解构Solidity合约 #1 - 字节码
专栏 理解 EVM - 探究Solidity 背后的秘密 继续加入OpenZepplin 解构合约系列文章。
你在路上,开着你那辆罕见的、完全修复的1969年野马马赫1快速行驶。阳光照射在所有原始的、华丽的镀金轮辋上,闪闪发光。只有你,道路,沙漠,以及对地平线的无尽追逐。完美无缺!
眨眼间,你的335马力的野兽被白烟吞没,仿佛变成了一个蒸汽机车,你被迫停在路边。带着决心,你打开引擎盖,才意识到你完全不知道自己在看什么。这台该死的机器是如何工作的?你抓住你的手机,发现你没有信号。
如果这听起来很熟悉,那么不用担心!本系列文章的目的是为了让你了解你的合约。我们将解构一个简单的 Solidity 合约,查看它的字节码,并将其分解为可识别的结构,直至最低层。我们将揭开 Solidity 的盖子。在本系列结束时,你在查看或调试EVM字节码时应该感到熟悉。这个系列的全部意义在于揭开由 Solidity 编译器产生的 EVM 字节码的神秘面纱。而且它真的比看起来要简单得多。
注意:这个系列的目的是针对那些已经熟悉 Solidity 合约开发有经验的开发者,但想了解事情是如何在一个稍深/较底层的工作 - 即 Solidity 编译器如何将 Solidity 翻译成 EVM 的字节码,以及 EVM 如何执行这种字节码。如果你还没到那一步,我推荐你阅读Solidity 合约开发专栏
下面是我们要解构的合约:
pragma solidity ^0.4.24;
contract BasicToken {
uint256 totalSupply_;
mapping(address => uint256) balances;
constructor(uint256 _initialSupply) public {
totalSupply_ = _initialSupply;
balances[msg.sender] = _initialSupply;
}
function totalSupply() public view returns (uint256) {
return totalSupply_;
}
function transfer(address _to, uint256 _value) public returns (bool) {
require(_to != address(0));
require(_value <= balances[msg.sender]);
balances[msg.sender] = balances[msg.sender] - _value;
balances[_to] = balances[_to] + _value;
return true;
}
function balanceOf(address _owner) public view returns (uint256) {
return balances[_owner];
}
}
注意:这个合约很容易受到溢出攻击的影响,但我们在这里只是为了手头的工作而保持简单。
编译合约
为了编译合约,我们将使用Remix。点击文件浏览区上方左上角的+按钮,创建一个新的合约。将文件名设为BasicToken.sol。现在,将上述代码粘贴到编辑器部分。
在左侧编译 Tab部分,进入编译设置,确保选择了启用优化。另外,确认所选的Solidity编译器的版本是: "0.4.24+commit.e67f0147"。这两个细节非常重要,否则你将会看到与这里讨论的略有不同的字节码。
如果你进入Compile标签并点击Bytecode按钮,会复制Solidity编译器生成的所有东西,其中之一是一个名为BYTECODE的JSON对象,它有一个 "object "属性,是合约的编译代码。它看起来像这样:
608060405234801561001057600080fd5b5060405160208061021783398101604090815290516000818155338152600160205291909120556101d1806100466000396000f3006080604052600436106100565763ffffffff7c010000000000000000000000000000000000000000000000000000000060003504166318160ddd811461005b57806370a0823114610082578063a9059cbb146100b0575b600080fd5b34801561006757600080fd5b506100706100f5565b60408051918252519081900360200190f35b34801561008e57600080fd5b5061007073ffffffffffffffffffffffffffffffffffffffff600435166100fb565b3480156100bc57600080fd5b506100e173ffffffffffffffffffffffffffffffffffffffff60043516602435610123565b604080519115158252519081900360200190f35b60005490565b73ffffffffffffffffffffffffffffffffffffffff1660009081526001602052604090205490565b600073ffffffffffffffffffffffffffffffffffffffff8316151561014757600080fd5b3360009081526001602052604090205482111561016357600080fd5b503360009081526001602081905260408083208054859003905573ffffffffffffffffffffffffffffffffffffffff85168352909120805483019055929150505600a165627a7a72305820a5d999f4459642872a29be93a490575d345e40fc91a7cccb2cf29c88bcdaf3be0029
是的,这是完全不可读的(至少对一个正常人来说)。
部署合约
接下来,进入Remix中的DEPLOY & RUN部分。在顶部,确保你使用的是Remix VM。这基本上是一个嵌入式的Javascript EVM+ 网络,是我们理想的以太坊游乐场。确保BasicToken被选中,并在Deploy输入框中输入数字10000。接下来,点击部署按钮。这将部署一个BasicToken合约的实例,初始发行量为10000个代币,由顶部当前选择的账户拥有,它将持有我们的代币发行总量。
在部署的合约部分,你应该看到已部署的合约,并有字段与它的三个功能交互:transfer、balanceOf 和 totalSupply。在这里,我们将能够与我们刚刚部署的合约的实例进行交互。
但在此之前,让我们看看 "部署 "合约到底意味着什么。在控制台区域,你应该看到日志 "create of BasicToken pending...",然后是一个带有各种字段的交易条目:from、to、value、data、logs和 hash。点击这个条目来扩展交易的信息。即使是缩写,你也应该看到该交易的 input 数据是我们上面介绍的相同的字节码(加上参数)。这个交易被发送到0x0地址,结果是,一个新的合约实例被创建,有它自己的地址和代码。我们将在下一篇文章中详细研究这个过程.
