网站:https://www.magicblock.xyz/
github: https://github.com/magicblock-labs
docs:https://docs.magicblock.gg/introduction
您正在查看: Surou 发布的文章
Solana + 以太坊:罗马协议链接
介绍
罗马帝国再次重生,但这一次是数字化的。
让我们回到 1500 年前,想象一下古罗马,那里有繁华的市场、角斗士游戏和战车比赛。但有一个问题,他们征服的地区有自己独特的规则、货币、语言和习俗,这可能会使治理和贸易变得复杂。
为了解决这个问题,他们开始努力修建道路、渡槽和桥梁,连接整个帝国,使贸易、旅行和日常生活比以往任何时候都更加顺畅。众所周知,罗马帝国是当时最伟大的帝国之一。
快进到今天的区块链世界,我们几乎回到了早期的罗马时代,当时的网络孤岛彼此之间难以轻松通信。罗马协议正是为此而生,它希望重现古代连接天才——但这次是在区块链上。就像古罗马修建道路和桥梁一样,罗马协议也在 Solana 和以太坊生态系统之间建立通道,以便 dApp 和资产可以在它们之间自由流动。这还是同一个罗马,但罗马袍子更少,科技更多!
什么是罗马协议
Rome 协议是一种解决方案,它允许开发人员和用户在 Solana 区块链上运行基于以太坊的应用程序 (dApp),从而结合两个平台的优势。Rome 通过在Solana和其他基于以太坊的网络之间建立顺畅的链接,提供跨不同区块链进行快速、安全交易的工具。
通过 Rome EVM、共享序列器、Interop 和 DA(数据可用性)等组件,它允许开发人员构建可以在不同区块链环境中无缝运行的应用程序。
本质上,Rome 旨在将以太坊的生态系统带入 Solana,使用户无需离开一个平台即可与两个区块链上的应用程序进行交互。它支持跨链交易、公平的交易排序和高速数据处理,使去中心化应用程序更加灵活、高效和用户友好。
Rome 协议就像一座桥梁,让为以太坊构建的应用程序可以在 Solana 区块链上运行,让用户同时享受两全其美的优势。例如,如果您想在以太坊上构建 dApp,比如去中心化交易所 (DEX)或借贷平台,并希望将其扩展到 Solana 更快、更低成本的环境。借助 Rome,您可以将以太坊 dApp 带到 Solana,而无需从头开始重建它。
罗马协议架构:关键组件
罗马有几个部分可以实现这一目标:
- Rome EVM:可以将其视为 Solana 上的以太坊引擎。就像以太坊应用程序可以轻松在其他兼容以太坊的区块链上使用一样,开发人员现在可以直接在 Solana 上部署他们的以太坊应用程序,并且交易方式让以太坊用户感到很熟悉。
- 共享序列器:此工具可确保公平高效地组织来自不同 rollup(或网络)的交易,以便按正确的顺序处理每笔交易。例如,如果用户在区块链之间交换代币,则共享序列器可确保交换的双方同步进行。
- Rome Interop:假设您正在使用 Solana 的 DeFi 服务,但同时又想与以太坊上的资产进行交互。借助 Interop,用户可以无缝链接跨区块链交易 — — 例如在 Solana 上借款,同时在以太坊上保护资产。
- Rome DA(数据可用性):此功能可确保数据在 Solana、Celestia或 Ethereum 上可访问且安全,具体取决于配置。如果您正在运行包含关键交易数据的应用程序,Rome DA 可确保这些数据安全地记录在一条或多条链上。
简而言之,罗马协议允许开发人员将以太坊的生态系统带入 Solana 的速度和可负担性,让用户享受跨不同区块链的顺畅交互,例如贷款、交易或质押,所有这些都在一次连接的体验中。

Rome Stack,来源;Rome Docs
罗马议定书使命
罗马协议的使命是让区块链网络更具互操作性和模块化,解决当今区块链可扩展性和用户体验的一些关键障碍。
其目标是创建一个无缝、有凝聚力的生态系统,其中数据、资产和功能可以轻松地在不同的区块链之间移动,利用 Solana 和以太坊的独特优势。
罗马协议如何增强区块链之间的互操作性和模块化:
互操作性:桥接区块链网络
罗马协议实现了互操作性,允许资产和数据在不同区块链之间轻松转移。通过连接 Solana 和以太坊,它克服了孤立生态系统的限制,让每个链上的应用程序可以相互交互。
这种互操作性使跨链应用程序(例如去中心化金融(DeFi)平台)能够无障碍运行,从而增强了用户体验和流动性。
想象一下,如果一个国家的每个城市都有自己独特的货币和交通系统,人们出行或做生意会变得很困难。罗马议定书充当了国家系统,使货币和城市间交通标准化,使流动和交易变得无缝衔接。
通过强大的基础设施连接 Solana 和以太坊,Rome 旨在实现原子可组合性,即通过单一原子操作(全部或全部)跨区块链进行交易的能力。

资料来源:罗马文件
这种互操作性使一条链上的去中心化应用程序 (dApp) 能够与另一条链上的资产、数据或逻辑顺利交互,从而消除孤立生态系统造成的障碍。让我们来看看如何实现;
- Rome EVM:通过将以太坊的 EVM 环境引入 Solana,Rome 使开发人员能够轻松地在 Solana 上部署以太坊 dApp,而不会损害 dApp 的功能。这使用户更容易执行跨链交易,而无需进行大量的技术变通。
- Rome Interop (SDK):此工具包支持跨链和跨 rollup 交易,允许开发人员创建使用跨多链数据和流动性的应用程序。这种连接为 DeFi、GameFi 和其他区块链领域创造了更丰富的环境,因为资产和应用程序可以无缝跨越生态系统。
Rome 交易:促进原子可组合性
Rome 支持各种类型的交易,每种交易都针对跨链的特定交互而量身定制:

-
Rhea 交易:Rhea 交易将单个 rollup 交易封装在 Solana 交易中,这意味着交易直接在 Solana 的基础设施上执行。此设置非常适合简单的单 rollup 交易,这些交易不需要与其他 rollup 或链交互。

资料来源:罗马文件 -
Remus 交易:Remus 将多个跨 rollup 交易捆绑为单个 Solana 交易。这意味着所有 rollup 交易要么一起执行,要么一起失败,从而实现原子性。此设置对于涉及多个 rollup 的操作特别有用,例如跨 rollup DeFi 操作或捆绑支付。

资料来源:罗马文件 -
Romulus 交易:Romulus 允许在单个跨链交易中执行 rollup 和 Solana 原生交易的组合。此功能非常适合需要同时在 Solana 和以太坊 rollup 上进行操作的场景,例如跨链转移资产或执行涉及不同区块链生态系统的复杂 DeFi 策略。

