项目介绍
官网: https://filecoin.io/zh-cn
github: https://github.com/filecoin-project
区块浏览器:https://filscan.io/#/
Filecoin简单来说就是一个去中心化分布式付费存储网络,用户可以付费存储和付费下载数据。矿工提供存储和检索下载的服务,同时收取用户存储和下载的费用。同时网络会增发代币,以此激励矿工提供存储服务,同时矿工需要质押一些代币,来作为服务质量的担保,如果审查不达标,会遭到惩罚,以此优化整个网络的存储质量。至于轮到哪个节点出块,是随机命中,命中率与当前节点算力多少成正比。节点的算力多少取决于该节点存储的存储数据占全网的比例。同时矿工必须定期提交一次复制证明,证明节点内的数据还是有效存储的。链上也会在每个出块时间随机发出挑战challenge,来验证数据是否存在。如果失败,则被扣除抵押币,以此来验证节点服务是否正常优质以及惩罚作恶。
代币信息
代币符号: FIL
发行总量:20亿
代币分配
矿工占比:70%(14亿)
实验室占比:15%
ICO占比:10%
基金会占比:5%
预计出矿量
如果按照每年365天计算,平均每天分发约319726枚FIL代币,约32万枚。而且FIL币的产出也非线性产出,一般是前期产出较快,然后逐步放缓。按照官方给出的产出规则来看,第一个6年,FIL代币产出总量将达到7亿枚。那么第一年的产出将会最少达到1亿多枚
减半时间
6年
挖矿原理
Filecoin的矿工分为两种:存储矿工和检索矿工。
存储矿工收益
- 存储收益:帮用户存储数据,获取用户支付的存储费用(价值交换)
- 新币分发:参与共识协议,获取新币分发(上帝发币)
- 交易手续费:参与共识协议,获取交易手续费
检索矿工收益:
- 检索收益:用户下载数据,获取用户支付的下载数据费用(FIL)
对于存储矿工可以理解为是共享出自己的硬盘资源并获得酬劳。当有用户提出存储需求时,用户需要支付代币作为存储的酬劳。然后,系统会把一个订单拆分成很多的小订单,矿工们自动进行抢单,谁的存储空间符合,且距离更近,传输速度更快,谁就更有可能抢到一部分存储订单。抢到后,矿工需要用代币进行抵押,以确保自己能够完成存储任务,如果最终顺利完成,抵押的代币将会退回,同时获得这个订单的相应酬劳。如果执行过程中出现错误,系统将扣除矿工的抵押代币作为处罚。
挖矿算力权重
存储矿工当前的有效存储数据与全网的存储数据所占的比例,这也是所谓的算力的大小,并不是硬盘空间越大,算力就越大。
预期共识爆块
每一轮出块,最重要的一个步骤就是选举,这里的选举实际上是自己进行计算,不需要大家投票。用掷飞镖来比喻的话,基本上分成以下几个步骤
- 每一个矿工面前有一个大飞镖盘,面积与整个网络的总算力相当(这是已知的),每个人都一样。
- 每一个矿工的算力各有差异,仅占总算力的一小部分。每一个矿工的飞镖盘上都有一块材料是木头,面积与此矿工的算力相当;而其他部分都是金属。
- 但是飞镖盘上面蒙上了一层纸,哪一部分是木头的不知道,也就是说,只有上帝知道(这有系统的可验证随机函数确定,主要通过散列和签名实现)。
- 每一个矿工自由掷出飞镖到飞镖盘,命中木头部分,上靶(胜出),否则,掉落(等待下一轮继续)。
- 下一轮重复,但注意,木头部分每一轮都会换地方,只有上帝知道换到了哪里。
每一轮上靶者称为这一轮的 Leader,即选举胜出者,有资格出块。
预期共识有一个缺点:每一轮选举出来的Leader,可能是多个,也可能没有,平均下来是一个。这个问题该怎么解决?
