本文为 Geth 客户端有问必答系列的第一篇文章,大家可以就 Geth 客户端的问题踊跃提问,我会每周用一篇小文章回答得票最高的问题。本周呼声最高的问题是:你能说说 flat 数据库结构与 legacy 结构的主要区别吗?
以太坊的状态
在深入了解加速结构(acceleration structure)之前,我们先回顾一下以太坊的 “状态” 概念、在涉及到不同层次的抽象时又是如何存储的。
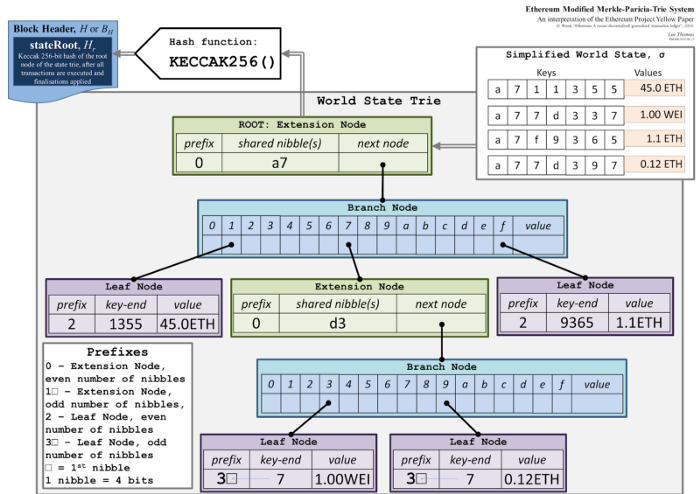
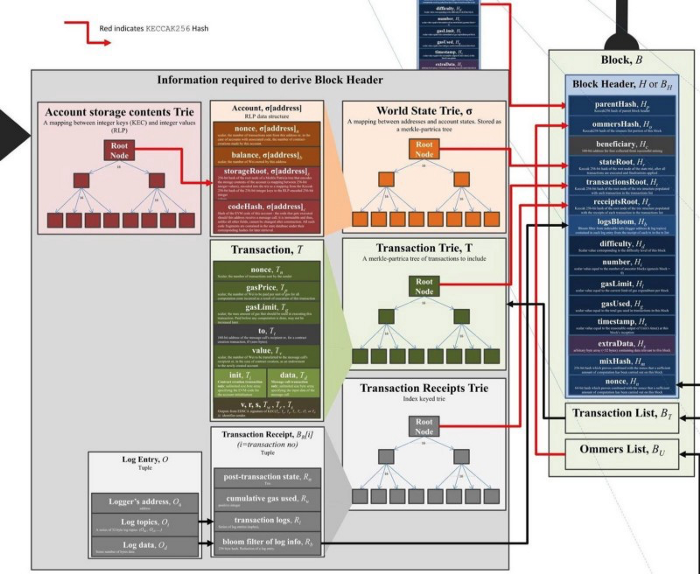
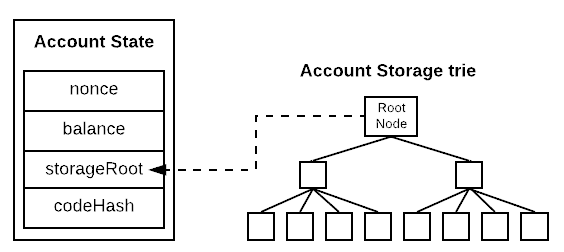
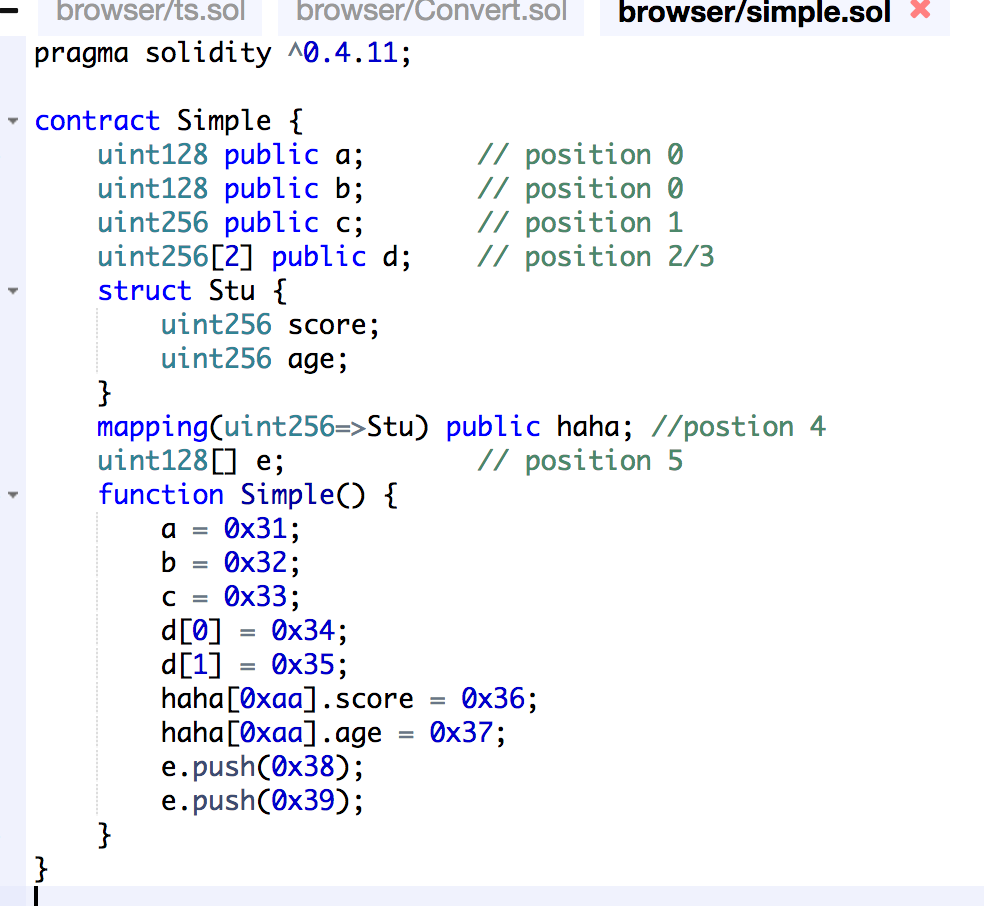
以太坊有两种不同类型的状态:账户的集合;每一合约账户存储槽的集合。从 完全抽象的角度 来看,两种数据都是 键-值 对。账户集合把地址映射到该地址的 nonce、余额,等等。而一个合约的存储领域把任意的值(由该合约定义并使用)映射到某个值。
但糟糕的是,虽然把这些键值对存储成扁平数据(flat data)可以非常高效,但验证它们的正确性在计算上就会变得很难。每当对数据修改时,我们都要自下而上对所有数据做哈希运算。
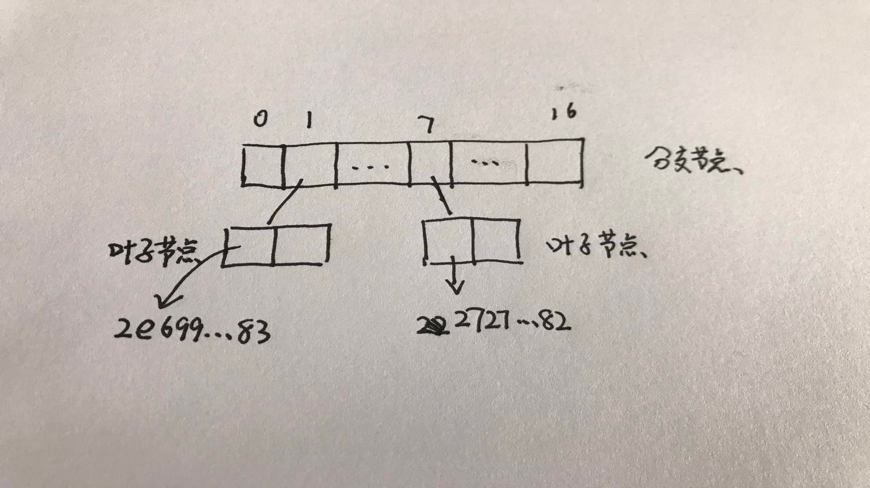