资料来源:罗马文件
该系统确保原子性,即交易的所有部分要么全部成功完成,要么全部失败。例如,跨 Solana 和以太坊的套利交易只有在所有子交易都成功的情况下才会完成。
罗马协议互操作性的影响
- 增强的 DeFi 功能:借助 Rome Protocol 的原子可组合性,开发人员可以构建更先进的 DeFi 产品,例如多链闪电贷、跨链收益农业和利用 Solana 速度和以太坊流动性的套利工具。
- 提高用户灵活性和效率:用户可以自由访问多个生态系统中的功能,而无需手动切换网络或担心任何一方的交易失败。这种无缝性鼓励了 dApp 的更广泛采用和可用性。
- 开发灵活性:Rome 允许开发人员构建利用以太坊和 Solana 最佳功能的应用程序,而无需重写整个应用程序。这扩大了创新的可能性,同时降低了多链应用程序的技术和财务障碍。
模块化:构建专业化、可扩展的层
Rome Protocol 采用模块化区块链架构,将传统区块链组件拆分为专门的层。与所有功能(计算、共识和数据存储)都发生在一条链上的单片区块链不同,Rome 将这些层解耦。
这种方法使每个组件能够独立运行但又与其他组件同步,从而提高了灵活性和可扩展性。
可以将模块化区块链想象成一家拥有专门部门的公司,例如 IT、财务和客户支持。每个部门都独立运作,但为了公司的成功,他们无缝协作。同样,Rome 的模块化架构允许每一层都专业化并高效运行。
Rome Protocol 的架构是模块化的,旨在将区块链功能分解为不同的组件(例如计算、数据可用性和交易排序),从而使每一层都专注于其专门的功能。让我们来看看;
-
共享排序器 (Rhea)和Hercules:这些组件分别处理交易排序和状态推进,从而实现可扩展的独立处理。这种模块化方法不是在单个区块链层中处理所有内容,而是将任务分开,从而提高了速度和灵活性。

资料来源:罗马文件 -
数据可用性:Rome Protocol 利用 Solana 的高吞吐量和 Celestia 实现数据可用性,这意味着开发人员和应用程序可以选择最合适的数据存储和检索方法。这种模块化选项允许汇总独立配置其数据需求,同时受益于 Solana 的安全性和速度。

资料来源:罗马文件
模块化区块链架构的重要性:通过 Rome 的模块化增强 Solana
模块化区块链架构是一种变革性方法,它将区块链功能划分为单独的专用层,每个层都专注于一个核心功能——例如数据可用性、共识、结算或执行。
这种模块化设置使每一层都可以独立优化,从而实现灵活性、可扩展性和跨链互操作性。Rome 对 Solana 的模块化利用了这些原则,创建了一个以 Solana 的速度和成本效益为基础的生态系统,同时扩展了与以太坊的功能和互操作性。
Rome 的模块化设计如何增强更广泛的区块链生态系统:
在 Solana 上启用 EVM 兼容性
- 扩大开发者生态系统:Rome 的模块化方法在 Solana 上引入了与以太坊兼容的虚拟机 (Rome EVM),允许开发者无需修改即可部署基于以太坊的 dApp。这使 Solana 向庞大的以太坊开发社区开放,鼓励流行的以太坊应用程序迁移并吸引新项目。
- 与以太坊 dApp 的互操作性:通过将OP Geth(以太坊的执行客户端)集成到 Solana 生态系统中,Rome 使以前仅限于以太坊的 dApp 能够在 Solana 更快、更实惠的网络上运行。例如,以太坊上的 DeFi 项目可以扩展到 Solana,为用户提供更多选择,同时受益于 Solana 的低成本交易。

资料来源:罗马文件
解耦数据可用性和结算
- 可配置数据可用性 (DA):Rome 的架构支持多种 DA 解决方案,允许rollup选择使用 Solana、Celestia 或以太坊来实现数据可用性。通过使 DA 模块化,Rome 让开发人员能够根据自己的特定需求灵活地优先考虑成本或安全性。例如,专注于高吞吐量的 rollup 可能会选择 Solana 来实现 DA,而需要更高安全性的 rollup 可能会选择以太坊。
- 以太坊上的高效结算:Rome 通过使用 Hercules 将 rollup 状态提交到以太坊,将结算与交易执行分离开来。结算中的这种模块化使 rollup 能够从以太坊的安全性中受益,而不会牺牲 Solana 的速度,从而使系统既高效又安全。

资料来源:罗马文件
跨链和跨 Rollup 可组合性
- 增强的多链 dApp 功能: Rome 的模块化方法支持 Remus(跨 rollup)和 Romulus(跨链)交易,允许应用程序跨不同的区块链执行原子操作。这对于需要 Solana 和以太坊之间可组合性的 dApp 至关重要。例如,DeFi 协议可以提供跨两个网络的流动性池,使用户无需切换链即可汇集和交易资产。

资料来源:罗马文件 - 集成多链生态系统:通过确保原子性和可组合性,Rome 增强了区块链应用程序的互联互通性,使各种 dApp 和资产能够无缝交互。这为在多条链上同时运行的新型去中心化应用程序铺平了道路,增强了用户体验并拓宽了区块链现实世界应用的范围。