很简单,都当领导,各自产生区块,而且每一个区块都有效。
也就是说同一个高度就可能有多个区块。怎么处理?办法是,把这些区块再打包,称为一个tipset。因此,在Filecoin中,链并不能完全称为区块链,而应该是tipset链。
一个tipset里包含一个或多个区块。也有的轮次中的选举没有领导人,怎么办呢?那就跳过,这个高度就是一个空块。这样一来,尽管不够均匀,但形成了链,而且是收敛的。
当前Filecoin用来选举的协议是EC协议(Expected Consensus )。SSLE将会是改进版协议。还在开发完善中。

FIL价值流转
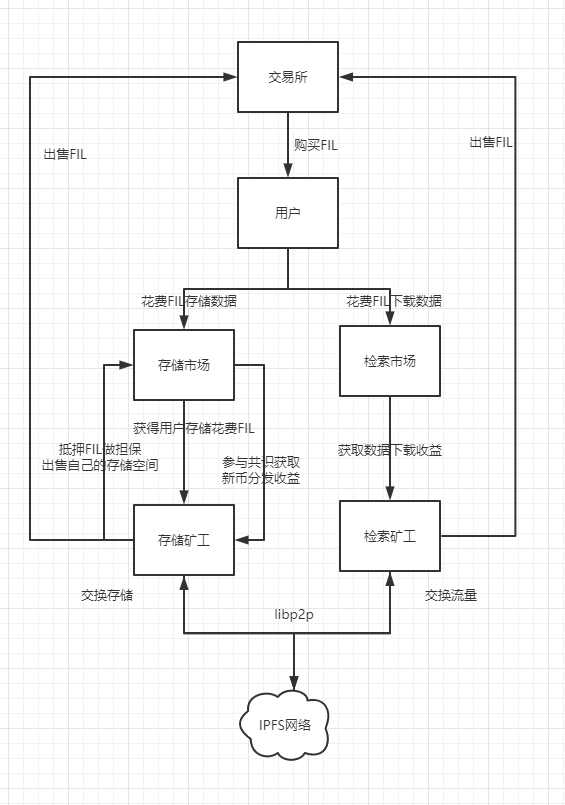
数据来源
存储矿工的数据来源:
用户付费存储数据
检索矿工的数据来源
- 自己作为存储矿工,现在的用户数据
- 自己从其他矿工那里购买下载的数据
- 自己找的一些数据
收益影响因素
存储矿工 (努力让更多的用户把数据存储到你这里)
检索矿工 (努力给更多的用户提供数据)
- 网络带宽
- 网络时延
- 存储的数据是否是用户所需
- 定价的检索数据价格
调优因素
存储矿工
检索矿工
- 动态调整检索数据价格,以获取更多的收益
- 努力找到更多的用户感兴趣的数据
- 提高网络的带宽和降低网络的延时
简述复制证明和时空证明
复制证明是为了证明节点确实存了数据,时空证明是为了证明节点一直对其有效存储。
复制证明的原理
复制证明(PoRep),证明数据的一个单独的拷贝已经在一个特定的扇区内创建成功。复制证明由封印(Seal)操作完成,封印操作创建一份数据的拷贝,并产生相应的复制证明。这是一种新型的存储证明方案,它能够让存储矿工说服用户和其他矿工,表明数据已经被复制到了它的矿机上。
时空证明的原理
它证明一定数量的已封印的扇区,在一定的时间范围内存在于指定的存储空间之中 —而不是证明者临时生成的数据(这被视为攻击)。
时空证明可以理解为持续的复制证明,即矿工必须不断的生成证明,并在一个提交周期内提交存储证明,如果存储服务商没有在提交周期内连续及时提交证明,会被系统扣除部分代币。
生成时空证明的过程跟复制证明非常相似,只是时空证明的输入是以上一生成的证明做为输入参数,这样能保证证明生成的连续性,PoSt可以证明在该段时间内矿工存储了特定的数据,并且利用时间戳锚定这些证明链,这样即使验证者(verifier)不在线,也能够在将来去验证矿工在该段时间内生成了证明链,PoSt会被提交到链上用来产生新的区块。
共识机制
Filecoin抛弃了以往区块链的高度依赖计算资源和能源消耗形成的共识机制,Filecoin重新利用有意义的工作来形成共识机制,这就是PFT(power fault tolerance),进化版的拜占庭容错机制,将矿工当前在网中使用的存储量和生成的时空证明转化为投票的权重,然后节点利用这个权重进行选举产生一个或者多个领导节点,领导节点创建新的block并把它们传播到网络。
预期共识
Filecoin区块链的主要出块共识,是一种概率拜占庭容错共识机制,它的目标是使得矿工出块的权益,与自己对存储的贡献成正比。也就是说,矿机(矿池)被使用的有效存储空间,在整个网络中的总使用空间中所占比例,就是此矿机(矿池)能够出块的概率
复制证明(Proof-of-Replication)
PoRep是PoS的进阶版,可以证明矿工已将数据(data)存储,并保证每份数据存储的独立性,同时防止女巫攻击、外源攻击和生成攻击。复制证明避免让矿工可以透过不同方法让自身存储数据小于承诺存储数据,以获得额外报酬。
女巫攻击(Sybil Attack):
举例,一个不怀好意的人,名字叫女巫,Ta伪造多个身份,给大家广播说我真的存了100份文件,实际只存在1个。女巫出示自己的100个证明,欺骗了系统,那么女巫就攻击成功。
外部数据源攻击(Outsourcing Attack):
当攻击者收到检验者要求提供存储了数据证明的时候,攻击者从别的矿工那里生成证明,欺骗大家说自己一直存储了那份数据,但实际上没有存储,攻击成功。
生成攻击(Generation Attack):
攻击者可以使用某种方式生成数据,当检验者验证的时候,攻击者利用重新生成的数据来完成存储证明,攻击成功
时空证明 (Proof-of-Spacetime)
矿工证明自己花费了Spacetime资源,即一定时间内的存储空间的使用,PoSt是基于复制证明实现的。即使验证者不在线,也能够在未来去验证矿工在该段时间内生成了证明链,有效防止临时生成数据攻击。
数据持有性证明 (Provable-Data-Possession)