拆解字节码
在交易数据的右边,仍然在控制台中,点击Debug(调试)按钮。这将激活Remix右侧区域的调试器标签。让我们来看看指令部分。如果你向下滚动,你应该看到以下内容。
000 PUSH1 80
002 PUSH1 40
004 MSTORE
005 CALLVALUE
006 DUP1
007 ISZERO
008 PUSH2 0010
011 JUMPI
012 PUSH1 00
014 DUP1
015 REVERT
016 JUMPDEST
017 POP
018 PUSH1 40
020 MLOAD
021 PUSH1 20
023 DUP1
024 PUSH2 0217
027 DUP4
028 CODECOPY
029 DUP2
030 ADD
031 PUSH1 40
033 SWAP1
034 DUP2
035 MSTORE
036 SWAP1
037 MLOAD
038 PUSH1 00
040 DUP2
041 DUP2
042 SSTORE
043 CALLER
044 DUP2
045 MSTORE
046 PUSH1 01
048 PUSH1 20
050 MSTORE
051 SWAP2
052 SWAP1
053 SWAP2
054 SHA3
055 SSTORE
056 PUSH2 01d1
059 DUP1
060 PUSH2 0046
063 PUSH1 00
065 CODECOPY
066 PUSH1 00
068 RETURN
069 STOP
070 PUSH1 80
072 PUSH1 40
074 MSTORE
075 PUSH1 04
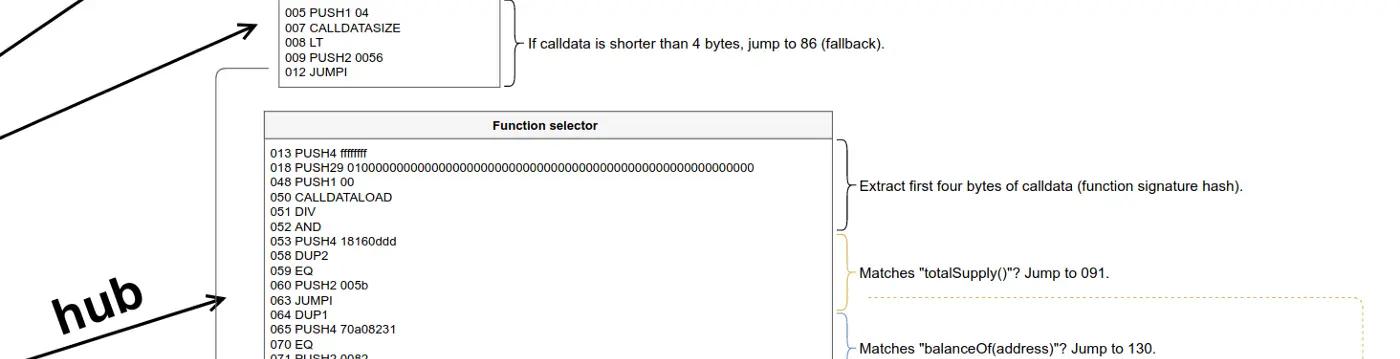
077 CALLDATASIZE
078 LT
079 PUSH2 0056
082 JUMPI
083 PUSH4 ffffffff
088 PUSH29 0100000000000000000000000000000000000000000000000000000000
118 PUSH1 00
120 CALLDATALOAD
121 DIV
122 AND
123 PUSH4 18160ddd
128 DUP2
129 EQ
130 PUSH2 005b
133 JUMPI
134 DUP1
135 PUSH4 70a08231
140 EQ
141 PUSH2 0082
144 JUMPI
145 DUP1
146 PUSH4 a9059cbb
151 EQ
152 PUSH2 00b0
155 JUMPI
156 JUMPDEST
157 PUSH1 00
159 DUP1
160 REVERT
161 JUMPDEST
162 CALLVALUE
163 DUP1
164 ISZERO
165 PUSH2 0067
168 JUMPI
169 PUSH1 00
171 DUP1
172 REVERT
173 JUMPDEST
174 POP
175 PUSH2 0070
178 PUSH2 00f5
181 JUMP
182 JUMPDEST
183 PUSH1 40
185 DUP1
186 MLOAD
187 SWAP2
188 DUP3
189 MSTORE
190 MLOAD
191 SWAP1
192 DUP2
193 SWAP1
194 SUB
195 PUSH1 20
197 ADD
198 SWAP1
199 RETURN
200 JUMPDEST
201 CALLVALUE
202 DUP1
203 ISZERO
204 PUSH2 008e
207 JUMPI
208 PUSH1 00
210 DUP1
211 REVERT
212 JUMPDEST
213 POP
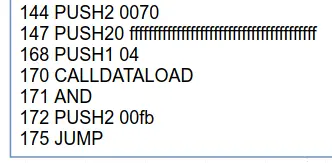
214 PUSH2 0070
217 PUSH20 ffffffffffffffffffffffffffffffffffffffff
238 PUSH1 04
240 CALLDATALOAD
241 AND
242 PUSH2 00fb
245 JUMP
246 JUMPDEST
247 CALLVALUE
248 DUP1
249 ISZERO
250 PUSH2 00bc
253 JUMPI
254 PUSH1 00
256 DUP1
257 REVERT
258 JUMPDEST
259 POP
260 PUSH2 00e1
263 PUSH20 ffffffffffffffffffffffffffffffffffffffff
284 PUSH1 04
286 CALLDATALOAD
287 AND
288 PUSH1 24
290 CALLDATALOAD
291 PUSH2 0123
294 JUMP
295 JUMPDEST
296 PUSH1 40
298 DUP1
299 MLOAD
300 SWAP2
301 ISZERO
302 ISZERO
303 DUP3
