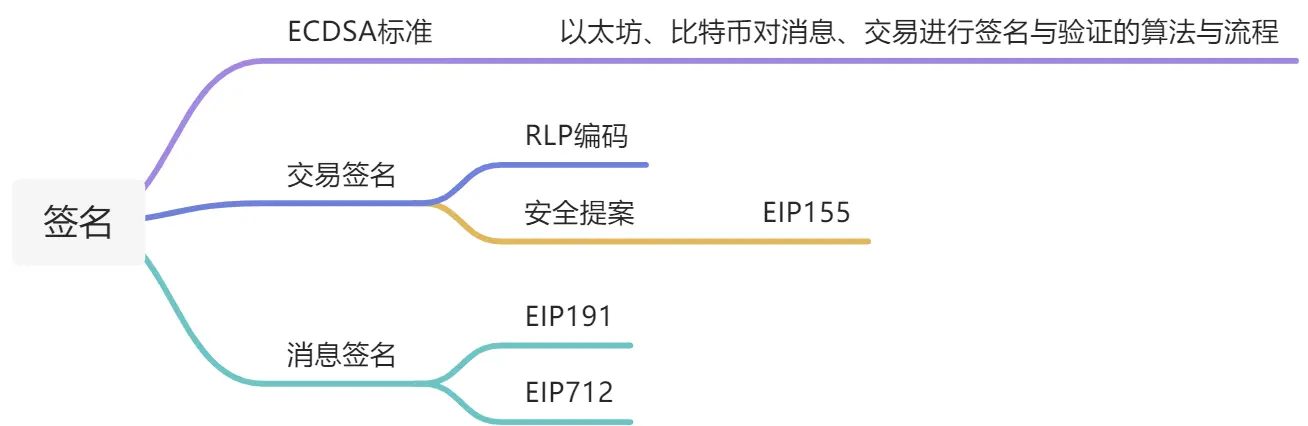
思维导图
我把以太坊签名分为对消息签名与对交易签名,这两种签名都是基于ECDSA算法与流程,本章就让我们来搞清楚两种签名具体的内容。
签名概述
签名的作用或目的?
- 身份认证:证明你拥有地址的私钥;
- 不可否认:确认你的确发布过该消息;
- 完整性:确保信息没有被篡改;
具体见维基百科:wikipedia签名的性质
什么是签名?
当我刚开始接触签名这个名词时,我也很困惑,此处的签名和现实世界中合同的签名有什么不同?当我签署一份租房合同,当我们租期到时,如果对屋内的物品所有损坏,房东可凭借这份合同上的内容对我进行索赔(扣押金),如果我进行抵赖,说我没签署过这份合同,那么房东可去司法机构进行签名笔迹认证。以太坊中的签名也是如此,在租房合同中签名是笔迹,在以太坊中的签名就是一段数据,这段数据的作用和我签署租房合同的签名笔迹没有任何不同,节点们(矿工们、验证者们)可以凭借这段数据进行身份认证,即证明这些消息就是我签署的(因为只有我拥有私钥),同时,我想抵赖也是不可能的,因为这段数据具备不可否认性,第三方也不可能对消息进行篡改,因为这段数据具备完整性。如果对上面阐述的内容暂时不理解也没关系,继续往下看,多看一些资料很快就会理解的。此时我们只需记住,以太坊或者计算机中这个"签名"与现实世界中的向"合同上签名"是一个意义。下面先概括一下以太坊的签名与验证过程:
- 签名过程:ECDSA_正向算法(消息 + 私钥 + 随机数)= 签名
- 验证过程:ECDSA_反向算法(消息 + 签名)= 公钥
在以太坊、比特币中这个算法是经过二开的ECDSA(原始的ECDSA只有r、s组成,以太坊、比特币的ECDSA由r、s、v组成)。
使用ECDSA签名并验证
什么是ECDSA
ECDSA可理解为以太坊、比特币对消息、交易进行签名与验证的算法与流程。在智能合约层面,我们不必多关注其算法的细节,只需理解其流程,看得懂已有项目代码,可以在项目写出对应功能代码即可。
流程
- 签名即正向算法(消息 + 私钥 + 随机数)= 签名,其中消息是公开的,私钥是隐私的,经过ECDSA正向算法可得到签名,即r、s、v(不用纠结与r、s、v到底什么,只需要知道这就是签名即可)。
- 验证即反向算法(消息 + 签名)= 公钥,其中消息是公开的,签名是公开的,经过ECDSA反向算法可得到公钥,然后对比已公开的公钥。
签名交易

关键词
- RLP:一种序列化的方式,其与网络传输中json的序列化/反序列化有一些不同,RLP不仅兼顾网络传输,其编码特性更确保了编码后的一致性,因为每笔交易过程中要进行Keccak256,如果不能保证编码后的一致性,会导致其Hash值不同,那么验证者就无法验证交易是否由同一个人发出。
若对上面的阐述不理解,继续看下面的内容。
编码方式详情见详解以太坊RLP编码(不用过度研究)。
- Keccak256 :以太坊的Hash算法,生成32个字节Hash值。
签名交易流程
1. 构建原始交易对象
- nonce: 记录发起交易的账户已执行交易总数。Nonce的值随着每个新交易的执行不断增加,这能让网络了解执行交易需要遵循的顺序,并且作为交易的重放保护。
