本篇文章分析的源码地址为:https://github.com/ethereum/go-ethereum
分支:master
commit id: 257bfff316e4efb8952fbeb67c91f86af579cb0a
引言
区块链本质上是分布式的,因此同步区块数据是必不可少的一个功能模块。在这篇文章以及接下来的几篇文章里,我们就来看一下以太坊中关于区块同步的代码。由于区块同步的代码比较多,逻辑也比较复杂,因此本篇文章里我们只是先看看关于协议的内容和数据收发的主要流程,后面的文章将会单独分析其它内容。
所有的公链项目在底层都使用了p2p技术来支持节点间的互联和通信。但本篇文章不会涉及到p2p的内容,一方面是因为p2p技术包含的内容很多,再多写几篇文章也不能分析完,更无法在当前文章里讲清楚;另一方面也是因为p2p属于自成体系的成熟技术了,也有成熟的库可以使用。
源码目录
以太坊中关于区块同步和交换的代码位于eth目录下和les目录下。其中eth实现了所有的相关逻辑,而les只是light同步模式下的实现。这可以从cmd/utils/flags.go中的RegisterEthService函数中看出来:
func RegisterEthService(stack *node.Node, cfg *eth.Config) {
if cfg.SyncMode == downloader.LightSync {
err = stack.Register(func(ctx *node.ServiceContext) (node.Service, error) {
return les.New(ctx, cfg)
})
} else {
err = stack.Register(func(ctx *node.ServiceContext) (node.Service, error) {
......
return fullNode, err
})
}
}当配置文件中的SyncMode字段为downloader.LightSync时,会使用les目录下的代码;否则使用eth目录下的代码。由于eth目录下的代码实现了全部的逻辑和功能,因此我们主要关注eth目录下的代码。
在eth目录下,和区块同步相关的主要的源代码文件有handler.go、peer.go、sync.go,以及downloader目录和fetcher目录。其中前三个源码文件定义了区块同步协议及整体工作框架,也是本篇文章要重点分析的内容;而后两个目录是我们之后的文章要分析的内容。
运行框架
我们用一张图来概括一下网络模块的运行框架:
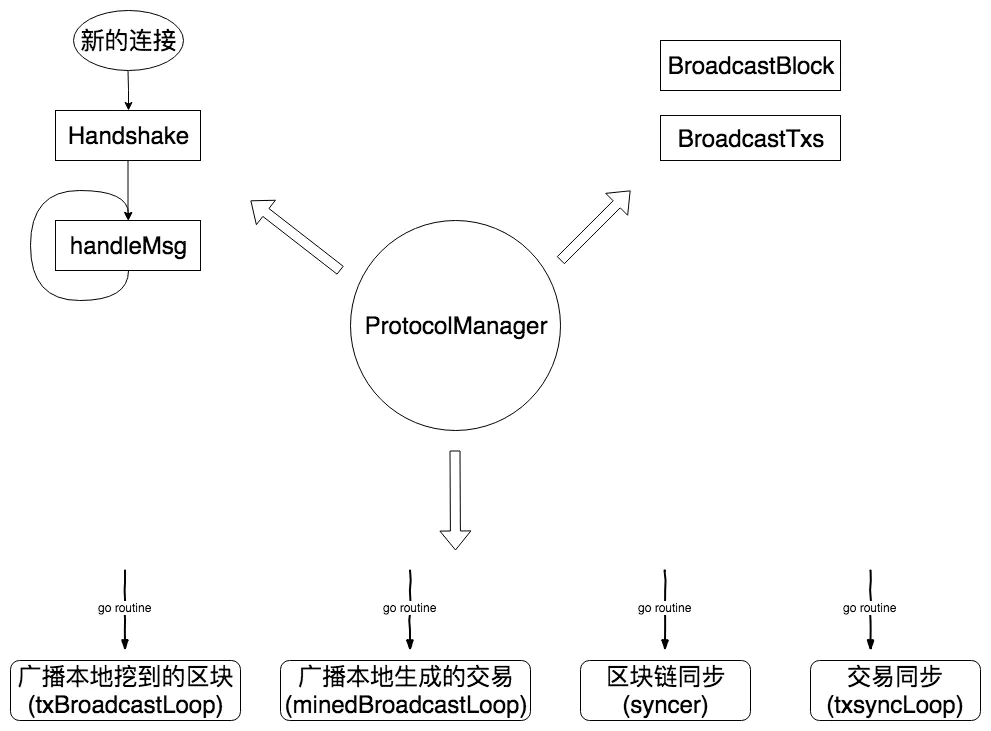
这个框架主要由ProtocolManager对象实现。可以看到这个框架实现了消息处理、广播区块和交易、同步区块和交易等功能。这也是一个区块链项目区块同步的最基本功能。下面我们对一些功能进行详细的分析。
消息处理(handle)
每当p2p模块发现一个新的节点并连接完成时,就会调用p2p.Protocol.Run函数。而此函数的注册是在NewProtocolManager中完成的:
func NewProtocolManager(......) (*ProtocolManager, error) {
......