矿工完成了用户存储数据的订单后,为了证明数据已经被自己存储,用户可以多次验证矿工是否将其数据保持存储的状态。
可检索证明 (Proof-of-Retrievability)
与PDP类似,证明矿工存储的数据是可以用来查询的。
几个证明机制之间的关系
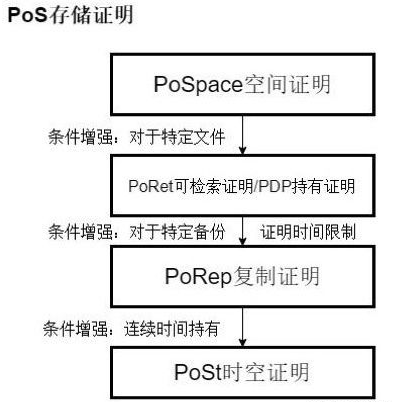
总结
在预期共识中,矿工赢得选举的可能性跟矿工当前的存储能力成正比,而存储能力则由复制证明和时空证明来衡量
出块流程
阶段一 密封
矿工会先获取存储订单,把数据切成256KB的小块,用特定算法(Stacked DRG)进行密封生成副本。
这个过程最耗时, 数据越多, 时间越长。初期, 大家硬盘都是空的, 就比谁存储速度更快, 即"密封速度", 这会涉及软件算法的优化、CPU、内存、以及硬盘的读写能力。这个过程会让硬盘几周内就被写满。
阶段二 复制证明
接下来就是生成"复制证明zksnark"的过程,用特定算法对存储数据生成一个"零知识证明", 以验证密封的数据来源于客户的源数据, 需要在指定时间内(30秒)完成, 并广播到全网,让别人确认该出块的有效, 然后上链。这个过程要用到GPU加速, 如果30秒内完不成, 将得不到块奖励。
阶段三 Sector(扇区)证明
矿工会将客户提供的数据存放于网络中,这个区域称为扇区Sector。每个扇区会包含存储文件内容及承诺存储时长,确保客户在约定存储时长中,可以自由运用自身存储的数据。矿工添加一个扇区至 Filecoin 网络时,需要质押一笔锁定币(自身持有的 FIL 通证以及部分区块奖励)
链上的miner智能合约会验证提交的证明是否正确,这可以达到毫秒级处理速度。
以上是完整Filecoin出块流程基本介绍,矿工在赢得区块奖励后,仍然需要持续证明存储的数据没有丢失,因此就到了最后一环时空证明。
时空证明:矿工必须每1小时左右,提交一次复制证明,证明数据还在。链上也会在每个出块时间随机发出挑战challenge,来验证数据是否存在。如果失败,则被扣除抵押币。
智能合约
Filecoin为最终用户提供了两个基本命令:Get和Put。 这两个命令允许客户以优惠的价格存储数据并从市场中检索数据。 尽管命令涵盖了Filecoin的默认使用案例,但我们通过支持智能合约的部署,允许在Get和Put之上设计更复杂的操作。用户可以编写新的严谨的存储/检索的请求,我们就像归类一般的智能合约一样将其归类为文件合约。我们整合了一个合约系统(基于[18])和一个桥系统,目的是将Filecoin存储装入其他区块链,反之亦然,将其他区块链的功能带入Filecoin。
与IPFS的关系
Filecoin是运行在ipfs上面的一个激励层,简单理解是IPFS相当于网络协议,Filecoin相当于利用IPFS做的一个上层应用。
目前测试矿机分布
https://filscan.io/#/stats/map
矿机配置
CPU: 4核(重点是存储的I/O性能,对整机的运算性能要求不高)
RAM:8G (矿机在进行读写时,信息主要暂时存储在内存上,内存容量大小,直接影响矿机的读写性能和整体挖矿性能)
硬盘:4T(初期,后期根据实际用量随时增加),支持热插拔,兼容性设计
网络:拥有上下行对等的专线带宽,设置公网静态IP地址(家用矿机至少要标配一个千兆以太网口)
位置:挖矿方式会选择就近原则,所以建议一线城市,进行分布式布局
GPU也很重要,决定你的广播区块速度,你存了数据, 得告诉全网, 这就是广播,你广播得快,就能抢到Fil。
矿机硬件再好, 如果网络传输如果中断, 速度慢,那么会被罚Fil, 每个矿工加入节点,都要先抵押一部分Fil,因此,保证带宽是非常重要的。
目前存在的问题 (5-20号)
- 扇区密封比较慢, 32GB的扇区单机跑需要6个小时
- 链比较脆弱,daemon有内存泄露的问题
- 集群问题多,任务调度的Bug还很多,不够智能,需要矿工自己优化软件;在拆解代码的时候,V26和V25差别很大,在pre1和pre2到commit中间,需要等待比较久
- 采用AMD的CPU比Intel有压倒性优势,因为pre1的SDR算法对AMD 的SHA扩展非常友好
主网上线时间
经过多次推迟,最后一次官方消息预计7月底,三方消息再次推迟 8月31日—9月21日
参考
https://zhuanlan.zhihu.com/p/44568157
https://zhuanlan.zhihu.com/p/153483004
https://blog.csdn.net/SmarterEric/article/details/106521907