看起来像| 0xf8a8fd6d | 0xf8a8fd6d |。
值得注意的是,这就是我们的test()签名,这很正常!函数的签名总是出现在交易数据的前4个字节中。
在以太坊交易中,我们不会直接发送要执行的函数的名称,而只是发送4个字节的签名。
在第31个操作码中,EVM PUSH一个4字节的值到堆栈:0a8e8e01
| 0xa8e8e01 | 0xf8a8fd6d | 0xf8a8fd6d |
并调用EQ,比较(Stack(0)和Stack(1))。
这两个值显然是不相等的:因此我们用0代替它们
| 0x0 | 0xf8a8fd6d |
这样我们就不会JUMP到41(65的十六进制)(后面有指令PUSH1 41和一个JUMPI)。
EVM对0x66e41cb7(操作码41到50)也做了同样的事情,这也不等于0xf8a8fd6d。
最后,EVM用0xf8a8fd6d来执行,由于现在等于0xf8a8fd6d! 所以我们跳到51(十六进制是81),这是test()函数的开始:
081 JUMPDEST |0xf8a8fd6d|
082 PUSH1 57 |0x57|0xf8a8fd6d|
084 PUSH1 5d |0x5d|0x57|0xf8a8fd6d|
086 JUMP |0x57|0xf8a8fd6d|
087 JUMPDEST |0xf8a8fd6d|
088 STOP ||
093 JUMPDEST |0x57|0xf8a8fd6d|
094 JUMP |0xf8a8fd6d|
你可以很容易地分析我们的test()函数中最后执行的8条指令。
它只执行了一系列的JUMP指令,在函数的最后,操作码STOP,它停止了合约的执行而没有产生错误。
所有这些代码的行为就像编程中的一个开关。
0xf8a8fd6d是 "test()"函数的签名
0x0a8e8e01和0x66e41cb7是test2和test3函数的签名。
如果交易数据中的签名与这些签名之一相符,那么通过跳转到函数的代码位置(代码中的41,49和51)来执行函数的代码。
否则。如果交易数据中的签名与代码中的任何函数签名不匹配,EVM将调用回退函数,但在我们的智能合约中没有这样的函数(至少现在没有)!因此:EVM将重新调用回退函数。结果是:EVM回退,故事到此结束。
这是59(函数选择器开关)之后的代码:
060 JUMPDEST
061 PUSH1 00
063 DUP1
064 REVERT
因此,我们可以重构智能合约的完整代码:
mstore(0x40,0x80)
if (msg.value > 0) { revert(); }
if (msg.data.size < 4) { revert(); }
byte4 selector = msg.data[0x00:0x04]
switch (selector) {
case 0x0a8e8e01: // JUMP to 41 (65 in dec) stop()
case 0x66e41cb7: // JUMP to 49 (73 in dec) stop()
case 0xf8a8fd6d: // JUMP to 51 (85 in dec) stop()
default: revert();
stop()
我们完成了!
9. 总结
我们成功地学会了。
- 一些基本的EVM 汇编。
- EVM如何执行智能合约。
- 哪些代码在执行函数之前被执行。
- LIFO堆栈如何工作。
- remix调试器的基本使用。
- 函数选择器。
- 还有很多...
这个系列的第一篇关于通过调试理解EVM的内容就到此为止。我希望你在这里学到很多东西。
下一部分见!
这是我们关于通过调试理解EVM系列的第1部分,在这里你可以找到之前和接下来的部分。
转载自:https://learnblockchain.cn/article/4913