for i, version := range ProtocolVersions {
manager.SubProtocols = append(manager.SubProtocols, p2p.Protocol{
......
Run: func(p *p2p.Peer, rw p2p.MsgReadWriter) error {
peer := manager.newPeer(int(version), p, rw)
select {
case manager.newPeerCh <- peer:
manager.wg.Add(1)
defer manager.wg.Done()
return manager.handle(peer)
case <-manager.quitSync:
return p2p.DiscQuitting
}
},
......
})
}
......
}从代码中可以看出,每当有新的节点到来时,会先把节点对象发给newPeerCh,之后再调用ProtocolManager.handle方法。如果这个方法返回,那么p2p.Protocol.Run函数也就返回了,这代表这个连接也就可以断开了。
另外您可能也注意到上面的代码有一个基于ProtocolVersions的for循环。ProtocolVersions的定义如下:
var ProtocolVersions = []uint{eth63, eth62}这表示在以太坊中有两个版本的区块同步协议。主要区别在于有一些消息是在eth63中新加的,eth62中没有。后面在涉及具体的消息处理代码时我们会看到区别。
ProtocolManager.handle
ProtocolManager.handle方法对每个新到来的连接进行处理。此方法稍长,我们一点一点进行分析。先看一下最开始的代码:
func (pm *ProtocolManager) handle(p *peer) error {
// Ignore maxPeers if this is a trusted peer
if pm.peers.Len() >= pm.maxPeers && !p.Peer.Info().Network.Trusted {
return p2p.DiscTooManyPeers
}
......
}以太坊的节点连接有一个最大值,如果连接数已超过这个最大值且不是信任的连接,就马上返回,因此当前的连接就会中断。也就是说,如果是可信任的节点(Trusted Node),那么即使超过最大连接数也可以正常连接。
什么是可信任的节点呢?可信任的节点是我们自己设置的,你可以在js console中通过admin.addTrustedPeer来填加,或者在
接下来就是和对方“握手”,相互交换信息了:
func (pm *ProtocolManager) handle(p *peer) error {
......
if err := p.Handshake(pm.networkID, td, hash, genesis.Hash()); err != nil {
return err
}
......
}“握手”的详细信息我们后面会单独说明,这里暂时跳过。
我们继续来看“握手”完成后的代码:
func (pm *ProtocolManager) handle(p *peer) error {
......
if err := pm.peers.Register(p); err != nil {
return err
}
defer pm.removePeer(p.id)
// Register the peer in the downloader. If the downloader considers it banned, we disconnect
if err := pm.downloader.RegisterPeer(p.id, p.version, p); err != nil {
return err
}
// Propagate existing transactions. new transactions appearing
// after this will be sent via broadcasts.
pm.syncTransactions(p)
......
}这块代码有两个功能,一是告诉peers对象(一个peerSet类型的对象,用来管理所有的peer)和downloader对象有新的节点连接进来了;二是与新的节点同步自己所有pending状态的交易(syncTransactions)。
我们再来看接下来的代码:
func (pm *ProtocolManager) handle(p *peer) error {
......
for number := range pm.whitelist {
if err := p.RequestHeadersByNumber(number, 1, 0, false); err != nil {
return err
}
}
......
