gETH 兑换 gBZZ
目前https://bzz.ethswarm.org/ 挂了,现在可以使用uniswap来兑换
https://app.uniswap.org/#/swap?use=V2
在选择通行证那里输入gBZZ合约地址
0x2ac3c1d3e24b45c6c310534bc2dd84b5ed576335
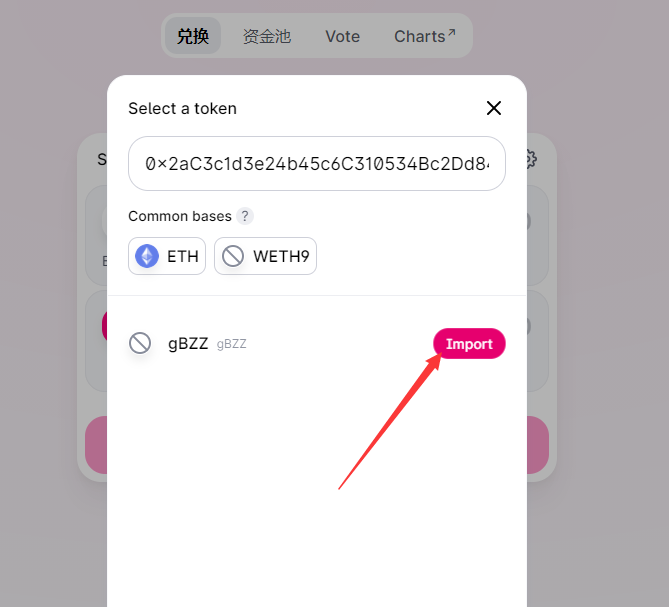
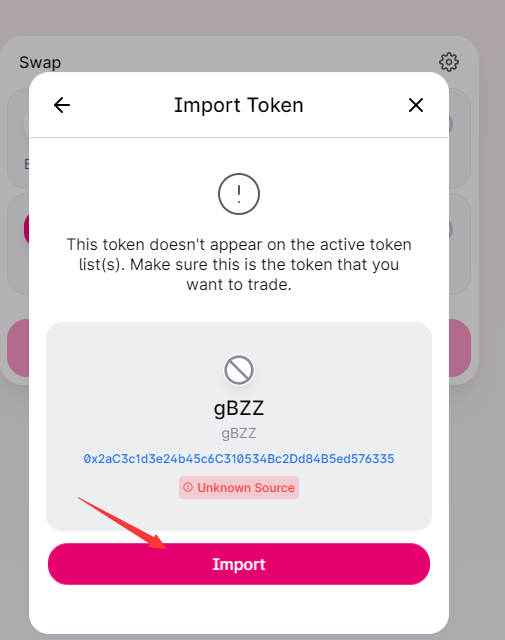
添加gBZZ
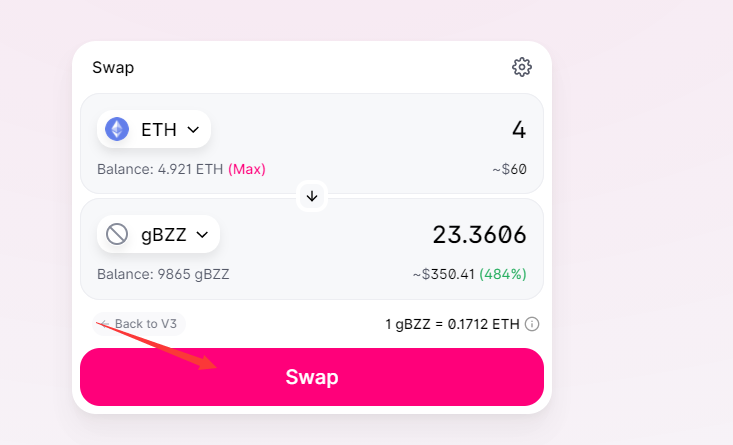
然后兑换对应数量的gBZZ即可
Swarm Bee 节点升级
https://docs.ethswarm.org/docs/working-with-bee/upgrading-bee/
https://gist.github.com/ralph-pichler/3b5ccd7a5c5cd0500e6428752b37e975
https://github.com/leepood/bee-upgrade-tools/blob/main/deploy.sh
目前v0.6.1还存在一个BUG
https://github.com/ethersphere/bee/issues/1823
2021-5-23 03:00 官方通知
https://discord.com/channels/799027393297514537/810905662375854123/845743602553454672
亲爱的大家,
V0.6.1被确定为不稳定。 我们建议尚未从v0.5.3更新的所有人继续操作该版本,直到另行通知。
对于已经更新到v0.6.1的人们,您可以继续运行节点并熟悉新暴露的功能,或者暂时停止运行节点,直到v0.6.2退出。
感谢大家的耐心和理解。 我们试图尽快解决这种情况。2021-5-23 09:40
等待社区放出0.6.2版本修复,目前无可用版本