资料来源:罗马文件
加速开发并降低复杂性:
- 简化的开发人员体验:Rome SDK 是模块化设置的一部分,它为开发人员提供了一个易于使用的框架来构建跨链和跨汇总应用程序。借助编写原子交易、将其提交给 Solana 并订阅汇总内存池的工具,开发人员可以更快、更轻松地构建多链应用程序。
- 提高网络效率:通过模块化执行、排序、DA 和结算,Rome 优化了网络资源,确保每个功能都由最合适的组件处理。这提高了 Solana 的吞吐量并最大限度地降低了交易费用,使网络更加高效,可供更广泛的用户和用例使用。
构建可扩展且面向未来的区块链生态系统
- 通过专业化实现可扩展性:使用 Rome 对 Solana 架构进行模块化有助于提高可扩展性,因为这样可以让每个组件专注于其特定功能。随着区块链使用的增长,模块化可确保每个层(无论是数据可用性、排序还是结算)都可以独立优化和扩展,而不会破坏整个系统。
- 灵活应对未来: Rome 的模块化设计使其能够适应区块链技术的未来升级或变化。例如,如果出现新的数据可用性解决方案,Rome 生态系统中的汇总可以将其集成,而无需更改其他组件。这种灵活性确保 Rome 和 Solana 能够随着技术进步而不断发展。
为什么互操作性和模块化很重要
互操作性意味着区块链协同工作,而模块化意味着区块链内功能的分离,这是未来区块链应用的基础。像以太坊这样的传统区块链由于需要在一条链上处理每笔交易和数据请求,因此往往难以实现可扩展性。罗马协议带来了模块化设计和可互操作的解决方案,允许由专门的系统管理单独的功能,例如用于交易处理的 Solana 和用于结算的以太坊。通过这样做,罗马协议可以优化性能并减少瓶颈。
罗马协议如何解决区块链中的关键挑战
罗马协议解决了区块链生态系统中的几个关键问题:
- 跨链互操作性:Rome 为跨以太坊和 Solana 的顺畅、安全交易提供了一个框架,解决了传统桥梁的低效率问题。
- 原子可组合性:通过确保跨链操作的原子性,Rome 支持闪电贷和套利等关键的 DeFi 功能,其中跨链交易成功至关重要。
- 跨汇总交易的可扩展性:Rome 的共享序列器优化了汇总的交易排序和数据可用性,从而提高了多链 dApp 的性能。
- 数据可用性和结算:Rome 的模块化方法可确保跨网络的高效数据可用性和最终结算,使用 Solana 确保速度,使用 Ethereum 确保安全性。
- 简化的开发人员体验:Rome SDK 为开发人员提供了全面的工具包,简化了构建跨链应用程序的过程并加速了采用。
用例:罗马协议的实际应用和影响
罗马协议允许与以太坊兼容的应用程序在 Solana 上运行并支持无缝跨链交易,从而实现跨区块链垂直领域的广泛用例。以下是罗马协议的功能将对现实世界产生影响的一些关键垂直领域:
DeFi(去中心化金融)
- 跨链闪电贷:闪电贷已成为 DeFi 用户必不可少的工具,允许在单笔交易中借入和还款,通常用于套利或流动性提供。借助 Rome 的跨链原子性(Remus 和 Romulus 交易),用户可以在 Solana 上进行闪电贷,并在一笔有凝聚力的交易中跨以太坊和基于 Solana 的交易所进行套利。
- 跨链质押:Rome 允许用户在基于以太坊的平台上质押资产,同时在 Solana 上执行收益耕作策略。这种灵活性使用户可以从 Solana 的 DeFi 协议中获得更高的回报,同时将资产质押以获得以太坊上的奖励。
- 同步 DEX 操作:Rome 允许去中心化交易所 (DEX) 为用户提供即时跨链交易。例如,用户可以在基于以太坊的 DEX 上交易资产,并在 Solana 上交换,而无需任何手动桥接或复杂的交易步骤
NFT 和游戏
- 跨链 NFT 铸造和市场:借助 Rome,可以在 Solana 上创建 NFT,并立即在以太坊市场上提供(反之亦然)。Rome 的互操作性和原子可组合性确保当在一条链上铸造 NFT 时,它会自动反映在另一条链上,从而使 NFT 真正成为多链。
- 跨区块链的游戏内资产转移:对于基于区块链的游戏,游戏内物品或货币很有价值,Rome 允许开发人员创建可在 Solana 和以太坊之间无缝交互的游戏内资产。玩家可以在基于以太坊的游戏中购买物品,并在基于 Solana 的游戏中使用它们,而无需手动转移或增加成本。
- 多链忠诚度计划:Rome 支持忠诚度计划,奖励和收藏品可以在生态系统之间流动。这对于寻求增加跨平台用户参与度的品牌或项目来说非常有价值,因为它们可以创建无缝、可互操作的奖励系统。
现实世界资产(RWA)和代币化资产
- 跨链代币化资产:Rome 的原子交易可确保无需信任、无需托管的跨链交易,非常适合代币化的现实世界资产,如房地产、股票或商品。例如,用户可以在以太坊上将房地产代币化,并在基于 Solana 的 DeFi 平台上利用它,而无需复杂的托管中介。
- 资产转移的跨链结算:罗马协议允许跨链即时、可验证地结算代币化资产。金融机构或市场可以使用该功能来处理跨多链证券,从而通过一个无缝步骤提供流动性和交易终结性。
- 合规资产管理:通过 Rome DA 提供的数据可用性和透明度,机构参与者可以更好地确保跨多个链的监管合规性,同时在 Solana 上获得高吞吐量和更低成本。
DAO(去中心化自治组织)
- 跨链治理:当 DAO 的成员分散在多个区块链上时, DAO通常会面临挑战。Rome 支持跨以太坊和 Solana 互操作的治理系统,允许成员投票或参与 DAO 活动,无论他们使用的是哪条链。
- 多链资金管理:Rome 可以帮助 DAO 管理以太坊和 Solana 上的资金,在统一的原子交易中执行交换、分配或收益生成等交易。这对于希望在不手动桥接资产的情况下最大限度提高资金效率的 DAO 尤其有价值。
