前言
就如以太坊黄皮书讲的,以太坊是状态机,区块的产生,实际是状态迁移的过程。那以太坊
- 是如何定义状态的?
- 是如何迁移状态的?
- 是怎么存储状态的?
这篇文章就介绍什么是状态,以及是怎么存储的。
状态基本知识
状态的定义
一个账户的信息,就是一个状态,而以太坊是所有状态的集合。比如,最开始的状态是:{A有10元,B有0元},后来A发起了交易,给B 2元,状态变成{A有8元,B有2元},这中间的过程就是状态转移。
以太坊实际最初的状态是创世块,每产生一个新区块就转移到一个新的状态。
状态表示
以太坊使用root表示状态。以太坊使用Trie组织状态,Trie可以理解为是字典树和默克尔树的结合,它有一个树根root,有这个root,你就可以访问所有的状态数据,即每个账户的信息,所以用root来表示一个状态。
获取状态
区块头中有一个字段Root,所以找到区块头,就能获取区块链的状态。
状态存在哪
状态不存在区块中。区块头中存放了root,这只是一个地址,从区块中并不能找到状态的数据。
状态只是临时的数据,可以再生成。创世块是最初的状态,把第一个区块中的交易都执行一遍,就得到了一个新的状态,把这个状态的root存到第一个区块头的Root中。如果有所有的区块,就可以把所有的交易都执行,然后生成最新区块中的状态。
状态存放在外部数据库。以太坊底层的数据库是LevelDB,区块存放在里面,状态也存放在里面。但状态是一个Trie,不能直接存在LevelDB里面。
StateDB
StateDB,从名字就能看出来,是用来存储状态的数据库。它把Trie和DB结合了起来,实现了对状态的存储、更新、回滚。我们先介绍它的设计思路,然后再介绍一些它的骨干实现。
StateDB的设计
以太坊使用LevelDB作为底层的存储数据库,虽然leveldb能够满足存取状态,但没有缓存功能、快速访问和修改状态等特性,以太坊实现了StateDB,来满足自身的需求。
我们就介绍下,它是如何设计来实现以上特性的。
底层存储设计
使用Trie实现快速访问。上文提到了,Trie是字典树和默克尔树的结合,可以实现快速查找,这里就看它是如何使用Trie的。
使用内存实现缓存。常用的数据,会被计算机留在内存中,同样,常用的状态也被留在内存中,并且使用StateDB把它们管理起来。
StateDB定义了2个接口:Trie和Database:Trie建立在Database之上,Trie的数据存放在Database中。

- Trie被定义为带有缓存的KV数据库。你可以通过它快速存储、更新、删除数据。
- Database被定义为一个打开Trie、拷贝Trie的数据库。它不直接对外访问,不能直接使用它存取数据。