对于想继续使用0.5.3的,如果卡在
time="2021-05-26T15:03:01+08:00" level=debug msg="discover fail /dnsaddr/bootnode.ethswarm.org: discover /dnsaddr/swarm-3.bootnode.ethswarm.org: discover /dnsaddr/bee-10.bootnode.ethswarm.org: discover /ip4/3.235.55.200/tcp/31400/p2p/16Uiu2HAmGwAEGJSb3XBNDLwGPbbcLL8LceDhMZeki8aciphcfdXr: connect new stream: incompatible stream: protocol not supported"
time="2021-05-26T15:03:01+08:00" level=warning msg="discover to bootnode /dnsaddr/bootnode.ethswarm.org"可以尝试执行
curl -X POST localhost:1635/connect/ip4/172.105.208.202/tcp/1634/p2p/16Uiu2HAmVQdBWSS11s3m3PtGVi92Ts2m7UvxnJmVLJQVdfaxu63z
curl -X POST localhost:1635/connect/ip4/172.104.83.228/tcp/1634/p2p/16Uiu2HAmGTv2AqBCEmZy8PGpNXj6a2TjTzjvmht1hha1Sg88ALqk
curl -X POST localhost:1635/connect/ip4/107.182.177.94/tcp/1640/p2p/16Uiu2HAkvu5g73Q5MpFooLPNHvbyaocHH4bZdLCnVHuZkK4wFc5Z
curl -X POST localhost:1635/connect/ip4/51.79.68.121/tcp/1634/p2p/16Uiu2HAm5KXkSSg1uk3KdvJYWNGuVwMA1ASurcunELrhFV9sadtV
curl -X POST localhost:1635/connect/ip4/23.224.227.34/tcp/50144/p2p/16Uiu2HAmLEjmegMaV8D8JLVJWGZXFq4MfPrc37TVfhDMQPxaUvRY
curl -X POST localhost:1635/connect/ip4/172.96.203.143/tcp/1640/p2p/16Uiu2HAmQXEfeDoBm4eTFSYJcQ8BBCJzccxSvjAyY3XaiHtYrHEp
curl -X POST localhost:1635/connect/ip4/172.105.238.165/tcp/1634/p2p/16Uiu2HAmSU1qU83tJZAh1z6ZhGshQ9gfeU558iNGZZrpkDdi47rB
curl -X POST localhost:1635/connect/ip4/218.93.127.19/tcp/1634/p2p/16Uiu2HAm83rDQMs9sXMyuVVZwtTZiYCexkaM6zfRVZqs2RxJKnzx
curl -X POST localhost:1635/connect/ip4/66.181.45.134/tcp/50254/p2p/16Uiu2HAkzyGEtXiqx77A4JJ1hA5ojsCfRD5XPM2jWNsTiiX6wvAi
curl -X POST localhost:1635/connect/ip4/154.215.142.136/tcp/1634/p2p/16Uiu2HAmUFKWHjk9bY7HRx2eeUoMPUPCoADp21UBhgpsF8dWQ6YE
curl -X POST localhost:1635/connect/ip4/66.181.34.124/tcp/50214/p2p/16Uiu2HAmMwt4FYr1uoZFWZRXXUJHqS5hozxW2GVWqegKGvmYW4vK
curl -X POST localhost:1635/connect/ip4/66.181.34.210/tcp/50214/p2p/16Uiu2HAmUdvc8Xw8JBkvKQXCrPTSBx2sR8tiqUd9aqZKVMJsgmnr
curl -X POST localhost:1635/connect/ip4/97.64.22.192/tcp/1652/p2p/16Uiu2HAmE1tHqu1VMVuaDPnC1z7zB3Xgs8ho6EaidtztteNajYb6
curl -X POST localhost:1635/connect/ip4/149.28.71.169/tcp/1634/p2p/16Uiu2HAmAsbNuMgdcGQhmp6bDLiKEnwAq5h3HJrNLzpUXjJ7MBbt
curl -X POST localhost:1635/connect/ip4/103.96.74.61/tcp/1634/p2p/16Uiu2HAmPuiJykpgS51XWyyB7NMHg1PVyz9edPernMdaSJ7nVe5d
curl -X POST localhost:1635/connect/ip4/47.242.203.75/tcp/10015/p2p/16Uiu2HAmKjSZQHiUYzG9Z2nR6mFV6nSpskK8UPcfcGF1K88Hy5YGSwarm一个以太坊地址部署多个节点
先说结果:目前不能实现
在分析下原因
我们说关键的几个点
- 由于bee每个节点本地累计nonce,多节点并发可能拿到同样的nonce,如果同时操作同样的交易,则导致交易被覆盖
主要体现在兑换获得相同支票,
这个到容易解决
bee\pkg\settlement\swap\transaction\transaction.go

- 同样的以太坊地址导致计算的
swarm network address
swarm public key
从而 p2p address 相同
导致kademlia被拒
https://github.com/ethersphere/bee/issues/1789

https://github.com/ethersphere/bee/issues/1789
还想到用swap-factory-address各个节点配置统一个合约地址,来绕过
// verify that the supplied factory is valid
err = chequebookFactory.VerifyBytecode(ctx)
if err != nil {
return nil, err
}if err = chequebookFactory.VerifyBytecode(p2pCtx); err != nil {
return nil, fmt.Errorf("factory fail: %w", err)
}这官方最近也明确多开违规了
https://docs.ethswarm.org/docs/FAQ/#can-i-use-one-ethereum-addresswallet-for-many-nodes
等忙完稍后再继续跟吧