304 MSTORE
305 MLOAD
306 SWAP1
307 DUP2
308 SWAP1
309 SUB
310 PUSH1 20
312 ADD
313 SWAP1
314 RETURN
315 JUMPDEST
316 PUSH1 00
318 SLOAD
319 SWAP1
320 JUMP
321 JUMPDEST
322 PUSH20 ffffffffffffffffffffffffffffffffffffffff
343 AND
344 PUSH1 00
346 SWAP1
347 DUP2
348 MSTORE
349 PUSH1 01
351 PUSH1 20
353 MSTORE
354 PUSH1 40
356 SWAP1
357 SHA3
358 SLOAD
359 SWAP1
360 JUMP
361 JUMPDEST
362 PUSH1 00
364 PUSH20 ffffffffffffffffffffffffffffffffffffffff
385 DUP4
386 AND
387 ISZERO
388 ISZERO
389 PUSH2 0147
392 JUMPI
393 PUSH1 00
395 DUP1
396 REVERT
397 JUMPDEST
398 CALLER
399 PUSH1 00
401 SWAP1
402 DUP2
403 MSTORE
404 PUSH1 01
406 PUSH1 20
408 MSTORE
409 PUSH1 40
411 SWAP1
412 SHA3
413 SLOAD
414 DUP3
415 GT
416 ISZERO
417 PUSH2 0163
420 JUMPI
421 PUSH1 00
423 DUP1
424 REVERT
425 JUMPDEST
426 POP
427 CALLER
428 PUSH1 00
430 SWAP1
431 DUP2
432 MSTORE
433 PUSH1 01
435 PUSH1 20
437 DUP2
438 SWAP1
439 MSTORE
440 PUSH1 40
442 DUP1
443 DUP4
444 SHA3
445 DUP1
446 SLOAD
447 DUP6
448 SWAP1
449 SUB
450 SWAP1
451 SSTORE
452 PUSH20 ffffffffffffffffffffffffffffffffffffffff
473 DUP6
474 AND
475 DUP4
476 MSTORE
477 SWAP1
478 SWAP2
479 SHA3
480 DUP1
481 SLOAD
482 DUP4
483 ADD
484 SWAP1
485 SSTORE
486 SWAP3
487 SWAP2
488 POP
489 POP
490 JUMP
491 STOP
492 LOG1
493 PUSH6 627a7a723058
500 SHA3
501 INVALID
502 INVALID
503 SWAP10
504 DELEGATECALL
505 GASLIMIT
506 SWAP7
507 TIMESTAMP
508 DUP8
509 INVALID
510 INVALID
511 INVALID
512 SWAP4
513 LOG4
514 SWAP1
515 JUMPI
516 INVALID
517 CALLVALUE
518 INVALID
519 BLOCKHASH
520 INVALID
521 SWAP2
522 INVALID
523 INVALID
524 INVALID
525 INVALID
526 CALLCODE
527 SWAP13
528 DUP9
529 INVALID
530 INVALID
531 RETURN
532 INVALID
533 STOP
534 INVALID
535 STOP
536 STOP
537 STOP
538 STOP
539 STOP
540 STOP
541 STOP
542 STOP
543 STOP
544 STOP
545 STOP
546 STOP
547 STOP
548 STOP
549 STOP
550 STOP
551 STOP
552 STOP
553 STOP
554 STOP
555 STOP
556 STOP
557 STOP
558 STOP
559 STOP
560 STOP
561 STOP
562 STOP
563 STOP
564 STOP
565 INVALID
566 LT
为了确保你所遵循的是本系列中描述的同一套操作代码,请将你在Remix中看到的内容与本gist中的字节码进行比较。
这是合约的反汇编字节码。反汇编听起来挺吓人的,但其实很简单。如果你按字节扫描原始字节码(一次两个字符),EVM会识别出特定的操作码,并将其与特定的动作联系起来。比如说。
0x60 => PUSH
0x01 => ADD
0x02 => MUL
0x00 => STOP
...