在代码实现上,cachedTrie实现了Trie,cachingDB实现了Databse,他们定义在core/state/database.go
// 实现Database接口,缓存常用的trie
type cachingDB struct {
//保存trie数据的db
db *trie.Database
mu sync.Mutex
// 缓存过去的trie,队列类型
pastTries []*trie.SecureTrie
codeSizeCache *lru.Cache
}
// 包含了trie和缓存db,trie实际是存在db中的
type cachedTrie struct {
*trie.SecureTrie
db *cachingDB
}
//从db中打开一个trie,如果不是最近使用过,则创建一个新的,存到db
func (db *cachingDB) OpenTrie(root common.Hash) (Trie, error) {
db.mu.Lock()
defer db.mu.Unlock()
for i := len(db.pastTries) - 1; i >= 0; i-- {
if db.pastTries[i].Hash() == root {
return cachedTrie{db.pastTries[i].Copy(), db}, nil
}
}
tr, err := trie.NewSecure(root, db.db, MaxTrieCacheGen)
if err != nil {
return nil, err
}
return cachedTrie{tr, db}, nil
}StateDB的状态组织设计
StateDB使用Trie存放stateObject,是账户地址到账户信息的映射,每个stateObject都是一个账户的信息。
stateObject使用Trie存放数据,这些数据被称为storage,实现对某个账户的状态数据的存储和修改,key是数据的hash值,value是状态数据。
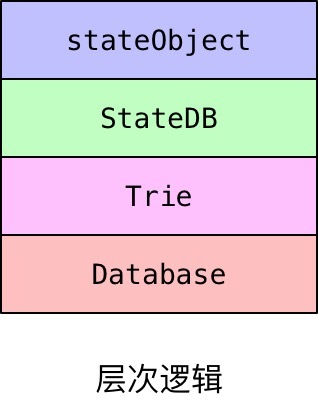
StateDB和stateObject都使用Database存放了自己的Trie,他们使用的是同一个DB。
但从逻辑层次上看,他们满足这种关系:
事务和回滚设计
stateDB这个KV数据库,实现了类似传统数据库的事务和回滚设计。每一个交易都是一个事务,每一个交易的执行,都是一次状态转移,在执行交易之前,先创建当前的快照,执行交易的过程中,会记录状态数据的每一次修改,如果交易执行失败,则进行回滚,交易执行完毕,会把所有修改的状态数据写入到Trie,然后更新Trie的根。