- 同步提案和投票:通过确保跨链数据可用性,Rome 可以促进同步投票,其中每个成员在以太坊或 Solana 上的投票都会被同时记录和识别,从而创建跨链的有凝聚力的治理体验。
跨链套利与做市
- 跨链套利机器人:借助 Rome Protocol,做市商和套利者可以运行在以太坊和 Solana 之间执行原子交易的机器人。例如,套利机器人可以发现以太坊和 Solana 上的 DEX 之间的价格差异,在一条链上执行交换,并立即在另一条链上转售。
- 跨链自动做市:Rome 可以促进横跨以太坊和 Solana 的流动性池,从而实现跨链流动性提供和提取。这使用户能够访问多链流动性池和更好的交易选项,而无需手动来回移动资产
多链 dApp 开发
- 跨链一站式 dApp 部署:Rome 的架构,尤其是 Rome EVM,让开发者能够轻松地在 Solana 上直接部署以太坊 dApp。以太坊开发者可以快速将现有的 dApp 扩展到 Solana,从而吸引来自两个生态系统的用户,而无需额外的开发开销。
- 统一的跨链钱包和投资组合:Rome 可用于构建钱包,无缝显示和管理以太坊和 Solana 的资产。用户可以查看他们的 Solana NFT 和以太坊代币,并进行交易,而无需在平台之间切换。
- 原子跨链智能合约:Rome 允许开发人员编写智能合约,只需一步即可在以太坊和 Solana 上执行功能。例如,借贷 dApp 可以允许用户在 Solana 上存入抵押品,同时在以太坊上借贷,所有这些都通过一次智能合约调用完成。
结论
Rome Protocol 通过将 Solana 的速度与以太坊的生态系统相结合,代表着向互联、去中心化未来的转变。凭借其模块化架构和对互操作性的关注,Rome 解决了当今区块链面临的关键挑战,为下一代区块链应用创建了一个强大、适应性强且用户友好的环境。
罗马协议不仅仅是一个技术解决方案,也是迈向更加集成、高效的区块链生态系统的基础性一步——在这个生态系统中,交易、数据和应用程序可以轻松地跨链流动。
参考文献和资源
- 罗马议定书官方文件
- 罗马议定书网站
- 罗马议定书官方X帐号
- 罗马协议 Discord 服务器
- Solana 开发者资源
- 以太坊开发者资源
- EVM 兼容区块链
- L2 区块链上的排序器终极指南
- [模块化和单片区块链](https://celestia.org/learn/basics-of-modular-blockchains/modular-and-monolithic-blockchains/#:~:text=Modular blockchains,-The framework behind&text=A design is modular if,of trying to do everything.)
- 什么是区块链互操作性
- 什么是 Roll Up
- DeFi 中的可组合性是什么
- 区块链中的原子性是什么?为什么它很重要?
原文:https://medium.com/@tempestgirl1/solana-ethereum-the-rome-protocol-bridge-4498227dbafa
使 Solana 用户能够访问在 Solana 上运行的 EVM dApp
随着本白皮书的发布,Neon EVM 引入了多项功能,以统一 Solana 与部署在 Neon 上的 EVM dApp 之间的用户体验。此版本遵循Solana 网络扩展方法中描述的愿景,并描述了 Neon EVM 基础设施的发展方式。
本文描述的概念将会在 SDK 中实现,具体如下:
- Solana 签名支持:使 Solana 用户能够使用他们现有的 Solana 钱包签署 Neon EVM 交易,从而无需 EVM 签名和钱包。
- 链上内存池:引入链上系统,无需依赖外部工具即可高效地安排和执行 Neon EVM 交易。
- 关联 Neon 账户:创建抽象 Solana 地址的 Neon 账户,并实现 Solana 用户和 Neon EVM 之间的无缝交互。
- Neon 交易的受控树:实现交易的原子和并行执行方法,管理状态变化并聚合复杂交互的结果。
- 基于意图的执行:提供一种处理交易意图的机制,尽管 Solana 存在局限性,但仍能提高 EVM 合约和 Solana 程序之间的互操作性。
点击此处阅读完整白皮书
挑战:为 Solana 用户解锁以太坊 dApp
Solana 和以太坊是领先的 L1 区块链之一,各自都拥有活跃的 dApp 生态系统和性能优势。然而,这两个环境尚未相互交互,主要是由于编程语言、开发工具和基础设施的差异。
虽然 Neon EVM 允许 EVM dApp 为类似以太坊的用户访问 Solana 代币,但之前的解决方案涉及多个钱包的管理。在 Neon EVM 上执行交易需要使用 secp256k1 椭圆曲线的 EVM 签名,因此必须使用 MetaMask 等 EVM 钱包。这一要求对习惯于 Solana 中使用的 ed25519 签名的 Solana 用户以及无法使用 Phantom、Backpack 和 Solflare 等 Solana 钱包的用户来说是一个重大障碍。
通过下面提出的解决方案,EVM 开发人员可以通过减少碎片化和简化入职培训来原生地利用 Solana 用户群。
探索“Solana-Native”功能
白皮书介绍了 Solana 的各种原生功能。需要关注的五个关键功能包括:
Neon EVM 中的 Solana 签名支持
为了消除 Solana 用户管理额外 EVM 钱包的需要,Neon EVM 修改了其交易验证流程以接受 Solana 的 ed25519 签名。此修改包括:
- 签名验证适配:调整 Neon EVM 以识别和验证 ed25519 签名。