为免去总是对整个数据库做哈希运算的需要,我们可以把数据库分割成连续的小片,然后建立出一种树状结构!最原始、最有用的数据就放在叶子节点上,然后树上每一个内部节点都是该节点以下内容的哈希值。如此一来,当我们要修改某些值时,就只需做对数次的哈希运算。这种数据结构其实有一个路人皆知的名字,就是 “默克尔树”。
但还没完,这种办法在计算复杂性上还是有所欠缺。默克尔树结构虽然在修改现有数据时非常高效,但是,如果插入数据和删除数据会更改底层小数据块的边界,那就会让所有已经算好的哈希值全都变为无效。
这时候,与其盲目地对数据库分组,我们可以使用键本身来组织数据、基于共同前缀将数据都安排到树状格式中!这样插入和删除操作都不会影响到所有节点,只会影响到从树根到叶子路径上的(对数个)节点。这种数据结构就叫 “帕特里夏树”。
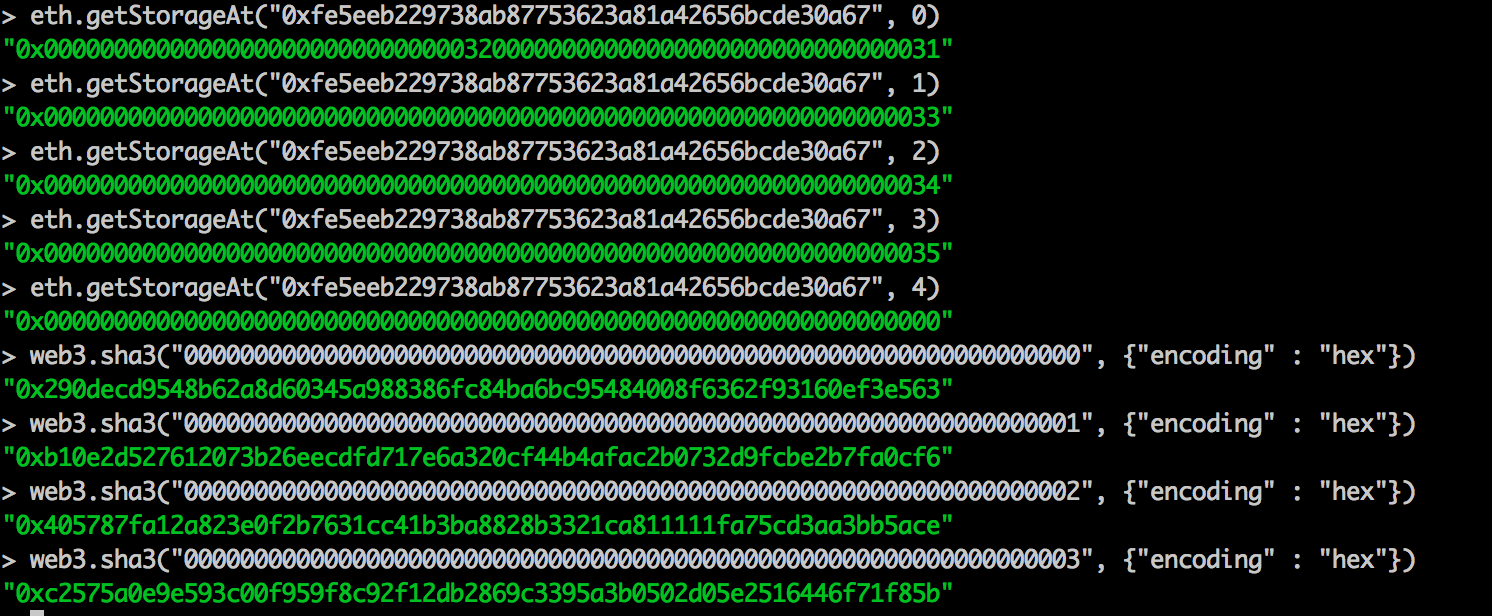
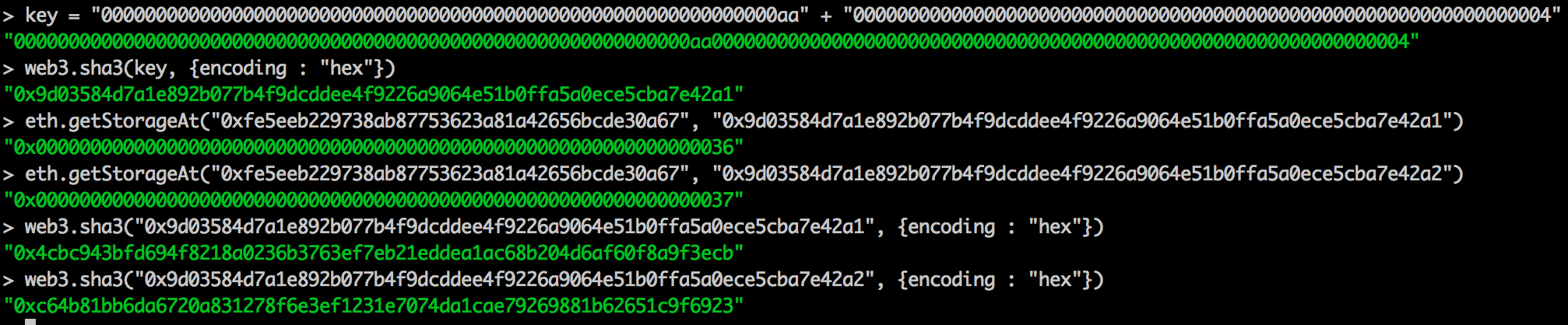
把上面两种办法合在一起 —— 帕特里夏树的树状分层和默克尔树的哈希算法 —— 就是所谓的 “默克尔-帕特里夏树”,也是实践中用于代表以太坊状态的数据结构。无论是修改、插入、删除还是验证,都只有对数复杂度!唯一的小小例外是,有些键会在插入前做哈希运算(存入树中),以平衡整棵树(A tiny extra is that keys are hashed before insertion to balance the tries)。