在生成1个区块的时候,会进行很多次Finalise,回滚是不能跨越交易的,也就是说,当前交易失败了,我不能回滚到上上一条交易。生成区块的时候,最后一次Finalize的Trie的Root,会保存到区块头的Header.Root。当区块要写入到区块链的时候,会执行一次Commit。

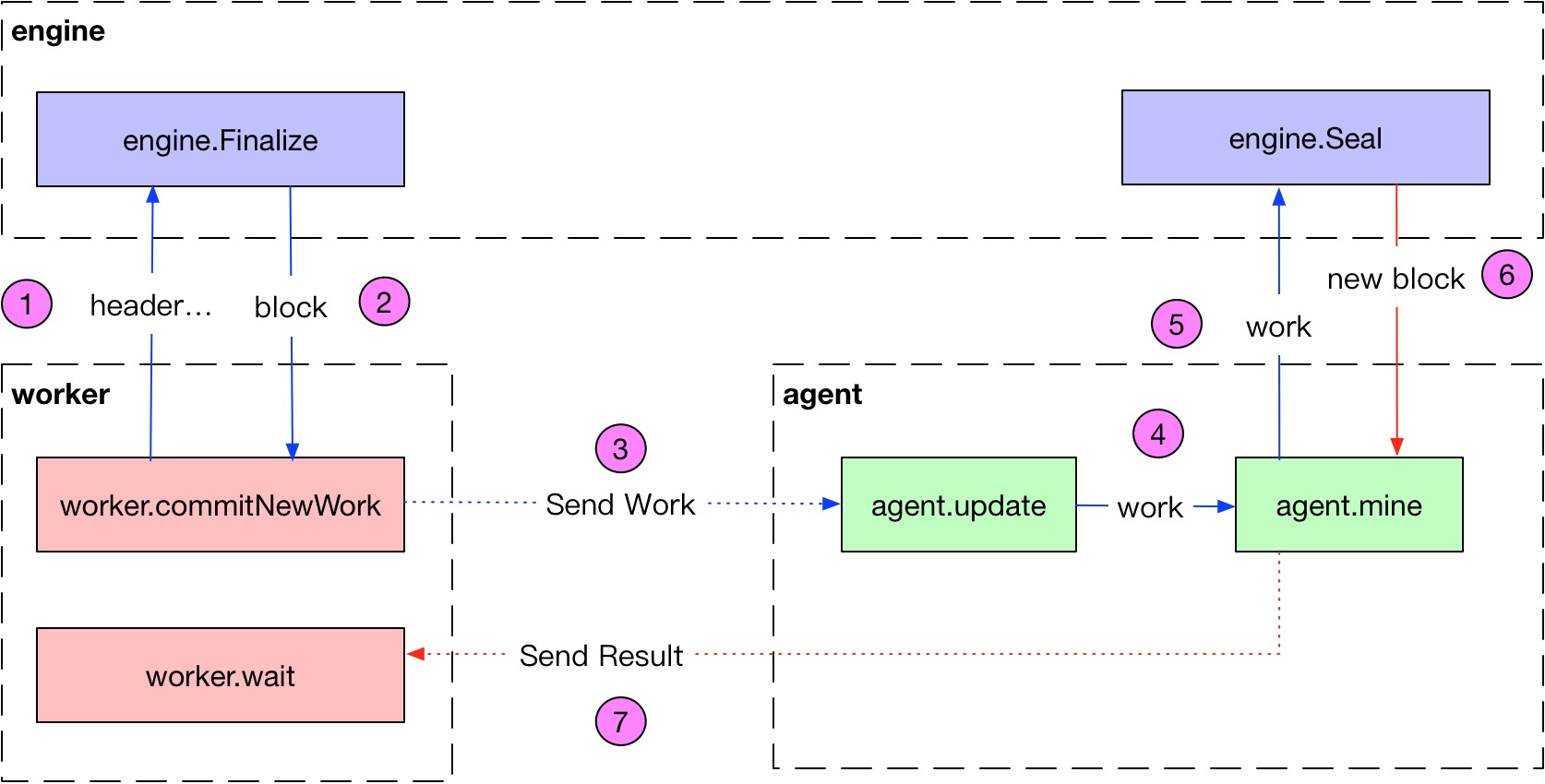
关于Finalise和Commit的主要调用关系如下图:
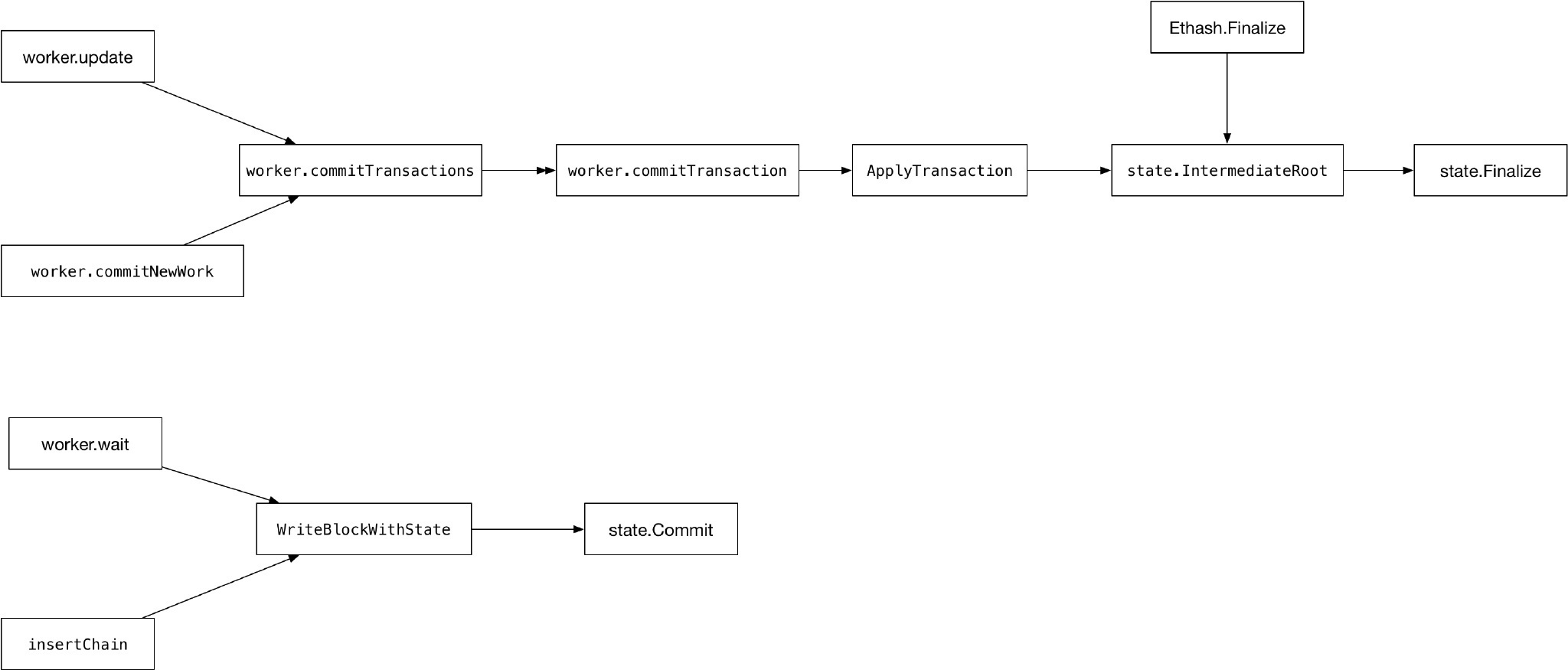
Finalise的主要调用场景是:
- 执行交易/合约,进行一次状态转移。
- 给矿工计算奖励后,进行一次状态转移。
Commit的主要调用场景是插入区块链,有2种情况:
- 自己挖到区块。
- 收到他人的区块。
StateDB的骨干实现
基于上面对StateDB设计的了解,我们再介绍一下StateDB一些主要的实现。这一小节主要覆盖以下内容:
- state所在的目录和文件划分。
- stateObject实现。
- stateDB的实现。
state目录和文件划分
state所在的目录是:core/state,它的文件和每个文件的主要功能如下:
core/state
├── database.go,底层的存储设计,`Trie`和`Database`定义在此文件。
├── dump.go,用来dumpstateDB数据。
├── iterator.go,用来遍历`Trie`。
├── journal.go,用来记录状态的每一步改变。
├── managed_state.go,给txpool使用,具体功能未研究。
├── state_object.go,每一个账户的状态。
├── statedb.go,以太坊整个的状态。
├── sync.go,用来和downloader结合起来同步state。关于stateDB如何存储状态,主要关注这3个文件:
- database.go
- state_object.go
- statedb.go
接下来通过源码介绍这3个文件的功能和实现。
database.go
database.go的主要代码和设计,已经在底层存储设计的时候介绍过了,这里补充介绍另外一个重要的函数OpenStorageTrie它与OpenTrie的区别:
- 实现区别,OpenTrie会先从db中查找,如果每找到才创建一个,而OpenStorageTrie是直接创建一个。
- 功能区别,OpenTrie创建的stateDB的Trie,而OpenStorageTrie创建的是stateObject的Trie。
把1和2合并:cachingDB会缓存stateDB使用的Trie,而不会缓存stateObject使用的Trie。
// OpenStorageTrie opens the storage trie of an account.