拆解后的代码仍然非常低级,难以阅读,但正如你将看到的,我们可以开始对它进行理解。
操作码
在我们开始彻底解构字节码的雄心壮志之前,你将需要一套基本的工具来理解各个操作码,如PUSH、ADD、SWAP、DUP等。一个操作码,能进行的操作是从EVM的堆栈、内存或属于合约的存储中推入或消耗项目。
要查看EVM可以处理的所有可用的操作码,请查看EVM Codes。要了解每个操作码的作用和工作原理,Solidity的汇编文档是一个很好的参考。尽管它与原始操作码不是一对一的关系,但它非常接近(它实际上是Yul,Solidity和EVM字节码之间的一种中间语言)。最后,如果你讲究科学,总是有以太坊 Yellow Paper可以依靠。
现在从头到尾阅读这些资料是没有意义的;只是把它们放在身边作为参考。我们将在前进的过程中使用它们。
指令
上面拆解的代码中的每一行都是EVM要执行的指令。每条指令都包含一个操作码。例如,让我们来看看其中的一条指令,88号指令,它将数字4推到堆栈中。这个特殊的反汇编程序对指令的解释如下:
88 PUSH1 0x04
| | |
| | 要推入的值(16 进制)
| 指令
Instruction number.
尽管反汇编后的代码使我们更接近于理解正在发生的事情,但它仍然相当令人生畏。我们需要一个策略来解构整个代码,它有596条指令!我们需要一个策略来解构整个代码。
策略
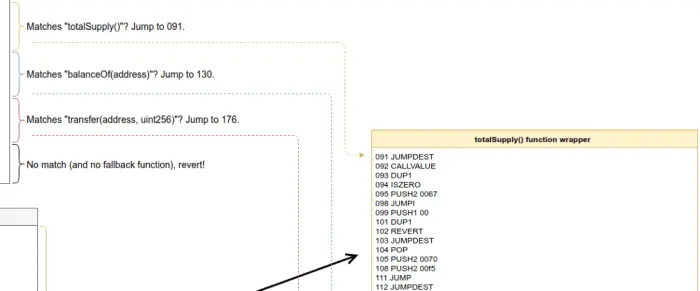
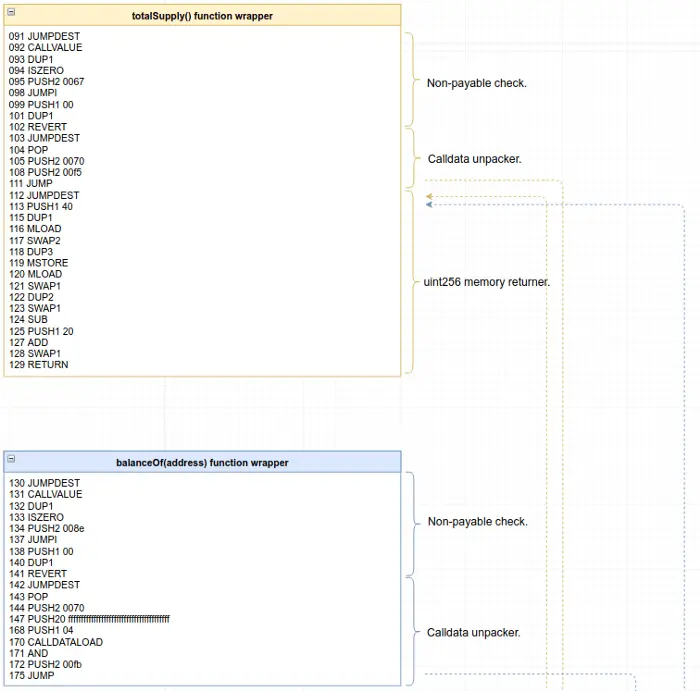
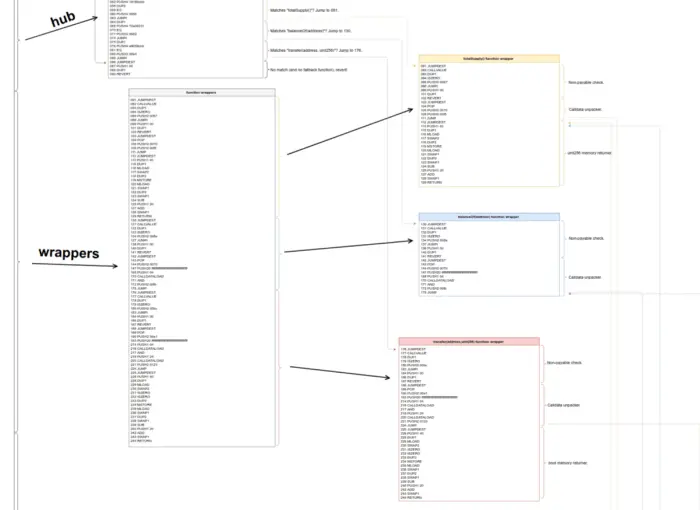
那些一开始就显得不堪一击的问题通常会屈服于全能的 "分而治之 "策略,这个问题也不例外。我们将在拆解后的代码中找出分割点,然后一点一点地减少,直到最后得到可消化的小块代码,我们将在Remix的调试器中一步一步地完成。在下图中,我们可以看到我们可以对反汇编的代码进行第一次分割,我们将在下一篇文章中对其进行全面分析。

你可以在解构图中找到整个解构的最终结果。如果你一开始不理解这张图,不要担心。你不应该这样做。这个系列会一步一步地看完它。把它放在身边,这样你就可以在我们进行的过程中保持对大局的跟踪。
Creation vs. Runtime
让我们开始用分而治之的光剑来攻击我们合约。正如我们在前面介绍所看到的,这些反汇编的代码是非常低级的,但与原始字节码相比是可读性好了很多。请确保你已经跟随前面的内容,并且你已经在Remix中编译和部署了BasicToken合约。调试创建交易,打开指令面板。另外,在我们进行的过程中,请准备好解构图。
现在,让我们专注于 "JUMP"、"JUMPI"、"JUMPDEST"、"RETURN "和 "STOP" 操作码,而忽略所有其他操作码。每当我们发现一个操作码不属于这些操作码时,我们将忽略它,并跳到下一条指令,假装没有任何干预。