以太坊的状态存储
上文解释了为什么以太坊要用默克尔帕特里夏树结构来存储其状态。遗憾的是,虽然所需操作的速度都很快,但每一种选择都有所牺牲。更新操作和验证操作的对数复杂性 意味着对 每一个单独的密钥 的读取和存储都是对数复杂的(logarithmic reads and logarithmic storage)。这是因为树状结构的每一个内部节点都要单独保存在硬盘上。
此时此刻,账户树的深度确切是多少我不知道,但在大约一年以前,账户状态就已填满了 7 层高的树。这就意味着,每一次树操作(例如读取余额、写入 nonce)都要触达至少 7~8 个内部节点,因此会做至少 7~8 次持久数据库访问(persistent database accesses)。LevelDB 组织数据时最多也是 7 层,所以还有一个额外的乘数。最终的结果是,单次 状态访问预计会放大为 25~50 次随机的 硬盘访问。你再乘上一个区块中的所有交易的所有状态读取和写入,你会得到一个 吓人 的数字。
[当然,所有客户端实现都在尽力降低开销。Geth 使用更大的内存区域来缓存树节点;还使用了内存内的修剪机制、避免将几个块之后就会删除的数据写入硬盘。不过这需要另外一篇文章才能讲清楚。]
可怕之处还在于,这个数字就是运行一个以太坊节点、保证能全时验证所有状态的成本。
我们能做得更好一点吗?
并不是所有访问都要一视同仁