- gasPrice:该交易每单位gas的价格,Gas价格目前以Gwei为单位(即10^9wei),其范围是大于0.1Gwei,可进行灵活设置。
- gasLimit:该交易支付的最高gas上限。该上限能确保在出现交易执行问题(比如陷入无限循环)之时,交易账户不会耗尽所有资金。一旦交易执行完毕,剩余所有gas会返还至交易账户。
- to:该交易被送往的地址(调用的合约地址或转账对方的账户地址)。
- value:交易发送的以太币总量。
- data:
- 若该交易是以太币交易,则data为空;
- 若是部署合约,则data为合约的bytecode;
- 若是合约调用,则需要从合约ABI中获取函数签名,并取函数签名hash值前4字节与所有参数的编码方式值进行拼接而成,具体参见文章Ethereum的合约ABI拓展
- chainId:防止跨链重放攻击。 ->EIP155
2. 签署交易
签署交易可使用MetaMask和ethers库。
- MetaMask
前端:使用MetaMask进行签名为前端技术栈,目前比较流行为nextjs+ethers,我对前端不太了解,这里不做展开。
- ethers库
后端:使用ethers库可以进行交易的签名,详情见如下代码:
const ethers = require("ethers")
require("dotenv").config()
async function main() {
// 将RPC与私钥存储在环境变量中
// RPC节点连接,直接用alchemy即可
let provider = new ethers.providers.JsonRpcProvider(process.env.RPC_URL)
// 新建钱包对象
let wallet = new ethers.Wallet(process.env.PRIVATE_KEY, provider)
// 返回这个地址已经发送过多少次交易
const nonce = await wallet.getTransactionCount()
// 构造raw TX
tx = {
nonce: nonce,
gasPrice: 100000000000,
gasLimit: 1000000,
to: null,
value: 0,
data: "",
chainId: 1, //也可以自动获取chainId = provider.getNetwork()
}
// 签名,其中过程见下面详述
let resp = await wallet.signTransaction(tx)
console.log(resp)
// 发送交易
const sentTxResponse = await wallet.sendTransaction(tx);
}
main()
.then(() => process.exit(0))
.catch((error) => {
console.error(error)
process.exit(1)
})
wallet.signTransaction中发生了什么?