// 创建一个账户的存储trie,但实际没有使用到addrHash
func (db *cachingDB) OpenStorageTrie(addrHash, root common.Hash) (Trie, error) {
return trie.NewSecure(root, db.db, 0)
}
// OpenTrie opens the main account trie.
// 从db中打开一个trie,如果不是最近使用过,则创建一个新的,存到db
func (db *cachingDB) OpenTrie(root common.Hash) (Trie, error) {
db.mu.Lock()
defer db.mu.Unlock()
for i := len(db.pastTries) - 1; i >= 0; i-- {
if db.pastTries[i].Hash() == root {
return cachedTrie{db.pastTries[i].Copy(), db}, nil
}
}
tr, err := trie.NewSecure(root, db.db, MaxTrieCacheGen)
if err != nil {
return nil, err
}
return cachedTrie{tr, db}, nil
}state_object.go
该文件主要实现最小状态的存储和修改。stateObject代表最小粒度的状态,它是一个账户的状态信息。我们先看下基础的数据结构定义,再看它实现的主要功能。
账户和stateObject
以太坊的账户分为普通账户和合约账户,在代码上,他们都是用Account来表示,它记录了账户的数据,有:Nonce,余额,状态树根Root和合约代码的哈希值CodeHash。
// Account is the Ethereum consensus representation of accounts.
// These objects are stored in the main account trie.
// Account是账户的数据,不包含账户地址
// 账户需要使用地址来表示,地址在stateObject中
type Account struct {
// 每执行1次交易,Nonce+1
Nonce uint64
Balance *big.Int
// 该账户的状态,即trie的根
Root common.Hash // merkle root of the storage trie
// 合约账户专属,合约代码编译后的Hash值
CodeHash []byte
}以上是账户的数据,那如何表示一个账户呢?
使用账户地址表示账户,它记录在stateObject中:
// stateObject represents an Ethereum account which is being modified.
//
// The usage pattern is as follows:
// First you need to obtain a state object.
// Account values can be accessed and modified through the object.
// Finally, call CommitTrie to write the modified storage trie into a database.
// 地址、账户、账户哈希、数据库
type stateObject struct {
// 账户信息
address common.Address
addrHash common.Hash // hash of ethereum address of the account
data Account
code Code
// 更多信息省略
}所以 一个stateObject记录了一个完整的账户信息:Account + Address + Code。
再来看下stateObject的完整信息,它记录了:账户信息、EVM执行过程中的错误、保存数据的storage trie、合约代码、缓存的storage数据cachedStorage、修改过的storage数据dirtyStorage,剩下的信息先忽略。storage代表了该对象/账户中存储的KV数据。
type stateObject struct {
// 账户信息
address common.Address
addrHash common.Hash // hash of ethereum address of the account
data Account
// 所属于的stateDB
db *StateDB
// DB error.
// State objects are used by the consensus core and VM which are
// unable to deal with database-level errors. Any error that occurs
// during a database read is memoized http://lessisbetter.site/2018/06/22/ethereum-code-statedb/ and will eventually be returned
// by StateDB.Commit.
// VM不处理db层的错误,先记录下来,最后返回,只能保存1个错误,保存存的第一个错误
dbErr error
// Write caches.
// 使用trie组织stateObj的数据
trie Trie // storage trie, which becomes non-nil on first access
// 合约代码
code Code // contract bytecode, which gets set when code is loaded
// 存缓存,避免重复从数据库读
cachedStorage Storage // Storage entry cache to avoid duplicate reads
// 需要写到磁盘的缓存
dirtyStorage Storage // Storage entries that need to be flushed to disk
// Cache flags.
// When an object is marked suicided it will be delete from the trie
// during the "update" phase of the state transition.
dirtyCode bool // true if the code was updated
// 标记suicided,代表这个对象要从trie删除,在update阶段
suicided bool
deleted bool
}账户地址和账户信息是stateObject的核心数据,有他们2个就能建立一个stateObject:
// newObject creates a state object.