当EVM执行代码时,它是自上而下执行的,没有任何例外--也就是说,代码没有其他入口点。它总是从顶部开始。它可以跳来跳去,是的,这正是JUMP和JUMPI的作用。JUMP从堆栈中获取最顶端的值,并将执行转移到该位置。但目标位置必须包含JUMPDEST操作码,否则执行会失败。这就是JUMPDEST的唯一目的:将一个位置标记为有效的跳转目标。JUMPI是完全相同的,但是在堆栈的第二个位置不能是 0,否则就不会有跳转。所以这是一个有条件的跳转。STOP完全停止了合约的执行,RETURN也停止了执行,但从EVM的一部分内存中返回数据,这很方便。
所以,让我们开始解释代码,记住所有这些。在Remix的调试器中,将交易滑块向左移动,查看指令部分。你可以用Step Into按钮(看起来像一个向下的小箭头的那个)来浏览这些指令。第一条指令可以忽略不计,但在第11条指令中我们发现了第一个 JUMPI。如果它不跳转,它将继续执行第12至15条指令,并以 REVERT 结束,这将停止执行。但是如果它跳转了,它将跳过这些指令到达16号位置(十六进制0x0010,在指令8中被推入堆栈)。指令16是一个JUMPDEST。到目前为止还不错。
继续浏览操作码,直到交易滑块一直向右移动。刚才发生了很多废话,但只有在第68个位置我们发现了一个 "RETURN" 操作码(还有一个 "STOP "操作码在指令69中,以备不时之需)。这是很奇怪的。如果你仔细想想,这个合约的控制流总是在指令15或68结束。我们刚刚浏览了一遍,确定没有其他可能的流程,那么剩下的指令是干什么用的呢?(如果你在指令面板下滑,你会看到代码在566位置结束)。
我们刚刚穿越的这组指令(0到69)就是所谓的合约的 "创建代码(creation code)"。它永远不会成为合约代码本身的一部分,而只是在创建合约的交易中由EVM执行一次。我们很快就会发现,这段代码负责设置创建的合约的初始状态,以及返回其运行时代码的副本。剩下的497条指令(70到566),正如我们所看到的,永远不会被执行流到达,正是将成为部署的合约的一部分的代码。
如果你打开解构图,你应该看到我们刚刚是如何进行第一次拆分:我们已经区分了创建时与运行时代码。
现在我们将深入研究代码的创建部分:
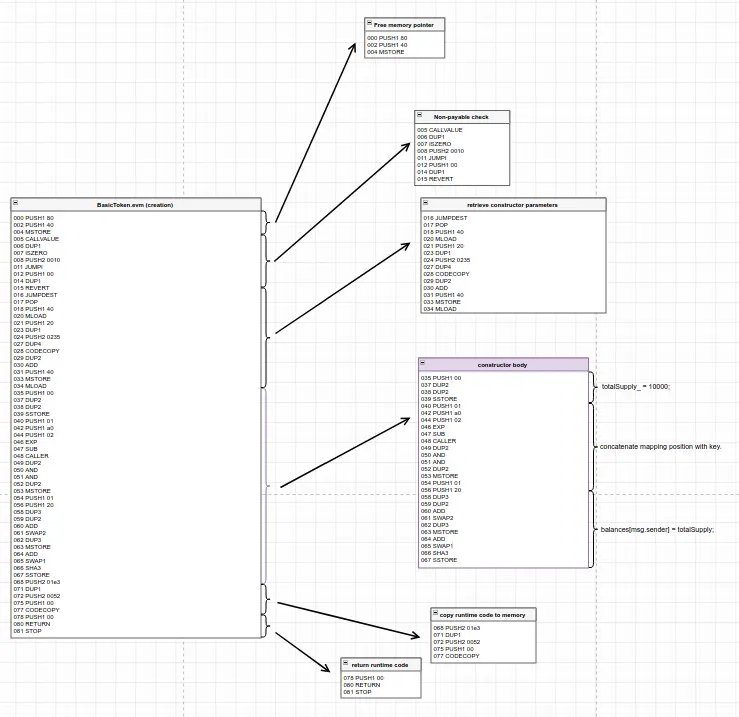
对BasicToken.sol的创建时EVM字节码的解构。
这是本文中需要理解的最重要的概念。创建代码在一个交易中被执行,它返回一个运行时代码的副本,也就是合约的实际代码。正如我们将看到的,构造函数是创建代码的一部分,而不是运行时代码的一部分。合约的构造函数是创建代码的一部分;一旦合约被部署,它就不会出现在合约的代码中。
这个魔术是如何发生的呢?这就是我们现在要一步步分析的:
好了。所以,现在我们的问题被简化为理解与创建时间代码相对应的这~70条指令。
让我们重新采取自上而下的方法,这次我们要边走边理解所有的指令,不要跳过任何一条。首先,让我们把重点放在指令0到2上,这些指令使用了PUSH1和MSTORE操作码:

空闲内存指针的EVM字节码结构
PUSH1简单地将一个字节推入堆栈顶部,MSTORE从堆栈中抓取最后两个项目并将其中一个存储到内存中:
mstore(0x40, 0x80)
| |
| What to store.
Where to store.
(in memory)
注意:上面的代码片段是Yul-风格代码。注意它是如何从堆栈中从左到右消耗元素的,总是先消耗堆栈顶部的东西。