以太坊的运行依赖于对状态的密码学证明。只要我们还想保持对所有数据的验证能力,就绕不开硬盘读写放大问题。也就是说,我们 —— 可以并且也事实上 —— 相信我们已经验证过的数据。
不断重复验证每一个状态物是没有意义的,但如果每次从硬盘中拉取数据都要验证一次的话,就是在做这样没有意义的事。默克尔帕特里夏树结构本质上是为写入操作设计的,但反过来就成了读取操作的负担。我们摆脱不了它,也无法让它瘦身,但 这绝不意味着 我们在每一个场合都必须使用它。
以太坊节点访问状态的场景可大致分为以下三类:
- 在导入一个新区块的时候,EVM 代码的执行会产生或多或少基本平衡的状态读取和写入次数。不过,一个用于拒绝服务式攻击的区块可能会产生远多于写入操作的读取操作次数。
- 当节点运营者检索状态的时候(例如调用 eth_call 及类似操作),EVM 代码执行仅产生读取操作(当然也可能有写入操作,但这些操作产生的数据最终会丢弃掉,不会持久化到硬盘里面)。
- 当节点在同步区块链的时候,同步者会向远程节点请求状态,被请求者会将数据挖掘出来并通过网络传播给同步者。
基于上述访问模式,如果我们可以短路(short circuit)读取操作而不触及状态树,则许多节点操作都可以变得快 很多。这样甚至能开启一些新奇的访问模式(比如状态迭代),让原来因为太过昂贵而不可行的模式变为可能。
当然,还是不免有所牺牲。没有去掉树结构,任何新的加速结构都会带来额外的开销。问题只在于:额外的开销是否能带来足够多的好处,值得我们一试?