// 使用地址和账户创建stateObject
func newObject(db *StateDB, address common.Address, data Account) *stateObject {
if data.Balance == nil {
data.Balance = new(big.Int)
}
if data.CodeHash == nil {
data.CodeHash = emptyCodeHash
}
return &stateObject{
db: db,
address: address,
addrHash: crypto.Keccak256Hash(address[:]),
data: data,
cachedStorage: make(Storage),
dirtyStorage: make(Storage),
}
}stateObject的重要函数
stateObject保存了2个重要信息:
- 账户的信息:Account、Address、Code。创建账户之后,这些数据就不变了。
- 账户的数据:trie。对于合约账户,trie用来存储数据,因此trie是经常变化的。比如,投票合约,有新的投票,就有新的数据产生和改变,trie也就发生改变。
掌握关于trie的函数,就掌握了stateObject的核心操作:
- func (c *stateObject) getTrie(db Database) Trie。获取当前账户的trie。
- func (self *stateObject) SetState(db Database, key, value common.Hash)。设置trie中的kv数据对,能够完成创建、更新、删除功能。
- func (self *stateObject) updateRoot(db Database)。更新trie的根。
- func (self *stateObject) updateTrie(db Database) Trie。更新trie,把账户中修改过的数据写入到trie。
剩余的函数都是stateObject的基本Get和Set函数。
// 获取当前账户的trie,如果没有,则创建一个空的
func (c *stateObject) getTrie(db Database) Trie {
if c.trie == nil {
var err error
c.trie, err = db.OpenStorageTrie(c.addrHash, c.data.Root)
if err != nil {
c.trie, _ = db.OpenStorageTrie(c.addrHash, common.Hash{})
c.setError(fmt.Errorf("can't create storage trie: %v", err))
}
}
return c.trie
}
// SetState updates a value in account storage.
// 设置一个新的kv:保存过去的kv,然后设置新的。
func (self *stateObject) SetState(db Database, key, value common.Hash) {
self.db.journal.append(storageChange{
account: &self.address,
key: key,
prevalue: self.GetState(db, key),
})
self.setState(key, value)
}
// 先加入缓存和dirty
func (self *stateObject) setState(key, value common.Hash) {
self.cachedStorage[key] = value
self.dirtyStorage[key] = value
}
// updateTrie writes cached storage modifications into the object's storage trie.
// 把标记为dirty的kv写入、删除、更新到存储trie、
func (self *stateObject) updateTrie(db Database) Trie {
tr := self.getTrie(db)
for key, value := range self.dirtyStorage {
delete(self.dirtyStorage, key)
// 空value代表删除kv
if (value == common.Hash{}) {
self.setError(tr.TryDelete(key[:]))
continue
}
// Encoding []byte cannot fail, ok to ignore the error.
v, _ := rlp.EncodeToBytes(bytes.TrimLeft(value[:], "\x00"))
self.setError(tr.TryUpdate(key[:], v))
}
return tr
}
// UpdateRoot sets the trie root to the current root hash of
// 更新root:更新trie,然后获取新的root。Finalize使用
func (self *stateObject) updateRoot(db Database) {
self.updateTrie(db)
self.data.Root = self.trie.Hash()
}statedb.go
该文件主要实现stateDB的功能:
- 存储所有的账户信息(stateObject)。
- 提供增删、修改账户的状态数据(stateObject)的接口。
- Finalise和提交修改的账户信息(stateObject)。
- 对每个状态数据改变记录日志,创建快照,实现回滚。
接下来对这4个功能依次介绍。
存储账户信息
关于对stateObject的存储,之前是设计已经讲过其存储思路。现从StateDB的定义讲存储和管理stateObject:
- 使用trie来组织它所有的stateObject。
- 使用db存储trie。
- 使用stateObjects存储最近使用过的stateObject。
- 使用stateObjectsDirty存储被修改过的stateObject。
// StateDBs within the ethereum protocol are used to store anything
// within the merkle trie. StateDBs take care of caching and storing
// nested states. It's the general query interface to retrieve:
// * Contracts
// * Accounts
// 在merkle树种保存任何数据,形式是kv
type StateDB struct {
// 存储本Trie的数据库
db Database
// 存储所有的stateObject
trie Trie
// This map holds 'live' objects, which will get modified while processing a state transition.
// 最近使用过的数据对象,他们的账户地址为key
stateObjects map[common.Address]*stateObject
// 修改过的账户对象
stateObjectsDirty map[common.Address]struct{}
// DB error.