- 自定义交易类型:利用交易类型属性定义与 Solana 签名兼容的自定义交易类型,并遵守 EIP-2718 的类型化交易信封。
从技术上讲,Solana 用户的 EVM 地址 (ethAddress) 是使用 Keccak-256 哈希函数应用于 Solana 公钥 (solanaPublicKey) 得出的。地址派生公式为:
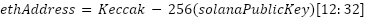
此方法采用哈希的最后 20 个字节来形成与 EVM 兼容的地址,从而确保唯一且抗冲突的映射。然后使用 Neon EVM 中的 Solana 原生加密库来验证 Solana 签名,从而确保安全验证。
好处
- Solana 用户可以使用现有的 Solana 钱包(例如 Phantom/Backpack/Solflare)签署 Neon 交易。此集成减少了用户与 Solana 上的 EVM dApp 交互所需的步骤,并将资产保留在熟悉的 Solana 钱包环境中。
- 使用 Solana 钱包无需转移资金,只需将 SOL 用作 gas 代币和 Solana 网络 RPC。从用户的角度来看,资产交换是通过发送 SPL 代币并接收所选资产的 SPL 代币来执行的。
创建关联 Neon 账户,统一资产管理
Neon EVM 通过整合 Solana 和 Neon EVM 生态系统来解决流动性分散问题,使用户能够与兼容 EVM 的 dApp 进行交互,而无需进行不必要的资产转移。以前,用户依靠 NeonPass 将 SPL 代币从 Solana 钱包转移到 Neon EVM 账户,这使资产管理变得复杂,流动性也变得分散。现在,随着 ERC20forSPL 合约的引入,这一过程得到了简化,该合约无缝连接了两个生态系统。
拥有 Solana 钱包的用户通过关联代币账户 (ATA) 管理其 SPL 代币。Neon EVM 使用 Keccak-256 哈希将其 Solana 公钥映射到与 EVM 兼容的地址,从而创建一个关联的 Neon 账户,其中包含与 EVM 兼容的地址、Solana 公钥、交易计数器、链标识符和内部余额的字段。
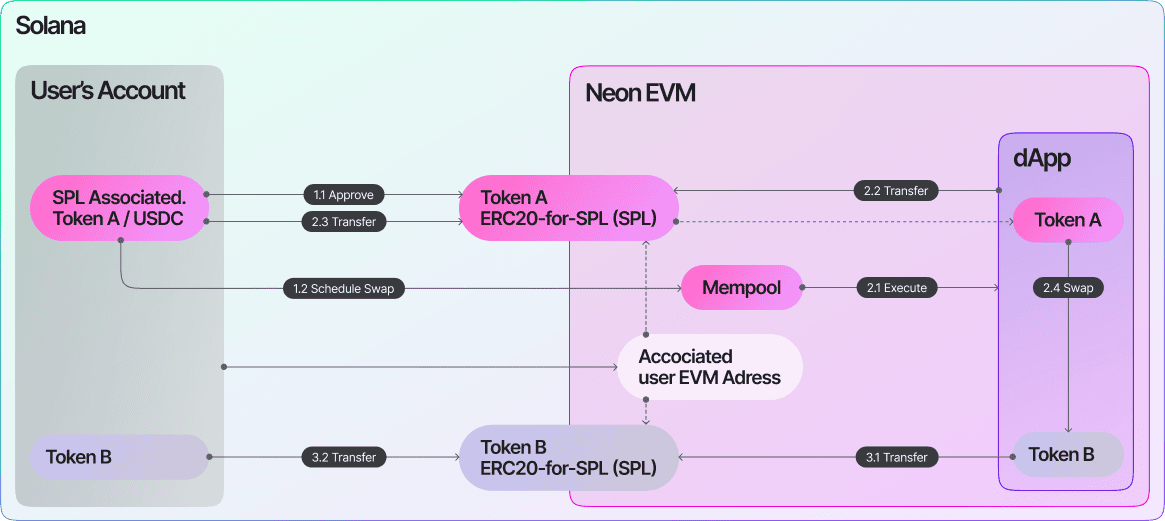
当用户与 Neon EVM 上的 dApp 交互时,ERC20forSPL 合约首先检查其内部余额。如果余额不足,它会查询 Solana 上用户的 ATA 以检索必要的 SPL 代币。此过程消除了 NeonPass 转账的需要,并允许用户在 Neon EVM 中操作,同时将资产保留在 Solana 上。
好处
- 简化资产管理:用户可以控制其 Solana 钱包中的资产,而无需中间转账(例如通过 NeonPass)。
- 降低交易成本:通过利用链上余额查询并避免冗余传输,用户在与 EVM dApp 交互时可以降低成本。
使用链上内存池实现高效的交易管理
高效的交易调度和执行管理对于流畅的用户体验至关重要。Neon EVM 实现了链上内存池来存储和管理已调度的 Neon 交易。这允许 Solana 用户直接从他们的 Solana 钱包调度 Neon EVM 交易,Neon 代理会代表他们检测和执行这些交易。
TreeAccount 是一个专用帐户,具有预定的 Neon 交易、余额和执行状态。它包括以下内容:
- 付款人的 EVM 地址:与 Solana 用户关联的 EVM 地址。
- 最后一个槽位:修改帐户的最后一个 Solana 槽位。
- 链 ID:链命名空间的标识符。
- Gas Limits:允许执行的最大气体量。
- 余额:为执行交易而保留的资金。
- 交易清单:预定的 Neon 交易及其执行详情。
交易调度协议涉及用户向 Neon EVM 程序提交 Neon EVM 交易,该程序会验证并将其添加到链上内存池中。然后,Neon 代理会监控内存池并相应地执行交易。
对于超出 Solana 大小限制的较大交易,只有交易哈希存储在链上,完整交易会发送到链下 Neon 代理。这种方法可以实现可扩展性并高效处理较大的交易,而不会影响网络性能。
好处
链上内存池增强了可扩展性,确保了交易完整性,并保持了状态更改的原子性。用户受益于高效的交易管理,开发人员可以利用此系统创建更复杂、响应更快的 dApp
用于复杂交互的受控事务树
为了克服 Solana 的即时状态应用和对交易还原的缺乏支持(这阻碍了 EVM 合约和 Solana 程序之间的复杂交互),Neon EVM 引入了 Neon 交易的受控树。该机制通过在树结构中组织交易来管理复杂的交互场景,其中每个节点代表一个 Neon 交易,父子关系定义执行依赖关系。
主要特点包括:
- 原子交易:每个 Neon 交易都是原子的,在完成时存储状态变化。
- 并行执行:没有依赖关系的事务可以并行执行,优化性能。
- 结果聚合:合约可以生成多个交易,并在后续交易中聚合结果。
好处
- 这项创新使开发人员能够构建更复杂、更集成的应用程序,通过实现受控状态变化的原子和并行执行来克服限制。
- 它可以增强交互的稳健性,并通过防止由于单个错误而导致的整个交易失败来改善用户体验。
基于意图的条件交易执行
Neon EVM 采用了意图驱动执行,为用户和开发者提供了根据特定条件或市场状态执行交易的灵活性。意图被定义为指定执行条件的简单 EVM 代码,遵守静态调用规则(不能修改状态)。Neon 代理会在执行交易之前评估这些意图。如果条件不满足,则跳过交易,用户无需支付任何费用。
此功能可以实现:
- 自动交易策略:仅当市场条件满足特定标准时才执行交易。
- 条件操作:当链上发生特定事件时执行诸如代币交换之类的操作。
好处
基于意图的执行可以更好地控制交易执行,提高资源效率,并减少用户不必要的成本。它增强了 dApp 对实时情况的灵活性和响应能力。