- 对(nonce, gasPrice, gasLimit, to, value, data, chainId, 0, 0)进行RLP编码;
- 对上面的RLP编码值进行Keccak256 ;
- 对上面的Keccak256值进行ECDSA私钥签名(即正向算法);
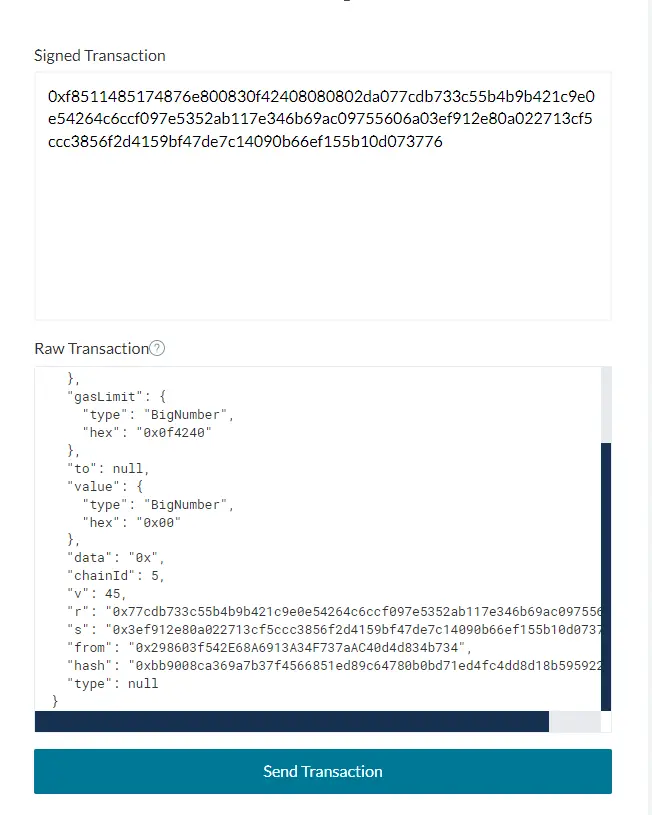
- 对上面的ECDSA私钥签名(v、r、s)结果与交易消息再次进行RPL编码,即RLP(nonce, gasPrice, gasLimit, to, value, data, v, r, s),可得到如下编码;
0xf8511485174876e800830f42408080802da077cdb733c55b4b9b421c9e0e54264c6ccf097e5352ab117e346b69ac09755606a03ef912e80a022713cf5ccc3856f2d4159bf47de7c14090b66ef155b10d073776
细心的同学可能会问,为什么步骤1中包含chainId字段,而步骤4中再次编码时没有chainId字段?原始消息内容都不一样,怎么可能会验证通过?先别急,这是因为chainId 是被编码到签名的 v参数中的,因此我们不会将chainId本身包含在最终的签名交易数据中(下面一小节也有阐述)。当然,我们也不会提供任何发送方地址,因为地址可以通过签名恢复。这就是以太坊网络内部用来验证交易的方式。
验证过程
交易签名发送后,以太坊节点如何进行身份认证、不可否认、完整性?
- 对上面最终的RPL解码,可得到(nonce, gasPrice, gasLimit, to, value, data, v, r, s);
- 对(nonce, gasPrice, gasLimit, to, value, data)和(v,r,s)ECDSA验证(即反向算法),得到签名者的address,细心的同学可以看到第一个括号少了chainId,这是因为chainId在ECDSA私钥签名(即正向算法) 时被编码到了v,所以由v可以直接解码出chainId(所以在对上面的RLP编码值进行Keccak256;这一步,肯定是把chainId复制了一下,给对上面的Keccak256值进行ECDSA私钥签名(即正向算法);这一步用);