// State objects are used by the consensus core and VM which are
// unable to deal with database-level errors. Any error that occurs
// during a database read is memoized http://lessisbetter.site/2018/06/22/ethereum-code-statedb/ and will eventually be returned
// by StateDB.Commit.
dbErr error
// The refund counter, also used by state transitioning.
refund uint64
thash, bhash common.Hash
txIndex int
logs map[common.Hash][]*types.Log
logSize uint
preimages map[common.Hash][]byte
// Journal of state modifications. This is the backbone of
// Snapshot and RevertToSnapshot.
// 快照和回滚的主要参数
// 存放每一步修改了啥
journal *journal
// 快照id和journal的长度组成revision,可以回滚
validRevisions []revision
// 下一个可用的快照id
nextRevisionId int
lock sync.Mutex
}创建StateDB很简单,传入已知的root和使用的db即可。调用cachingDB.OpenTrie打开一个trie,该trie就用来存放所有的stateObject。
func New(root common.Hash, db Database) (*StateDB, error) {
tr, err := db.OpenTrie(root)
if err != nil {
return nil, err
}
return &StateDB{
db: db,
trie: tr,
stateObjects: make(map[common.Address]*stateObject),
stateObjectsDirty: make(map[common.Address]struct{}),
logs: make(map[common.Hash][]*types.Log),
preimages: make(map[common.Hash][]byte),
journal: newJournal(),
}, nil
}增删改和查询账户信息(状态数据)
创建账户。账户使用地址来标记,所以创建账户的时候要传入地址。如果当前的地址已经代表了一个账户,再执行创建账户,会创建1个新的空账户,然后把旧账户的余额,设置到新的账户,其他账户信息比如Nonce、Code等都设置为初始值了。
// CreateAccount explicitly creates a state object. If a state object with the address
// already exists the balance is carried over to the new account.
//
// CreateAccount is called during the EVM CREATE operation. The situation might arise that
// a contract does the following:
//
// 1. sends funds to sha(account ++ (nonce + 1))
// 2. tx_create(sha(account ++ nonce)) (note that this gets the address of 1)
//
// Carrying over the balance ensures that Ether doesn't disappear.
// 创建一个新的空账户,如果存在该地址的旧账户,则把旧地址中的余额,放到新账户中
func (self *StateDB) CreateAccount(addr common.Address) {
new, prev := self.createObject(addr)
if prev != nil {
new.setBalance(prev.data.Balance)
}
}
// createObject creates a new state object. If there is an existing account with
// the given address, it is overwritten and returned as the second return value.
// 创建一个stateObject,对账户数据进行初始化,然后记录日志
func (self *StateDB) createObject(addr common.Address) (newobj, prev *stateObject) {
prev = self.getStateObject(addr)
newobj = newObject(self, addr, Account{})
newobj.setNonce(0) // sets the object to dirty
if prev == nil {
self.journal.append(createObjectChange{account: &addr})
} else {
self.journal.append(resetObjectChange{prev: prev})
}
self.setStateObject(newobj)
return newobj, prev
}查询账户。getStateObject入参是账户地址,先查询缓存中是否存在账户,没有的话,再从trie中读取。有一点需要注意:trie中实际保存的stateObject中的Account数据,从trie中获取到Account信息后,然后再合成stateObject,它通常被查询账户数据的函数所使用。
GetOrNewStateObject是先查询一下stateObject,如果不存在则创建一个新的。通常是被Set系列函数在更新状态数据的时候使用。
// Retrieve a state object given by the address. Returns nil if not found.
// stateDB中使用trie保存addr到stateObject的映射,stateObject中保存key到value的映射
// 先从stateObjects中读取,否则从Trie读取Account,然后创建stateObject,存到stateObjects
func (self *StateDB) getStateObject(addr common.Address) (stateObject *stateObject) {
// Prefer 'live' objects.
if obj := self.stateObjects[addr]; obj != nil {
if obj.deleted {
return nil
}
return obj
}
// Load the object from the database.
enc, err := self.trie.TryGet(addr[:])
if len(enc) == 0 {
self.setError(err)
return nil
}
// trie中实际实际保存的是Account
var data Account
if err := rlp.DecodeBytes(enc, &data); err != nil {
log.Error("Failed to decode state object", "addr", addr, "err", err)
return nil
}
// Insert into the live set.
obj := newObject(self, addr, data)
self.setStateObject(obj)
return obj
}
// Retrieve a state object or create a new state object if nil.
// 获取stateObject,不存在则创建
func (self *StateDB) GetOrNewStateObject(addr common.Address) *stateObject {
stateObject := self.getStateObject(addr)
if stateObject == nil || stateObject.deleted {
stateObject, _ = self.createObject(addr)
}
return stateObject
}更新状态数据。stateObject的修改,修改后都暂存在stateDB.stateObjects中,当执行updateStateObject的时候,是把stateOject进行RLP编码,然后存到stateDB.trie中。
tire中实际保存的是stateObject的Account的RLP编码。因为stateObject实现了EncodeRLP函数,在RLP执行编码的时候,会调用该函数对stateObject进行编码,该函数实际只对state.data进行了编码。
// updateStateObject writes the given object to the trie.