}这段代码向当前连接的节点请求所有的“白名单区块”。所谓的“白名单区块”是你认为的可信任的区块,这些区块的高度和哈希被写在配置文件里的Whitelist字段中。这些区块的目的是为了对接入的节点的数据正确性作一个简单的验证。在ProtocolManager.handleMsg中接收到区块时会判断区块高度是否在“白名单区块”列表中,如果在但哈希不一致,则认为这个节点的数据有问题,立刻断开与它的连接。这在后面介绍ProtocolManager.handleMsg时还会讲到。
然后我们看看最后一段代码:
func (pm *ProtocolManager) handle(p *peer) error {
......
for {
if err := pm.handleMsg(p); err != nil {
return err
}
}
}这段代码很简单但很关键。可以看到在一个for循环中不停调用ProtocolManager.handleMsg方法,如果失败就立刻返回。
ProtocolManager.handleMsg
接下来我们看看ProtocolManager.handleMsg的实现。看名字就知道这个方法是用来处理接收到的消息的。其主要的框架代码也非常简单,就是从对方连接中读取消息,根据消息码的不同进行处理:
func (pm *ProtocolManager) handleMsg(p *peer) error {
msg, err := p.rw.ReadMsg()
if err != nil {
return err
}
if msg.Size > ProtocolMaxMsgSize {
return errResp(ErrMsgTooLarge, "%v > %v", msg.Size, ProtocolMaxMsgSize)
}
defer msg.Discard()
switch {
case msg.Code == StatusMsg: ......
case msg.Code == GetBlockHeadersMsg: ......
case msg.Code == BlockHeadersMsg: ......
case msg.Code == GetBlockBodiesMsg: ......
case msg.Code == BlockBodiesMsg: ......
case p.version >= eth63 && msg.Code == GetNodeDataMsg: ......
case p.version >= eth63 && msg.Code == NodeDataMsg: ......
case p.version >= eth63 && msg.Code == GetReceiptsMsg: ......
case p.version >= eth63 && msg.Code == ReceiptsMsg: ......
case msg.Code == NewBlockHashesMsg: ......
case msg.Code == NewBlockMsg: ......
case msg.Code == TxMsg: ......
default: return errResp(ErrInvalidMsgCode, "%v", msg.Code)
}
return nil
}具体的针对每一个消息的处理,我们就不一一展开分析了,这些代码虽然较多,但逻辑还是比较简单的。不过有几个问题这里仍然需要多说一下。
fetcher与downloader
在一些消息处理代码中,会将收到的数据交给fetcher的filter方法处理,剩下的再交给downloader的Deliver方法处理。这是因为与其它节点发起数据交互的地方不止一处,其中就有fetcher和downloader对象,而所有交互数据都会经过ProtocolManager.handleMsg进行处理,因此就需要知道这些数据是谁主动发起获取的。这里将数据先传给fetcher的fileter函数,就是让fetcher把自己发起获取的数据留下,从而将剩下的交给downloader。
关于fetcher和downloader的详细信息,我们会在以后的文章进行介绍。
NewBlockMsg与NewBlockHashesMsg
NewBlockMsg消息用来接收或发送整个block数据(普通获取完整block的方式是先获取header、再获取body);NewBlockHashesMsg只是接收或发送一个block的哈希。这俩个消息是有些类似的,为什么会存在这么两个消息呢?
当ProtocolManager.broadcastBlock的第二个参数propagate为true时,会向其它节点发送NewBlockMsg消息。而propagate为true的情况有两种:一是fetcher模块中将一个同步到的区块加入到本地数据库前,使用这个消息通知其它节点自己的区块有更新;二是本地节点的挖矿模块出了一个新的区块时,使用消息将这个新区块发送给自己的其它节点。相关代码如下:
//订阅新挖到的区块消息,并广播新区块
func (pm *ProtocolManager) minedBroadcastLoop() {
for obj := range pm.minedBlockSub.Chan() {
if ev, ok := obj.Data.(core.NewMinedBlockEvent); ok {
pm.BroadcastBlock(ev.Block, true) // First propagate block to peers
pm.BroadcastBlock(ev.Block, false) // Only then announce to the rest
}
}
}
//fetcher中将区块插入本地数据库之前,广播将要插入的区块
func (f *Fetcher) insert(peer string, block *types.Block) {
......
switch err := f.verifyHeader(block.Header()); err {
case nil:
go f.broadcastBlock(block, true)
}
......