结论
征求反馈和协作:这份白皮书启动了 Neon EVM 的 Solana 原生演进,寻求不同视角的意见,并促进以太坊和 Solana 社区的开发者参与。
在这里,我们发布了第一稿,并邀请构建者社区积极贡献并开始评估您 dApp 上的实施情况。白皮书可在此处访问。
白皮书的第一个功能——即将发布的 Solana 签名钱包 SDK——已付诸实践。Solana 签名功能在 EVM 端已完成,并在代理端部分实现——目前正在测试和审核中。此外,敬请期待即将发布的用例和演示版本!
加入我们,在 Solana 上构建 dApp 的未来。立即探索 Neon EVM!
关于 Neon EVM
Neon EVM 是同类产品中的第一个,是 Solana 上的网络扩展,旨在将以太坊虚拟机 (EVM) 兼容性无缝集成到 Solana 的高性能生态系统中。通过在 Solana 的基础层内本地运行,Neon EVM 为以太坊开发人员提供了一种快速、高吞吐量的途径,可以在 Solana 上部署他们的 EVM dApp,而无需用 Rust 重写他们的合约。
有关 Neon EVM 和未来更新的更多信息,请访问neonevm.org并通过Twitter或Discord与社区联系。
原文:https://neonevm.org/blog/Enabling-Solana-Users-to-Access-EVM-dApps-Running-on-Solana
推出 Solana 签名 SDK:让 Solana 用户能够访问 EVM dApp
Solana Signature SDK 是一个以开发人员为中心的工具包,旨在将 Solana 钱包(例如 Phantom、Backpack 和 Solflare)集成到通过 Neon EVM 部署在 Solana 上的与以太坊兼容的 dApp 中。
关键要点
- 统一的用户体验:使用与 Solana 兼容的钱包以及与以太坊兼容的 dApp 进行交易签名。
- 技术创新:通过链上签名验证支持以太坊交易的 Solana 原生 ed25519 签名。
- 简化开发:通过 SDK 快速集成钱包和交易管理,几分钟内即可完成设置和功能。
- 生命周期透明度:从钱包到 Neon EVM 上执行的交易流程的详细概述。
- 高级功能:支持 Solana 程序调用、ERC20-SPL 资产管理和交易调度。
随着 Solana 签名钱包 SDK 的发布,我们朝着实现 Solana 原生集成和简化 Solana 环境中与以太坊兼容 dApp 的用户交互迈出了重要的变革一步,正如我们的白皮书中所强调的那样。
Neon EVM 和钱包集成简介
Solana 签名钱包 SDK 工具包使开发人员能够构建 dApp,使 Solana 用户能够与部署在 Neon EVM 上的智能合约进行交互。与以太坊兼容的 dApp 历来依赖类似以太坊的签名 (secp256k1) 进行交易身份验证。这种依赖关系为 Solana 用户带来了障碍,要求他们使用 MetaMask 等其他工具并进行复杂的流动性转移。Solana 签名钱包 SDK 与 Neon Proxy 一起解决了这个问题。通过匹配 Solana 的 ed25519 签名方案和以太坊的交易要求,此 SDK 简化了钱包集成和跨生态系统的资产可访问性。
从本质上讲,此 SDK 简化了交易管理,如下所示:
- 在 Solana 钱包内创建 EVM 交易。
- 通过 Neon EVM 的链上内存池打包并提交交易
- 通过 Neon Proxy 执行和状态管理
- Neon 和 Solana 的状态更新。
通过抽象交易转换的复杂性并增强两个网络之间的兼容性,它允许开发人员专注于构建和与去中心化应用程序(dApps)交互,而不必担心底层基础设施障碍。
让我们深入了解细节、技术概述、代币管理流程、优势、局限性和未来前景。
Solana 签名钱包 SDK 详细概述
Neon EVM Solana 签名钱包 SDK 是一种模块化且灵活的解决方案,旨在使开发人员和用户受益。
好处:
对于用户
- 简化的体验:使用现有的 Solana 钱包与与以太坊兼容的 dApp 进行交互。
- 降低复杂性:无需额外的钱包或复杂的流动性转移。
对于开发人员
- 快速集成:通过全面的 SDK 工具简化钱包连接和交易工作流程。
- 生态系统兼容性:构建适合 Solana 和以太坊用户的 dApp,无需额外的开发开销。
Solana 签名验证:功能
Neon EVM Solana 签名钱包 SDK 的一个突出功能是它能够使用 Solana 的 ed25519 签名系统验证 Solana 交易。这一增强功能对于确保通过 Solana 钱包(例如 Phantom、Solflare 和 Backpack)发起的交易在 Neon EVM 网络上准确、安全地处理至关重要。
验证过程在 Neon Proxy 中实时进行,它会在 Neon EVM 上执行任何交易之前检查 Solana 签名的真实性。通过原生验证 Solana 的 ed25519 签名,Neon Proxy 无需手动验证签名或使用中间层。这意味着交易可以安全地处理,延迟最少,确保每笔交易都经过身份验证并正确记录。
这种实时验证机制对于 Solana 钱包用户直接与部署在 Neon EVM 上的与以太坊兼容的 dApp 交互至关重要,而无需单独的身份验证方法或 MetaMask 等附加工具。
对于 SDK,为确保流畅的用户体验,两个关键关注领域包括:
- 通过 Neon Proxy 实现的技术功能;
- 使用 ERC20ForSPL 管理进行资产管理,用于以太坊和 Solana 网络之间的代币转移。
继续阅读,了解 Neon Proxy 如何支持这一点,以及 ERC20ForSPL 合约如何管理 Solana 和以太坊兼容环境之间的代币余额和转移。
Neon Proxy 变更:增强基础设施功能
Neon Proxy 对于促进交互至关重要。它将类似以太坊的交易打包到 Solana 交易中,消除了实现转换逻辑的负担。代理架构的最新更新引入了新功能,优化了交易处理,并确保与现有系统的兼容性,同时整合了 Solana 签名基础设施。
Solana 签名 SDK 的关键代理增强功能
- Solana 签名验证: Neon Proxy 现在可以验证 Solana 的 ed25519 签名,使 Solana 钱包(Phantom、Backpack、Solflare 等)能够直接向 Neon EVM 签名并提交交易。这消除了中间层,简化了流程并确保了安全性。
- 链上内存池集成:借助链上内存池支持,Solana 钱包交易可以在 Neon EVM 生态系统中透明高效地存储、验证和执行。这一改进增强了可扩展性,并消除了对交易调度链下操作的依赖。
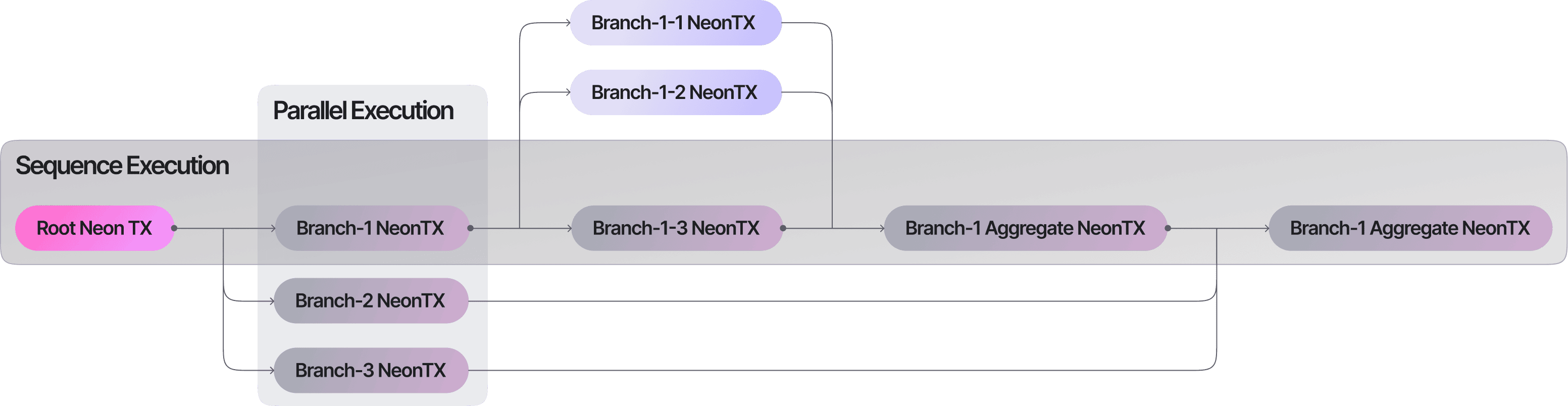
为了实现链上内存池,Neon 引入了NeonTxs 树的概念。这将单个大交易拆分为更小、可管理的单元(NeonTxs),同时保持整体逻辑。
工作原理
-
交易树:
Neon 合约创建了一个交易“树”,其中较小的单元(分支)可以独立执行。
每个交易都是原子的,这意味着只有交易成功完成,其变化才会生效。 -
并行执行:
独立交易可以并行运行,从而加快进程。 -
错误处理:
如果树中的一个交易失败,它不会破坏整个过程。Neon 合约的逻辑可以决定如何处理失败。 -
最终聚合:
树中的所有交易完成后,它们的结果将被组合(聚合)成最终交易。
使用 Solana 签名 SDK 的代理工作流
-
交易创建:
Solana 用户通过使用 Solana Signature SDK 通过他们的原生钱包(Phantom、Backpack、Solflare)对交易进行签名来发起交易。
交易通过SDK打包成Neon兼容的格式并发送给Neon Proxy。 -
链上调度和映射:
Neon Proxy 将用户的 Solana 钱包地址映射到与以太坊兼容的地址,确保与 Neon EVM 上基于以太坊的智能合约正确集成。
该交易在 Neon EVM 内存池中链上调度,等待执行。 -
交易执行:
Neon Proxy 扫描内存池以查找预定的交易,并使用 Solana 的 ed25519 签名来验证它们。
该交易在 Neon EVM 上执行,触发智能合约交互并更新 Solana 和 Neon 网络上的状态。 -
执行后清理:
Neon Proxy 通过清理临时资源来确保高效的系统维护,从而优化未来的交易。
虽然 Neon Proxy 可以作为 Solana 钱包和 Neon EVM 生态系统之间交互的推动者,但要充分发挥市场潜力,需要消除资产管理碎片化。跨网络的统一资产管理是推动采用和更集成的用户体验的关键。
ERC20ForSPL 更新:统一代币管理
SDK 的主要功能是其完善的 ERC20ForSPL 合约逻辑,解决了以太坊和 Solana 之间的互操作性挑战。合约通过使 ERC-20 代币能够在 Solana 环境中运行来连接两个网络。重点是完善 ERC20ForSPL 合约逻辑,以统一余额、保持向后兼容性并为开发人员引入强大的工具。具体方法如下:
统一余额管理
- PDA 和 ATA 集成:Neon EVM 目前使用程序派生地址 (PDA) 来管理余额。随着关联代币账户 (ATA) 使用的实施,合约将整合这两个关键 Solana 组件,以统一的方式管理余额。
- 转账优先级:在转账时,合约优先使用PDA余额,如果PDA余额不够,则使用ATA余额。
- 消除碎片化:这种统一使得代币管理变得更简单、更少碎片化,为用户提供统一的代币管理体验。
这里的传输逻辑很简单:
- 收件人地址验证:在发送代币之前,合约会检查收件人的地址是否与以太坊(EVM)兼容,并确保他们的 ATA(Solana 版本的钱包)已初始化。
- 有条件传输:如果 ATA 已准备就绪,令牌将发送到那里。如果没有,则默认将令牌发送到 PDA。
- 综合余额视图:balanceOf方法现在提供PDA和ATA余额的统一视图,确保准确反映用户的总持有量。
向后兼容性和安全性
虽然 ERC20ForSPL 合约已经更新,但保持向后兼容性(确保现有实现继续不中断地运行)同时添加新功能以增强功能仍然至关重要。
为此,合约通过保留状态变量、方法签名和事件参数来保持与现有实现的兼容性。它在 0xFf000000000000000000000000000000000000000000007 下引入了新的预编译方法,增强了开发人员的能力。isSolanaUser 确定 EVM 地址是否对应于 Solana 帐户,而 solanaAddress 检索与 EVM 地址关联的 Solana 公钥。
构建器预览:使用 SDK 创建的 Neon 交易的生命周期