// 把对象RLP编码,然后写到trie
func (self *StateDB) updateStateObject(stateObject *stateObject) {
addr := stateObject.Address()
data, err := rlp.EncodeToBytes(stateObject)
if err != nil {
panic(fmt.Errorf("can't encode object at %x: %v", addr[:], err))
}
self.setError(self.trie.TryUpdate(addr[:], data))
}
// EncodeRLP implements rlp.Encoder.
func (c *stateObject) EncodeRLP(w io.Writer) error {
return rlp.Encode(w, c.data)
}更新状态数据,就是一些列的Set函数了,这里就不讲了。
Finalise和Commit
Finalise和Commit是和存储过程紧密关联的2个函数,Finalise代表修改过的状态已经进入“终态”,Commit代表所有的状态都写入到数据库。我们使用下面这个图介绍一下。
- Finalise会把stateObjects写入到trie,并且计算trie的树根,但trie本身的所有节点,还在trie(trie暂时保存在内存)中,没有写入到trie数据库中。
- Commit要比Finalise深一步,它会把trie的所有节点写入到trie的数据库中,然后还会使用传入的回调函数处理trie的叶子节点。
我们再结合代码,看Finalise和Commit实现上的差异。Finalise处理的journal中标记为dirty的对象,不处理stateObjectsDirty中的对象,对于自杀的对象和空的对象,要把它们删除对象,降低trie的存储。然后,每向trie里写入1个对象,就会更新一次trie的根,然后才把对象加入到stateObjectsDirty,最后清空journal,因为这些journal已经过时了。
Commit会把journal中所有标记的对象加入到stateObjectsDirty,然后清空自杀和空的对象,把修改的对象写入到trie,把对象trie写入到数据库,最后把自己的trie写入到数据库。
// Finalise finalises the state by removing the self destructed objects
// and clears the journal as well as the refunds.
// 最终化数据库,遍历的日志中标记为dirty的账户,删除部分自杀、或空的数据,然后把数据写入存储trie,然后更新root,但每个对象都没有commit
func (s *StateDB) Finalise(deleteEmptyObjects bool) {
// 只处理journal中标记为dirty的对象,不处理stateObjectsDirty中的对象
for addr := range s.journal.dirties {
stateObject, exist := s.stateObjects[addr]
if !exist {
// ripeMD is 'touched' at block 1714175, in tx 0x1237f737031e40bcde4a8b7e717b2d15e3ecadfe49bb1bbc71ee9deb09c6fcf2
// That tx goes out of gas, and although the notion of 'touched' does not exist there, the
// touch-event will still be recorded in the journal. Since ripeMD is a special snowflake,
// it will persist in the journal even though the journal is reverted. In this special circumstance,
// it may exist in `s.journal.dirties` but not in `s.stateObjects`.
// Thus, we can safely ignore it http://lessisbetter.site/2018/06/22/ethereum-code-statedb/
continue
}
if stateObject.suicided || (deleteEmptyObjects && stateObject.empty()) {
s.deleteStateObject(stateObject)
} else {
// 把对象数据写入到storage trie,并获取新的root
stateObject.updateRoot(s.db)
s.updateStateObject(stateObject)
}
// 加入到stateObjectsDirty
s.stateObjectsDirty[addr] = struct{}{}
}
// Invalidate journal because reverting across transactions is not allowed.
// 清空journal,没法再回滚了
s.clearJournalAndRefund()
}
// 清空journal,revision,不能再回滚
func (s *StateDB) clearJournalAndRefund() {
s.journal = newJournal()
s.validRevisions = s.validRevisions[:0]
s.refund = 0
}
// Commit writes the state to the underlying in-memory trie database.
// 把数据写入trie数据库,与Finalize不同,这里处理的是Dirty的对象
func (s *StateDB) Commit(deleteEmptyObjects bool) (root common.Hash, err error) {
// 清空journal无法再回滚
defer s.clearJournalAndRefund()
// 把journal中dirties的对象,加入到stateObjectsDirty
for addr := range s.journal.dirties {
s.stateObjectsDirty[addr] = struct{}{}
}
// Commit objects to the trie.