}也就是说,当fetcher在本地插入新区块时和本地挖到新的区块时,将会发送NewBlockMsg消息。
无论ProtocolManager.broadcastBlock的第二个参数propagate为true还是false,都会向其它节点发送NewBlockHashesMsg消息。所以除了刚才提到的发送NewBlockMsg消息的情况,还有一种情况是区块同步完成时,会广播自己的最新区块信息:
func (pm *ProtocolManager) synchronise(peer *peer) {
......
if err := pm.downloader.Synchronise(peer.id, pHead, pTd, mode); err != nil {
return
}
......
if head := pm.blockchain.CurrentBlock(); head.NumberU64() > 0 {
go pm.BroadcastBlock(head, false)
}
}还有一点需要注意的是,当ProtocolManager.broadcastBlock的第二个参数propagate为true时,不会给所有节点发送NewBlockMsg消息,而是从没有这个区块的节点中,选取一部分(平方根):
func (pm *ProtocolManager) BroadcastBlock(block *types.Block, propagate bool) {
if propagate {
......
transferLen := int(math.Sqrt(float64(len(peers))))
if transferLen < minBroadcastPeers {
transferLen = minBroadcastPeers
}
if transferLen > len(peers) {
transferLen = len(peers)
}
transfer := peers[:transferLen]
for _, peer := range transfer {
peer.AsyncSendNewBlock(block, td) //发送NewBlockMsg
}
return
}
......整体上来看,NewBlockMsg和NewBlockHashesMsg这两个消息的达到的目的相同,我猜测使用NewBlockHashesMsg的目的,是为了减少同一时刻的网络流量,因为在广播时有的节点直接发送整个区块数据,而另一些只发送哈希。但NewBlockMsg有一个重要的功能,就是接收者可以更新本地记录的对方的Head数据,这一点我们会在后面"Head数据的更新"小节里详细说明。
whitelist block
前面我们提到whitelist字段,在连接之初时会向对方请求whitelist中的哈希代表的区块。在请求发生后,正常情况应该会收到对方回复的BlockHeadersMsg消息,我们看一下这个消息其中一处的处理代码:
func (pm *ProtocolManager) handleMsg(p *peer) error {
......
switch {
case msg.Code == BlockHeadersMsg:
filter := len(headers) == 1
if filter {
if want, ok := pm.whitelist[headers[0].Number.Uint64()]; ok {
if hash := headers[0].Hash(); want != hash {
return errors.New("whitelist block mismatch")
}
}
}
}
}可见当收到的header只有一个时,就会去判断whitelist,如果高度在whitelist列表中但哈希不一致,说明对方的数据有问题,我们要马上断开与它的连接。所以此处的代码和连接之初发送whitelist中的区块请求的代码,一起构成了对白名单区块的验证。
handshake
在与别的节点建立连接之初,会与其进行“握手”操作,这就是是由peer.Handshake方法完成的。这一小节里我们就详细看一下握手的功能实现。
peer.Handshake特别简单,就是给对方发送Status数据,并等待接收对方的Status数据,然后保存接收到的数据。这中间会设置一个超时时间。代码如下:
func (p *peer) Handshake(network uint64, td *big.Int, head common.Hash, genesis common.Hash) error {
//发送自己的数据对方
go func() {
errc <- p2p.Send(p.rw, StatusMsg, &statusData{
ProtocolVersion: uint32(p.version),
NetworkId: network,
TD: td,
CurrentBlock: head,
GenesisBlock: genesis,
})
}()
//等待接收对方的数据
go func() {
errc <- p.readStatus(network, &status, genesis)
}()
//等待数据发送和接收都完成,或者超时
//有个for循环2是因为要分别等待和判断发送/接收两个情况
timeout := time.NewTimer(handshakeTimeout)
defer timeout.Stop()
for i := 0; i < 2; i++ {
select {
case err := <-errc:
if err != nil {
return err
}
case <-timeout.C:
return p2p.DiscReadTimeout
}
}
//保存td和head
p.td, p.head = status.TD, status.CurrentBlock
return nil
}可以看到握手时使用的消息是StatusMsg,交换的数据由statusData结构体保存:
type statusData struct {
ProtocolVersion uint32
NetworkId uint64
TD *big.Int
CurrentBlock common.Hash
GenesisBlock common.Hash
}通过这个结构体,握手时交换的哪些信息也是一目了然的。
另外值得注意的是,peer.Handshake是在消息处理循环(ProtocolManager.handle最末尾的那个循环)之前调用的,所以才会自己接收消息而不会经过ProtocolManager.handleMsg(其它情况下消息都是由ProtocolManager.handleMsg处理的)。StatusMsg消息在握手以后就再不会被使用,因此在ProtocolManager.handleMsg中对StatusMsg的处理是返回失败:
func (pm *ProtocolManager) handleMsg(p *peer) error {
......
switch {
case msg.Code == StatusMsg:
// Status messages should never arrive after the handshake
return errResp(ErrExtraStatusMsg, "uncontrolled status message")
}
......