请循其本
我们已经开发出了神奇的默克尔帕特里夏树结构来解决我们所有的问题,现在,我们希望让读取操作能绕过它。那么,我们应该用什么样的加速结构来让读取操作重新变得快起来呢?显然,如果我们不需要树结构,那就大可以把伴随树结构而生的复杂性都丢在一边,我们可以直接回到原始状态。
如同在本文开头说到的那样,理论上的理想状态下 以太坊状态的数据存储方式应是简单键值对,没了默克尔帕特里夏树构成的限制,那就没有什么能阻止我们去实现这种理想方案了!
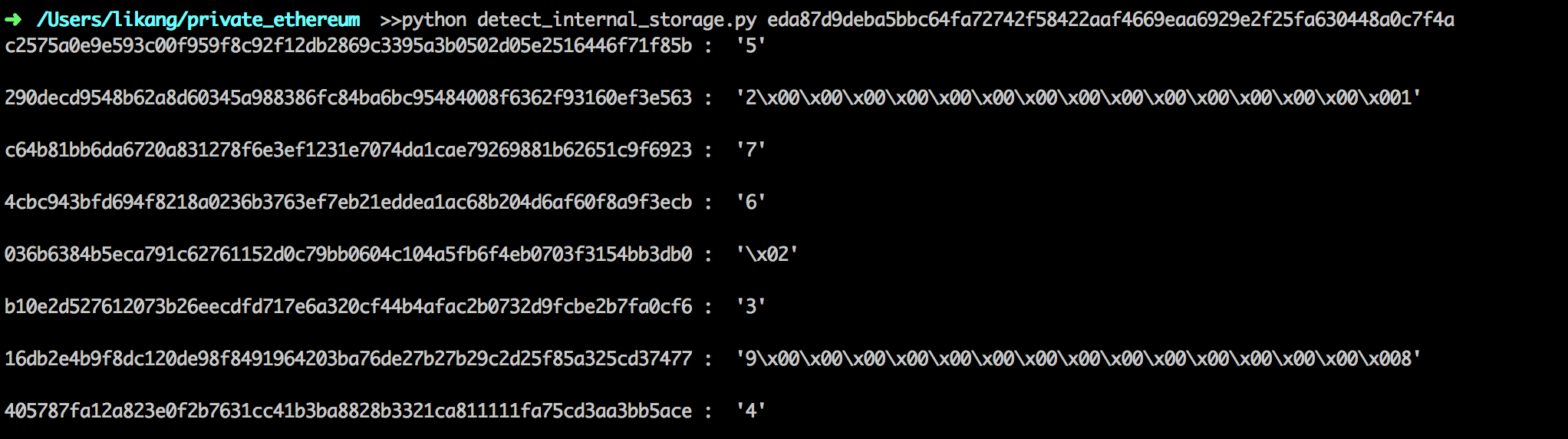
不久之前,Geth 引入了 snapshot(快照)加速结构(不是默认开启的)。一个快照就是给定一个区块处的以太坊状态的完整视图。抽象掉实现方面的细节,它就是把所有账户和合约存储槽堆放在一起,都由扁平的键值对来表示。
每当我们想要访问某个账户或者某个存储槽的时候,我们只需付出一次 LevelDB 的查询操作即可,而不用在每棵树上查询 7~8 次。理论上来说,更新快照也很简单,处理完一个区块后,我们只需为每个要更新的存储槽多做 1 次额外的 LevelDB 写入操作即可。
快照加速结构实际上将读取操作的计算复杂性从 O(log n) 降到了 O(1) (乘以 LevelDB 的开销),代价是将写入操作的计算复杂性从 O(log n) 变成了 O(1 + log n) (乘以 LevelDB 的开销),并将硬盘存储空间从 O(n log n) 增加到了 O(n + n log n)。
魔鬼藏在细节中
维持以太坊状态快照的可用性也不容易。只要区块还在一个接一个地产生,一个接一个地摞在最后一个区块上,那将最新变更合并到快照中的粗疏办法就能正常工作。但是,哪怕有微小的区块链重组(即便只有一个区块),快照机制就崩溃了,因为根本没有设计撤销操作。对扁平数据表示模式来说,持久化写入是单向的操作。而且让事情变得更糟糕的是,我们没办法访问更老的状态了(例如某些 dApp 需要 3 个区块以前的状态;或者 fast/snap 同步模式中要访问 64 个区块以前的状态)。
为了克服这些限制,Geth 客户端的快照由两部分组成:一部分持久化的硬盘层,是对旧区块(例如顶端区块前 128 个区块)处状态的完整快照;还有一棵内存内 diff 层组成的树,用于收集最新的写入操作。
处理新区块的时候,我们不会直接合并这些写入操作到硬盘层,而仅仅是创建一个新的、包含这些变更的内存内 diff 层。当内存内部的 diff 层积累到足够高的层数时,最底部的一个就开始合并更新并推到硬盘层。当需要读取一个状态物时,我们就从最顶端的 diff 层开始查找,一直往下,直至在 diff 层中或者在硬盘层中找到。
这种数据表示方法非常强大,解决了很多问题。因为内存内部的 diff 层组成了一棵树,所以 128 个区块以内的链重组只需取出属于父块的 diff 层,然后就此开始构建即可。需要较旧状态的 dApp 和远程同步者可以访问到最近 128 个最近的状态。开销变成了 128 次映射查找,但 128 次内存内的查找比起 8 次硬盘读取及 Level DB 的 4~5 倍放大要快上几个数量级。
当然,这里面还有很多很多的坑。就不讲太深了,简单列举就有下面这张清单:
- Self-destruct (合约自毁操作)(以及删除操作)特别难以对付,因为它们需要短路 diff 层的沉降(descent)。
- 如果出现了比持久硬盘层更深的链重组,那现在的快照就要完全废弃掉、重新生成。整套操作非常昂贵。
- 在节点关机时,内存内的 diff 层需要持久化到日志并加载备份,不然重启之后快照就没用了。
- 使用最底层的 diff 层作为一个累加器,仅在其超过一定的内存使用时才刷新到硬盘。这就允许跨区块对同一存储槽执行去重写入操作(deduping write)。
- 要为硬盘层分配一个读取缓存,这样合约重复访问同一个古老的存储槽时硬盘才不会损坏。
- 在内存内 diff 层中使用累积的布隆过滤器(bloom filter),以便快速检测出状态物有没有可能存在于 diff 层中,还是应该直接跳到硬盘中查找。
- 不把原始数据(账户地址、合约存储键)设为键,而是以这些数据的哈希值为键,以保证快照的迭代顺序与默克尔帕特里夏树相同。
- 生成持久化硬盘层的时间要比剪除状态树窗口的时间多得多,所以即使是生成器,也需要动态地追踪链的运行。
美丑并存
Geth 的快照加速结构将状态读取的复杂性降低了一个数量级。这就意味着基于读取操作的 DoS 攻击的发动难度上了一个数量级,而 eth_call 调用也快了一个数量级(假设 CPU 不存在瓶颈的话)。
快照还让对最近的块进行极速状态迭代成为可能。实际上这曾是我们开发快照机制的主要理由,因为我们可以此为基础创造新的 snap 同步算法。讲清楚它需要一篇全新的文章,但最近我们在 Rinkeby 测试网上的基准测试很能说明问题:

当然,这一切同样不是没有代价的。当初始同步完成之后,参与主网的节点需要 9~10 小时来建构初始快照(此后再维持其可用性),还需要额外的 15 GB 以上的硬盘。
那糟糕的部分是哪里呢?我们花了 6 个月时间才积累起足够的自信、发布了快照机制,而且现在它仍然不是默认功能,需要主动使用 --snapshot 标记来开启,而且还有一些围绕内存使用和崩溃恢复的打磨工作要做。
总而言之,对于这一提升,我们非常自豪。其中有巨大的工作量,而且是在黑暗中摸索、自己实现所有东西并祈祷它能工作。还有一个有趣的事情,第一个版本的快照同步(leaf sync)是在两年半以前写的,但一直都处于被阻塞的状态,因为我们缺乏必要的加速结构来驱动它。
结语
希望你能喜欢 Geth 客户端有问必答 的这一篇文章。我花了比自己所预想的多出一倍的时间,但我并不后悔,因为这个主题值得。下周见。
[又:我故意不在文章里留下 提问/投票 的网站,因为我确信这个活动只是暂时的,我不想留下一个没用的超链接,也不希望有人会在未来买下那个域名并托管恶意信息。你可以在我的 Twitter 中找到那个网站。]
(完)
原文链接: https://blog.ethereum.org/2020/07/17/ask-about-geth-snapshot-acceleration/
作者: Péter Szilágyi
翻译: 阿剑
本文由原作者授权 EthFans 翻译及再出版。
转载自:https://ethfans.org/posts/ask-about-geth-snapshot-acceleration