// 遍历所有活动/修改过的对象
for addr, stateObject := range s.stateObjects {
_, isDirty := s.stateObjectsDirty[addr]
switch {
case stateObject.suicided || (isDirty && deleteEmptyObjects && stateObject.empty()):
// If the object has been removed, don't bother syncing it
// and just mark it for deletion in the trie.
s.deleteStateObject(stateObject)
case isDirty:
// Write any contract code associated with the state object
// 把修改过的合约代码写到数据库,这个用法高级,直接把数据库拿过来,插进去
// 注意:这里写入的DB是stateDB的数据库,因为stateObject的Trie只保存Account信息
if stateObject.code != nil && stateObject.dirtyCode {
s.db.TrieDB().Insert(common.BytesToHash(stateObject.CodeHash()), stateObject.code)
stateObject.dirtyCode = false
}
// Write any storage changes in the state object to its storage trie.
// 对象提交:把任何改变的存储数据写到数据库
if err := stateObject.CommitTrie(s.db); err != nil {
return common.Hash{}, err
}
// Update the object in the main account trie.
// 把修改后的对象,编码后写入到stateDB的trie中
s.updateStateObject(stateObject)
}
delete(s.stateObjectsDirty, addr)
}
// Write trie changes.
// stateDB的提交
root, err = s.trie.Commit(func(leaf []byte, parent common.Hash) error {
var account Account
if err := rlp.DecodeBytes(leaf, &account); err != nil {
return nil
}
// 如果叶子节点的trie不空,则trie关联到父节点
if account.Root != emptyState {
// reference的功能还没搞懂
s.db.TrieDB().Reference(account.Root, parent)
}
// 如果叶子节点的code不空(合约账户),则把code关联到父节点
code := common.BytesToHash(account.CodeHash)
if code != emptyCode {
s.db.TrieDB().Reference(code, parent)
}
return nil
})
log.Debug("Trie cache stats after commit", "misses", trie.CacheMisses(), "unloads", trie.CacheUnloads())
return root, err
}关于Commit保存对象信息的时候,还有1个重点关注:stateObject.Code并没有保存在stateObject.trie中,而是保存在stateDB.trie中。所以调用stateObject.Code获取合约代码的时候,实际传入的是stateDB.db,cachingDB.ContractCode实际也不使用合约的地址,因为(CodeHash, Code)本身就是作为KV存放在Trie中。
// Code returns the contract code associated with this object, if any.
// 从db读取合约代码,db实际是stateDB.db
func (self *stateObject) Code(db Database) []byte {
if self.code != nil {
return self.code
}
if bytes.Equal(self.CodeHash(), emptyCodeHash) {
return nil
}
code, err := db.ContractCode(self.addrHash, common.BytesToHash(self.CodeHash()))
if err != nil {
self.setError(fmt.Errorf("can't load code hash %x: %v", self.CodeHash(), err))
}
self.code = code
return code
}
// ContractCode retrieves a particular contract's code.
// 合约账户的code
func (db *cachingDB) ContractCode(addrHash, codeHash common.Hash) ([]byte, error) {
//addrHash无用
code, err := db.db.Node(codeHash)
if err == nil {
db.codeSizeCache.Add(codeHash, len(code))
}
return code, err
}日志和回滚
以太坊使用记录每一步状态的变化来支持回滚,每一步变化就是日志。假如从状态A转移到状态B,需要经过8步,在第1不的时候创建了snapshot,执行到第6步的时候出现了错误,回滚操作就是:把操作2,3,4,5步之前的数据,以5,4,3,2的顺序设置回去。

// Snapshot returns an identifier for the current revision of the state.
// 快照只是一个id,把id和日志的长度关联起来,存到Revisions中
// EVM在执行在运行一个交易时,在修改state之前,创建快照,出现错误,则回滚
func (self *StateDB) Snapshot() int {
id := self.nextRevisionId
self.nextRevisionId++
self.validRevisions = append(self.validRevisions, revision{id, self.journal.length()})
return id
}
// RevertToSnapshot reverts all state changes made since the given revision.
// 回滚到指定vision/快照
func (self *StateDB) RevertToSnapshot(revid int) {
// Find the snapshot in the stack of valid snapshots.
idx := sort.Search(len(self.validRevisions), func(i int) bool {
return self.validRevisions[i].id >= revid
})
if idx == len(self.validRevisions) || self.validRevisions[idx].id != revid {
panic(fmt.Errorf("revision id %v cannot be reverted", revid))
}
snapshot := self.validRevisions[idx].journalIndex
// Replay the journal to undo changes and remove invalidated snapshots
// 反操作后续的操作,达到回滚的目的
self.journal.revert(self, snapshot)
self.validRevisions = self.validRevisions[:idx]
}在journal.go中有更多的日志操作,以及每种类型操作需要记录的数据。
转载自:https://lessisbetter.site/2018/06/22/ethereum-code-statedb/