这基本上是将数字0x80(十进制128)存储到内存的位置0x40(十进制64)。为了什么? 肯定是有原因的(实际上我们以后会看到)。现在,在Remix的调试器标签中打开_Stack和Memory面板,以便在你来回踩踏这些指令时直观地看到这些值。
你可能想知道:指令1和3是什么?PUSH指令是唯一的EVM指令,实际上是由两个或多个字节组成。所以,PUSH 80实际上是两条指令。那么谜底就揭晓了:指令1是0x80,指令3是0x40。
接下来是指令5到15:
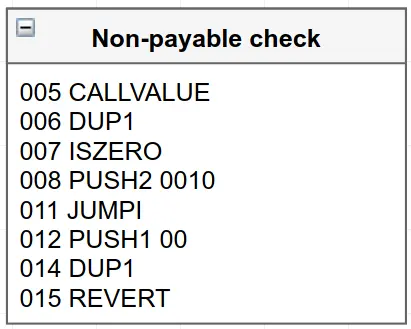
非payable的 EVM字节码结构。
这里我们有一堆新的操作码:CALLVALUE,DUP1,ISZERO,PUSH2,和REVERT。CALLVALUE推送了创建交易中涉及的Wei的数量,DUP1复制了堆栈中的第一个元素,ISZERO在堆栈的最上面的值为0时推送了一个1,PUSH2就像PUSH1,但它可以推送两个字节到堆栈,而不是只有一个,REVERT则停止执行。
那么这里发生了什么?在Solidity中,我们可以这样写这块汇编:
if(msg.value != 0) revert();
这段代码实际上不是我们原始 Solidity 源的一部分,而是由编译器注入的,因为我们没有声明构造函数是payable的。在Solidity的最新版本中,没有明确声明自己是可支付的函数不能接收以太币。回到汇编代码,第11条指令的JUMPI将跳过第12至15条指令,如果不涉及以太币,则跳到第16条。否则,REVERT将在两个参数都为0的情况下执行(意味着将不会返回任何有用的数据)。
好了! 咖啡时间。接下来的部分会有点棘手,所以休息几分钟可能是个好主意。来吧,给自己准备一杯好咖啡,同时唤起你的注意力。确保你理解我们到目前为止所看到的,因为接下来的部分有点复杂。

如果你想用另一种方式来可视化我们刚刚做的事情,可以试试我建立的这个简单的工具: solmap。它允许你实时编译Solidity代码,然后点击EVM操作码来突出相关的Solidity代码。反汇编与Remix的有点不同,但通过比较,你应该能理解它。
准备好继续前进了吗?很好! 接下来是指令16到37。继续用Remix的调试器进行跟踪。(记住,Remix是你的朋友^^)
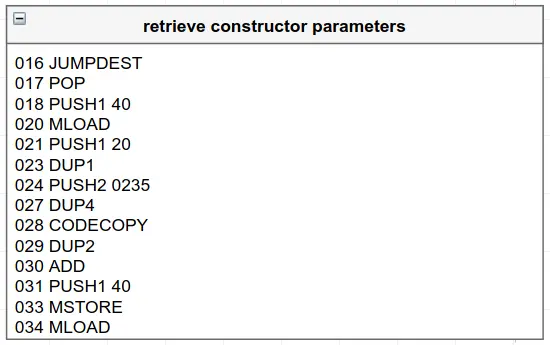
EVM的字节码结构,用于从合约的字节码末尾附加的代码中检索构造函数参数。
前四条指令(17到20)读取内存中0x40位置的任何东西,并将其推到堆栈。如果你还记得刚才的情况,那应该是数字0x80。接下来的指令将0x20(十进制32)推入堆栈(指令21),复制该值(指令23),推入0x0217(十进制535)(指令24),最后复制第四个值(指令27),这应该是0x80。吁! 我在写这句话的时候差点没喘过气来。在看这样的EVM指令时,暂时不明白发生了什么也没关系。别担心,它会突然在你的脑海中闪现。
在第28条指令中,CODECOPY被执行,它需要三个参数:要复制代码的目标内存位置,要复制的指令号,以及要复制的代码字节数。因此,在此案例中,它的目标内存位置是0x80,从代码中的字节位置535开始,代码长度为32字节。为什么?