}发起区块同步
区块同步的功能由downloader实现。这里我们只关注于区块同步的发起,具体如何同步的我们将在后面的文章中进行介绍。
在ProtocolManager.Start中创建几个go routine,其中一个就是ProtocolManager.syncer,而区块同步的发起就是在这个方法里的。我们先看一下它的代码:
func (pm *ProtocolManager) syncer() {
......
forceSync := time.NewTicker(forceSyncCycle)
defer forceSync.Stop()
for {
select {
case <-pm.newPeerCh:
if pm.peers.Len() < minDesiredPeerCount {
break
}
go pm.synchronise(pm.peers.BestPeer())
case <-forceSync.C:
go pm.synchronise(pm.peers.BestPeer())
case <-pm.noMorePeers:
return
}
}
}可以看到有两种情况会发起区块同步:一是有新的节点建立连接时;二是每隔forceSyncCycle长的时间(10秒)就会同步一次。我认为这里最值得关注是Bestpeer这个方法。在以太坊的同步时,会先选择一个节点从它那同步一些“骨架”区块(skeleton,即每隔一定的高度同步一个区块),然后从其它节点中获取区块填充“骨架”(这一机制在downloader中实现,后面的文章我们会详细分析)。那么如何选取同步“骨架”节点呢?就是这里的BestPeer。我们看一下它的实现:
func (ps *peerSet) BestPeer() *peer {
ps.lock.RLock()
defer ps.lock.RUnlock()
var (
bestPeer *peer
bestTd *big.Int
)
for _, p := range ps.peers {
if _, td := p.Head(); bestPeer == nil || td.Cmp(bestTd) > 0 {
bestPeer, bestTd = p, td
}
}
return bestPeer
}很简单,所谓“最好的节点”就是TD(TotalDifficulty,关于TD的详细信息可以参看这篇文章)最大的节点。
真正发起同步的代码中ProtocolManager.synchronise中,代码简单,这里只说一下两个细节:
如果对方节点的TD小于自己的,就没必要同步了。
同步完成后,通过NewBlockHashesMsg广播自己的最新的区块,从而告诉别人。
广播
ProtocolManager对象还有广播的功能,主要是广播本地刚挖到的区块和新生成的交易。这主要是通过ProtocolManager.minedBroadcastLoop和ProtocolManager.txBroadcastLoop实现的。这两个方法订阅了本地挖到新区块和本地生成新交易的信息,每当有数据到来时,就调用ProtocolManager.BroadcastBlock或ProtocolManager.BroadcastTxs将其广播给其它节点。
peer与peerSet
在这一小节里,我们说的peer和peerSet对象指的是eth/peer.go文件中的对象。peer对象代表的是与之建立连接的对方节点,其主要功能有两个:一是在本地记录对方一些已经拥有的数据,比如对方已经拥有了哪些block、哪些transaction、对方最新的区块哈希和TD是多少;二是发送数据给对方。而peerSet是peer对象的集合,是对peer对象的管理。下面我们就来看看一些主要的功能。
已知数据
在peer对象中,保存着对方的一些我们可以统计到的数据,这主要包括三部分内容:
- 对方的主链上的最新区块哈希和TD。这是由字段peer.head和peer.td保存的
- 对方已经拥有的区块哈希。这是由字段peer.knownBlocks保存的
- 对方已经拥有的交易哈希。这是由字段peer.knownTxs保存的
拥有了所有连接的最新的区块哈希和TD,我们就可以在同步前从这些连接中找到TD值最高的那个连接与之同步(peerSet.BestPeer);而知道哪些节点忆拥有哪些区块和交易,我们在广播区块和交易时就可以不再给这些节点广播,从而避免流量的浪费。
在peer对象中,设置peer.knownBlocks和peer.knownTxs的地方有两大块:一是几个send方法,比如peer.AsyncSendTransactions和peer.SendNewBlock等;二是两个mark方法:peer.MarkBlock和peer.MarkTransaction。其中peer.MarkBlock在处理NewBlockHashesMsg和NewBlockMsg时被调用;peer.MarkTransaction在处理TxMsg时被调用。
发送
peer对象还负责给对方发送数据,这主要由一些send方法实现的,它们的命名很容易理解,因此这里不再一一列举。其有基本上每个数据都有同步发送和异步发送的方式。发送数据的实现很简单,这里不再详细说明了。
Head数据的更新
这里所谓的“Head数据”,是指peer.head和peer.td字段,这两个数据记录着对方节点的主链上最新的区块的哈希,和主链上的TD。
前面我们提到过,在发起同步时的"BestPeer"选取的是所有连接中TD值最大的那个。但这个TD值是缓存在本地的,如果对方的TD发生了变化,我们本地怎么能知道并及时更新呢?