步骤 1:在前端创建交易
- 使用 ethers.js、web3.js 或任何其他工具创建 Neon EVM 交易。
- 使用 Native Wallet SDK 将交易打包成 Solana 交易,通过 Neon Proxy 获取必要的元数据。
- (可选):添加 Solana 资产审批说明,以便 Neon EVM 智能合约直接访问。
步骤 2:Solana 钱包签署并提交交易
- dApp 前端将打包的交易发送到用户的 Solana 钱包。
- 用户通过其钱包 UI 审查并签署交易。
- 钱包将签名的交易提交给 Solana 网络,并将其安排在 Neon 的链上内存池中。
步骤 3:Neon Proxy 执行预定交易
- Neon Proxy 扫描链上内存池并识别准备执行的交易。
- 在 Neon EVM 上执行交易,从而导致 Neon 和 Solana 上的状态更新。
- 执行后从内存池中删除交易。
开始使用 SDK
访问存储库:深入研究GitHub上的 Neon Solana Signature SDK 。
开发人员文档:探索全面的文档。
社区开发者支持:加入我们的Discord。查看 Discord 开发频道以获取实时帮助,并寻求我们仅限邀请的 Telegram Builder 聊天访问权限。
原文:https://neonevm.org/blog/unveiling-solana-signature-sdk-enabling-solana-users-to-access-evm-dapps
Solana 部署bigtable持久化数据节点
安装 gcloud CLI
sudo apt-get update
sudo apt-get install apt-transport-https ca-certificates gnupg curl
curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo gpg --dearmor -o /usr/share/keyrings/cloud.google.gpg
echo "deb [signed-by=/usr/share/keyrings/cloud.google.gpg] https://packages.cloud.google.com/apt cloud-sdk main" | sudo tee -a /etc/apt/sources.list.d/google-cloud-sdk.list
sudo apt-get update && sudo apt-get install google-cloud-cli启用IAM API
https://cloud.google.com/iam/docs/keys-create-delete?hl=zh-cn&cloudshell=true
注意:选择对应的项目,然后启用API