如果你看一下整个反汇编的代码,有566条指令。那么,为什么这段代码试图复制最后32个字节的代码?实际上,在部署一个构造函数包含参数的合约时,参数会作为原始十六进制数据附加到代码的末尾。向下滚动指令面板可以看到这一点。在此案例中,构造函数需要一个uint256参数,所以这段代码所做的就是把参数从附加在代码末尾的值复制到内存。这32条指令在分解后的代码中没有意义,但在原始十六进制中却有意义:0x000000000000000000000...00000000000000000002710。当然,这就是我们在部署合约时传递给构造函数的十进制值10000!
明白为什么你需要那杯咖啡了吗?再一次,请在Remix中一步一步地重复这一部分,确保你明白刚才发生了什么。最终的结果应该是,你看到数字0x00...002710存储在内存的0x80位置。
好的。对于下一部分,你可能想给自己准备两杯威士忌。这将变得很奇怪。

只是开玩笑。没有更多的魔法,我保证。从这里开始都是轻松的下坡路。
下一组指令(29到35)将存储在内存0x40位置的数值从0x80更新到0xa0:也就是说,它们将数值偏移了0x20(32)字节。现在我们可以开始理解指令0到2 Solidity记录了一个叫做 空闲内存指针 的东西:也就是说,在内存中我们可以用来存储东西,并保证没有人会覆盖它(当然,如果我们犯了一个错误,除了我们使用内联汇编或Yul)。因此,由于我们在旧的空闲内存位置存储了数字10000,我们通过向前移动32字节来更新空闲内存指针。
即使是有经验的Solidity开发者,当他们看到 空闲内存指针 的表述或代码mload(0x40, 0x80)时也会感到困惑。这些只是在说,我们将从这一点开始向内存写入,每次我们写入一个新的条目,并保留一个偏移量的记录。 Solidity中的每一个函数,当编译为EVM字节码时,将初始化这个指针。
在0x00到0x40之间的内存中有什么,你可能会问。没有什么。它只是Solidity为计算哈希值而保留的一大块内存,正如我们即将看到的,哈希值对于映射和其他类型的动态数据是必要的。
现在,在第37条指令中,MLOAD从内存的0x40位置读取,基本上是将我们的10000值从内存中下载到堆栈中,在那里它将是新鲜的,准备在下一组指令中使用。
这是由Solidity生成的EVM字节码的一个常见模式:在执行一个函数体之前,函数的参数被加载到堆栈中(只要有可能),这样接下来的代码就可以消耗它们--而这正是接下来要发生的。
让我们继续学习指令38至55:

这些指令不外乎是构造函数的主体:也就是 Solidity 代码:
totalSupply_ = _initialSupply;
balances[msg.sender] = _initialSupply;
前四条指令是非常不言自明的(38到42)。首先,0被推到堆栈中,然后堆栈中的第二项被复制(这就是我们的10000号),然后数字0被复制并推到堆栈中,这就是totalSupply_的存储的位置槽。现在,SSTORE可以消耗这些值,并且仍然保留10000,以供将来使用。
sstore(0x00, 0x2710)
| |
| What to store.