想要解决我这个问题,我们先看看代码中哪些地方修改了peer.td 这个字段。经过查找只有peer.SetHead这个方法。而调用这个方法的代码只有处理NewBlockMsg消息时:
func (pm *ProtocolManager) handleMsg(p *peer) error {
......
switch {
case msg.Code == NewBlockMsg:
......
if _, td := p.Head(); trueTD.Cmp(td) > 0 {
p.SetHead(trueHead, trueTD)
......
}
}
}也就是说只有收到对方的NewBlockMsg消息,我们才有可能更新对方的Head数据。在前面分析NewBlockMsg和NewBlockHashesMsg的小节里,我们已经分析过有两种情况对方有可能会发出NewBlockMsg消息:
- fetcher模块中将一个同步到的区块加入到本地数据库前
- 本地挖矿模块出了一个新的区块时
之所以说有可能,原因之一是需要对方认为我们没有将要广播的区块,才会发NewBlockMsg消息给我们(即对方的peer.knownBlocks中没有将要发出的区块)。
而fetcher在什么情况下会得到一个区块并将其加入到本地数据库中呢?经过分析ProtocolManager对象是如何使用ProtocolManager.fetcher字段的,可以发现在处理NewBlockHashesMsg时会调用fetcher.Notify;而在处理NewBlockMsg时会调用fetcher.Enqueue。这两个方法都会导致将一个区块加入本地数据库中。
因此我们可以说,当发生以下任意一种情况时,且对方认为我们没有它将要广播的区块时,就会发NewBlock消息给我们,让我们有机会更新它的Head数据:
- 对方挖矿模块挖出一个新区块
- 对方收到NewBlockMsg消息
- 对方收到NewBlockHashesMsg消息并成功获取到其中的哈希代表的区块
这里要注意一点的是,“对方认为我们没有它将要广播的区块”这一前提使得在有些情况下并不能使自己最新的Head数据及时让其它节点知道。比如某对方节点A虽然一直在更新,但它的本地记录(peer.knownBlocks)显示自己要广播的区块我们都有,就不会发送NewBlockMsg给我们,我们自然也就不会及时更新A节点的Head数据。但这不重要,因为A节点有的区块其它节点都有,我们也没必要从A这同步数据。
总结
我们在这篇文章里主要分析了以太坊区块同步协议框架的实现。以太坊会在ProtocolManager中设置有新连接时的回调函数,当这个函数返回时,连接断开。当有新连接加入时会与其“握手”交换一些基本信息(statusData),随后循环调用ProtocolManager.handleMsg对接收到的消息进行处理。
由于所有消息都由ProtocolManager.handleMsg接收处理,而消息发起方可能有fetcher或downloader模块。因此当handleMsg接收到一些回复消息时,就先将数据送给fetcher过滤,fetcher留下自己发起的消息返回的数据,返回其它数据。这些其它数据再全部被送给downloader。
ProtocolManager还会定时或在有新节点接入时发起区块同步。区块同步的逻辑主要是在downloader中实现的,本篇文章没有涉及downloader模块。
handleMsg对接收到的消息进行处理,而代表每一个连接的peer对象则具体负责发送消息。此外peer对象还保存了对方连接的一些“已知的数据”,这些数据让我们自己知道对方应该已经有了哪些区块、哪些交易,这样我们在广播数据时就可以避免给拥有这些数据的节点广播,从而避免了流量的浪费。