创建实例
实例ID和实例名称都设置为solana-ledger

创建密钥
新tab打开服务账号

点击创建服务账号
输入服务信息

点击创建并继续
选择Bigtable User

点击继续
最后一步可选,直接点击完成
创建密钥
刚新建完,是没有密钥的

点击该行最右侧的操作,管理密钥

添加键->创建新密钥

选择JSON格式

直接会弹出保存对话框,选择自己本地路径进行保存
例如名称为:bcskill-testnet-rpc-storage-93984f743890.json
创建数据表
blocks,entries,tx,tx-by-addr
创建完,挨个添加列族,列族名称都为x,基于版本的政策: 版本上限5
初始化
gcloud init等待一段时间
Network diagnostic detects and fixes local network connection issues.
Checking network connection...done.
Reachability Check passed.
Network diagnostic passed (1/1 checks passed).
You must sign in to continue. Would you like to sign in (Y/n)?
Go to the following link in your browser, and complete the sign-in prompts:
https://accounts.google.com/o/oauth2/auth?response_type=c......然后将上面的链接,复制到浏览器中,通过对应的谷歌账号进行登录,授权后,将返回的Key,输入到终端里
然后选择对应的实例
You are signed in as: [c..@gmail.com].
Pick cloud project to use:
[1] august-outlet-389809
[2] bpay-2204b
[3] ethereal-fort-389810
[4] g-gcp-202408-01
[5] infinite-alcove-389904
[6] sturdy-web-389809
[7] Enter a project ID
[8] Create a new project
Please enter numeric choice or text value (must exactly match list item): 4gcloud config configurations listNAME IS_ACTIVE ACCOUNT PROJECT COMPUTE_DEFAULT_ZONE COMPUTE_DEFAULT_REGION
default True c...@gmail.com g-gcp-202408-01mkdir ./config
mkdir -p ./data/accounts
mkdir ./logs./solana-keygen new -o ./config/identity.jsonexport GOOGLE_APPLICATION_CREDENTIALS=./config/bcskill-testnet-rpc-storage-93984f743890.json
./agave-validator \
--ledger ./data \
--identity ./config/identity.json \
--entrypoint 172.18.39.93:8001 \
--dynamic-port-range 9000-9020 \
--only-known-rpc \
--known-validator Fc9UXBuQyMYBow5fTwgrYQf4k1Pwqx8o53yYBuvFQmnc \
--allow-private-addr \
--enable-rpc-transaction-history \
--rpc-port 8896 \
--private-rpc \
--log ./logs/agave-validator.logs \
--no-voting \
--wal-recovery-mode skip_any_corrupted_record \
--limit-ledger-size \
--enable-bigtable-ledger-upload \
--enable-cpi-and-log-storage \
--accounts ./data/accounts \
--no-genesis-fetch \
--no-snapshot-fetch查看上传数据
tail -f logs/agave-validator.logs | grep -a 'bigtable'2024-12-16T06:31:21.663829260Z INFO solana_ledger::bigtable_upload] Preparing the next 3 blocks for upload
[2024-12-16T06:31:21.683000789Z INFO solana_metrics::metrics] datapoint: storage-bigtable-upload-block slot=1924269i transactions=1i entries=65i bytes=3050i
[2024-12-16T06:31:21.683031739Z INFO solana_metrics::metrics] datapoint: storage-bigtable-upload-block slot=1924270i transactions=1i entries=65i bytes=3050i
[2024-12-16T06:31:21.683641626Z INFO solana_metrics::metrics] datapoint: storage-bigtable-upload-block slot=1924271i transactions=1i entries=65i bytes=3049i
[2024-12-16T06:31:21.683647257Z INFO solana_ledger::bigtable_upload] Upload took 19ms for 3 blocks
[2024-12-16T06:31:21.683659731Z INFO solana_ledger::bigtable_upload] entire upload took 29ms
[2024-12-16T06:31:21.683872194Z INFO solana_ledger::bigtable_upload] blockstore upload took 2.205029ms for 3 blocks (1360.53 blocks/s) errors: 0
[2024-12-16T06:31:22.683968514Z INFO solana_ledger::bigtable_upload] Loading ledger slots from 1924272 to 1924274
[2024-12-16T06:31:22.684083929Z INFO solana_ledger::bigtable_upload] Found 3 slots in the range (1924272, 1924274)
[2024-12-16T06:31:22.684093327Z INFO solana_ledger::bigtable_upload] Loading list of bigtable blocks between slots 1924272 and 1924274...
[2024-12-16T06:31:22.684136962Z INFO solana_metrics::metrics] datapoint: bigtable_blocks read_rows=1i
[2024-12-16T06:31:22.689038044Z INFO solana_ledger::bigtable_upload] 3 blocks to be uploaded to the bucket in the range (1924272, 1924274)
常见排查
查看日志错误
tail -f logs/agave-validator.logs | grep -a 'ERROR'https://github.com/solana-labs/solana-bigtable
https://docs.anza.xyz/implemented-proposals/rpc-transaction-history/
最新文章
Solana基础 - Solana RPC HTTP 方法solana 交易 confirmationStatus 有几种状态Solana RPC 方法的常见 JSON 数据结构使用 spl-token 命令行工具测试Solana代币发行 error: rustc 1.79.0-dev is not supported by the following package:Solana基础 - 十分钟开始使用多签工具SQUADSSolana基础 - 给EVM开发者的 Solana开发指南Solana基础 - 在 Anchor 中的跨程序调用(CPI)Solana基础 - 在链上读取另一个锚点程序账户数据Solana基础 - 在 Anchor 中:不同类型的账户
最新回复
fzd: 请问这个解决了吗
StarkWare explained: layer 2 solution provider of dYdX and iMMUTABLE R11; BitKeep News: [...]Layer 2: https://...
一文读懂 StarkWare:dYdX 和 Immutable 背后的 L2 方案 R11; BitKeep 博客: [...]Layer 2:Comparing Laye...
http://andere.strikingly.com/: Regards, Great stuff!
surou: 需要先执行提案合约申请,等待出块节点地址同意后,才会进...
heco: WARN [11-19|11:26:09.459] N...
P: 你好,我在heco链上遇到了“tx fee excee...
Peng: 楼主安装成功了吗?我正在同步区块链,一天了,差不多才同...
joyhu: 你好,请问下安装好之后如何获取到bee.yaml配置文...
kaka: 支票最终怎么提币呢?
归档
March 2025February 2025January 2025December 2024November 2024October 2024September 2024August 2024July 2024June 2024May 2024April 2024March 2024January 2024December 2023November 2023October 2023September 2023August 2023July 2023June 2023April 2023March 2023February 2023January 2023December 2022November 2022October 2022August 2022July 2022June 2022May 2022March 2022February 2022January 2022December 2021November 2021October 2021September 2021August 2021July 2021June 2021May 2021April 2021March 2021February 2021January 2021December 2020November 2020October 2020September 2020July 2020June 2020May 2020April 2020March 2020February 2020January 2020December 2019November 2019October 2019September 2019August 2019July 2019June 2019May 2019April 2019March 2019February 2019January 2019December 2018November 2018October 2018September 2018August 2018July 2018June 2018