Where to store.
(in storage)
Voila! 我们在变量 "totalSupply_"中存储了数字10000。这不是很令人吃惊吗?

请确保在Remix的调试器标签中也能看到这个值。你会在 加载完成的状态 面板中找到它。
下一组指令(43至54)有点令人不安,但基本上将处理在msg.sender的键的balances映射中存储10000。在继续前进之前,请确保你理解Solidity文档的这一部分,它解释了映射是如何保存在存储器中的。长话短说,它将把映射值的槽(在本例中是数字1,因为它是合约中声明的第二个变量)和使用的键(在本例中是msg.sender,用操作码CALLER获得)连接起来,然后用SHA3操作码哈希,把它作为存储的目标位置。最后,存储只是一个简单的字典或哈希表。
继续执行指令43到45,msg.sender地址被存储在内存中(这次是在0x00位置),然后在指令46到50,值1(映射的槽)被存储在内存0x20位置。最后,SHA3 操作码计算内存中从0x00位置到0x40位置的任何东西的Keccak256哈希值--即映射的槽/位置与所使用的key的连接。这正是10000值在我们的映射中的存储位置。
sstore(hash..., 0x2710)
| |
| What to store.
Where to store.
就这样了。在这一点上,构造函数的主体已经被完全执行。
所有这些一开始可能有点令人不知所措,但这是 Solidity 中存储工作的一个基本部分。如果你不太明白,我建议你跟着Remix的调试器多看几遍,把Stack和Memory面板放在眼前。这种模式在Solidity生成的EVM字节码中随处可见,你将很快学会毫不费力地识别它。归根结底,它只不过是在存储中计算某个映射的某个键的值应该保存在哪里。
好了,我们在这里差不多完成了。如果你走到这一步,接下来的部分将是小菜一碟。

运行时的代码复制
在指令56到65中,我们再次进行代码复制。只是这一次,我们不是把代码的最后32个字节复制到内存中;我们要把0x01d1(十进制465)字节从0x0046(十进制70)位置开始复制到内存的0位置。
如果你再把交易滑块一直滑到右边,你会发现位置70就在我们的创建时EVM代码之后,执行停止了。运行时的字节码就包含在这465个字节中。这是代码的一部分,将被保存在区块链中作为合约的运行时代码,这将是每次与合约交互时执行的代码。(我们将在本系列的未来部分介绍运行时代码)。
而这正是指令66至69的作用:我们复制到内存中的代码被返回:
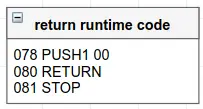
运行时代码返回EVM字节码结构。
RETURN抓取复制到内存中的代码并将其交给EVM。如果这个创建代码在交易的上下文中被执行到0x0地址,EVM将执行该代码并将返回值存储为创建的合约的运行时代码。
这就是了! 现在,我们的BasicToken合约实例将被创建和部署,其初始状态和运行时代码已准备好使用。如果你退一步看一下空闲指针图:

你会发现我们分析的所有EVM字节码结构都是通用的,除了紫色高亮显示的那个:也就是说,它们将在Solidity编译器生成的创建时字节码中。各个构造函数的不同之处仅仅在于紫色部分--构造函数的实际主体。嵌入在字节码末尾的获取参数的结构,以及复制运行时代码并返回的结构,可以被认为是模板代码和通用的EVM操作码结构。你现在应该可以看任何一个构造函数了,在逐条研究它的指令之前,你应该对构成它的组件有一个大致的概念。
在下一篇文章中,我们将研究实际的运行时代码,首先是你如何在不同的入口点与合约的EVM代码进行交互。现在,给自己一个当之无愧的掌声,因为你刚刚消化了本系列中最困难的部分。你也应该培养了很强的能力来阅读和调试EVM字节码,理解泛型结构,最重要的是,理解创建时和运行时EVM字节码之间的区别。这就是Solidity中合约的构造函数的特殊之处。
转载:https://learnblockchain.cn/article/5190













{kind=link}
{kind=link}