- 对上面得到的签名者的address与签名者公钥推导的address进行比对,相等即完成身份认证、不可否认性、完整性
我们可以去MyCrypto - Ethereum Wallet Manager,将wallet.signTransaction生成的编码复制进去,对上述验证步骤有一个直观的感受,比对一下ECDSA反向算法得出的"from"是不是自己的地址?
安全问题
我们注意到原始交易对象里由Nonce和ChainID两个字段,这是为了防范双花攻击\重放攻击(双花与重放是相对的,本质都是重复使用一个签名,用自己的签名做对自己有利的重复叫双花,用别人的签名做对自己有利的重复叫重放):
- Nonce:账户交易计数,以太坊的账户模型中记录着每个账户Nonce,即此账户发起过多少次交易。
- ChainId:分叉链区分,比如我在以太坊链上给evil进行一笔转账交易,evil又可以去以太坊经典链上重放这笔交易,这时如果我在以太坊经典上也有资产,那么会遭受损失。所以EIP155提议加入ChainId,以防止跨链重放。以太坊ChainId为1,以太坊经典ChainId为61。
节点验证之后的动作
这里和签名的关系不大,便不再详述,大体可以看看下面这个帖子:
https://blog.csdn.net/LJFPHP/article/details/81261050
签名消息( =presigned message = 预签名)
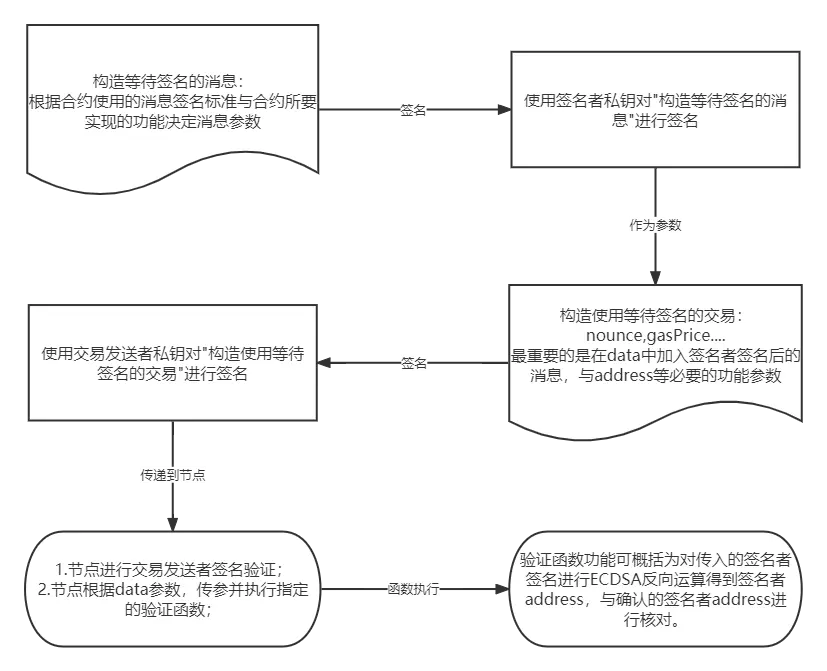
大家看完上面的签名交易后,再看本章的签名消息,可能会有有些懵的感觉,会将其混为一谈,误以为这两个东西是平行的,各自发给节点的。这是对以太坊交易流程不清晰导致的,只需记住一点,发给节点的只能是交易签名+相应参数,其大概可分为三种情况:
- 单纯的转账交易:就是上一章节的内容,由(nonce, gasPrice, gasLimit, to, value, data:空,chainId)经私钥通过ECDSA正向算法得到(v,r,s),将(nonce, gasPrice, gasLimit, to, value, data:空, v, r, s)发往节点。注意,这里data是空的。
- 部署合约交易:由(nonce, gasPrice, gasLimit, to:空, value, data:合约创建字节码,chainId)经私钥通过ECDSA正向算法得到(v,r,s),将(nonce, gasPrice, gasLimit, to:空, value, data:合约创建字节码, v, r, s)发往节点。注意,to是空的, data是合约创建字节码,节点看到to是空的就知道这是部署合约交易。不明白什么是合约创建字节码,可以看看OpenZeppelin这个系列文章,我对这系类文章有相应笔记,待后续整理发出。。
- 调用合约函数交易:由(nonce, gasPrice, gasLimit, to, value, data:selector+函数参数,chainId)经私钥通过ECDSA正向算法得到(v,r,s),将(nonce, gasPrice, gasLimit, to, value, data:selector+函数参数, v, r, s)发往节点。注意, data是selector+函数参数,例如bytes4(keccak256(bytes("foo(uint256,address,string,uint256[2])"))), x, addr, name, array。对于这个不明白的同样看上面OpenZeppelin文章即可。
综上,无论是部署合约交易还是调用合约函数交易都是改变data的值。 我们本章所讲的消息签名就是调用合约函数交易,调用对应合约函数(一般为验证verfiy函数),消息签名作为参数。
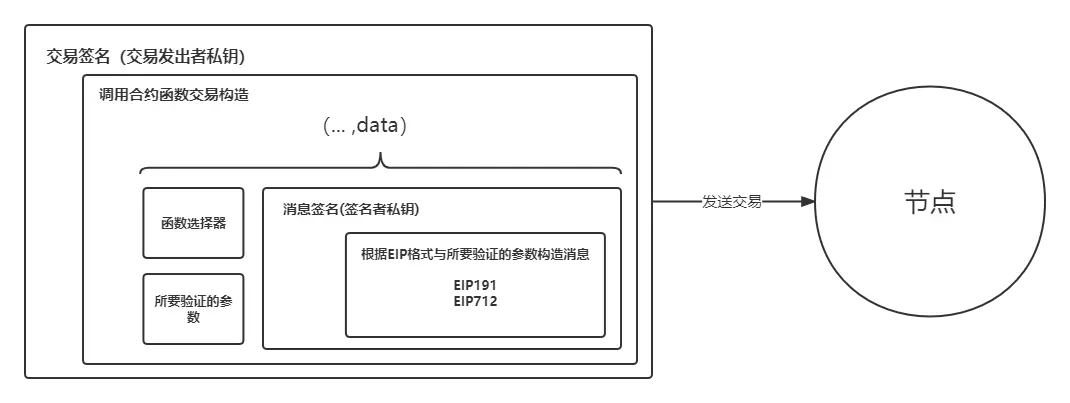
针对上面调用合约函数交易+消息签名的内容,我们配合流程图与层叠图加深理解:
流程图:
层叠图:
通用消息签名方法
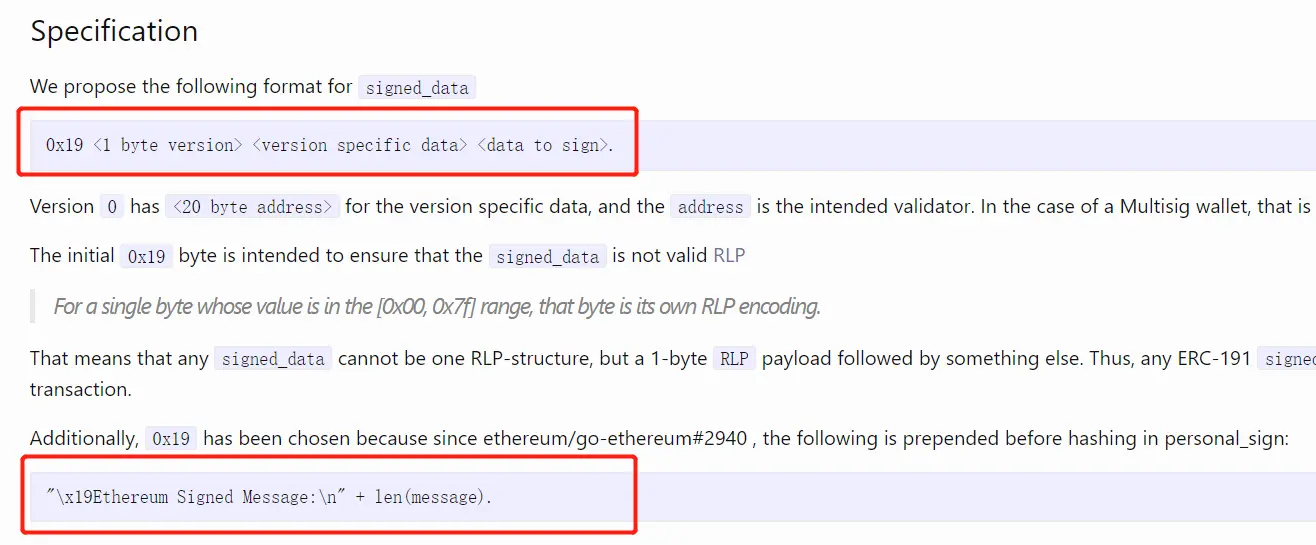
当我在看EIP-191这个提案时(https://eips.ethereum.org/EIPS/eip-191),有些困惑,其标准格式到底是第一个红框还是第二个红框?经过看网上资料和琢磨一定时间后,其中的逻辑应该是这样的,我们可以把签名方法划分为三种:
- 通用消息签名方法;
- EIP-191标准签名方法;
- EIP-712标准签名方法;
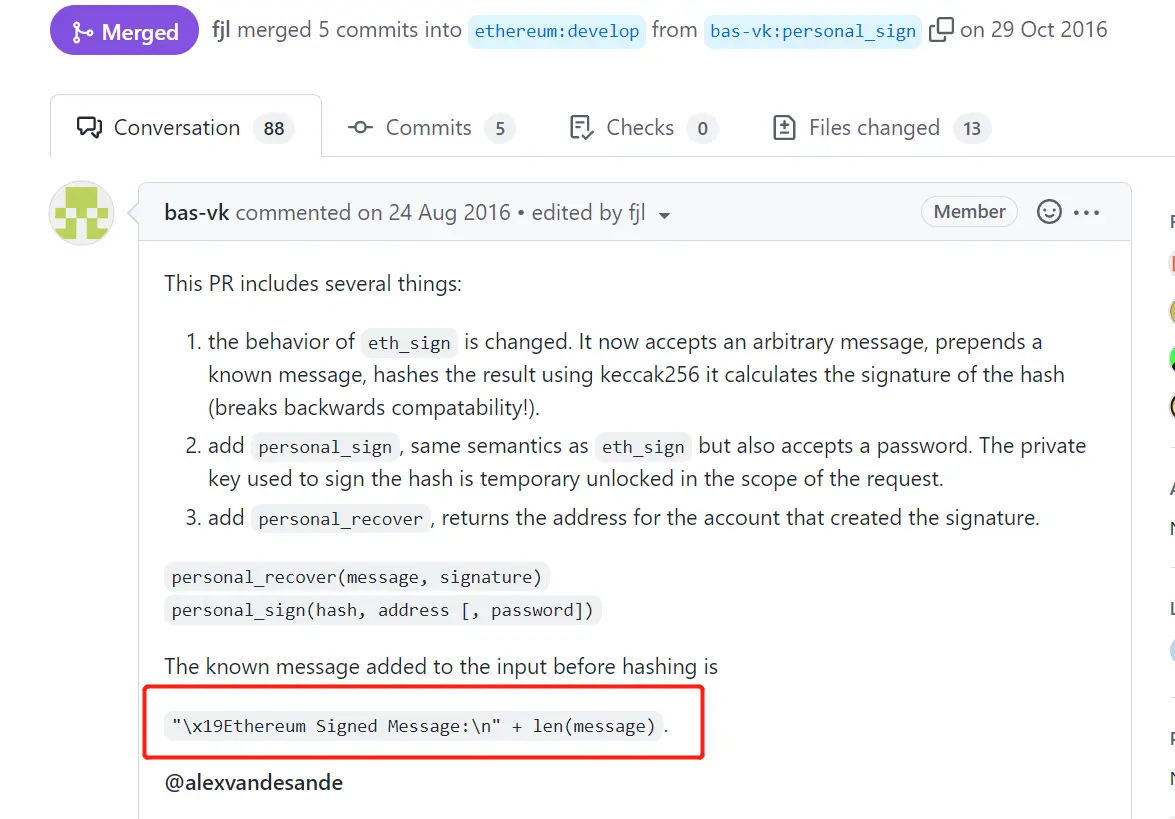
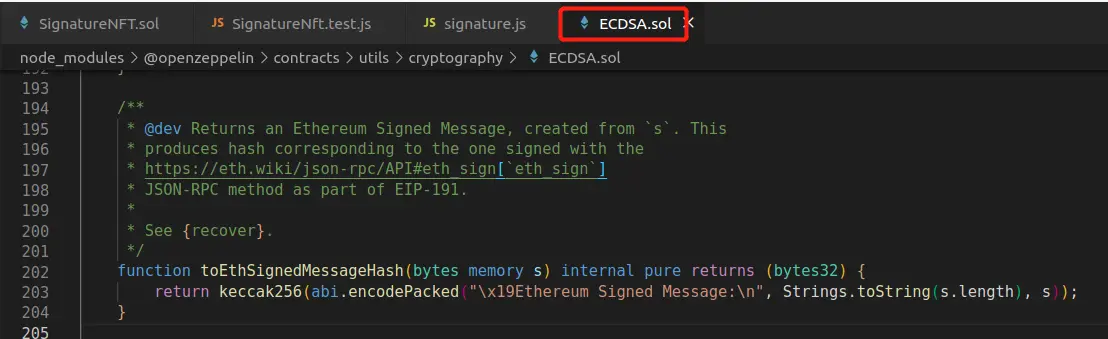
我们不用把他们想的太复杂,简单点来说通用签名方法就是添加了"\x19Ethereum Signed Message:\n"这个字符串的签名,如metamask的personal_sign方法和ECDSA库的toEthSignedMessageHash方法,添加这个字符串只是单纯的为了表明这是以太坊的签名,让我们看看通用签名方法的例子--NFT白名单。
metamask的personal_sign方法:
ECDSA库的toEthSignedMessageHash方法:
NFT白名单签名举例
让我们来写一个NFT白名单合约,想想如何实现白名单这个功能?
- 把白名单地址存入数组,当目标地址调用mint函数时进行判断。 ->因为storage会耗费大量gas,项目方还没开始赚钱在deploy合约时就先破产了。后续白名单用户在Mint对白名单数组的读opcode又会耗费大量gas,白名单用户本来就想占点便宜,结果还花费了大量gas。所以这个方法几乎没有人用。
- 用Merkle Tree来校验白名单,具体方法看0xAA师傅的这篇文章https://github.com/AmazingAng/WTF-Solidity/blob/main/36_MerkleTree/readme.md,这个方法的只需要storage一个root值,但相较于上面的方法已经非常节省gas。
- 对白名单进行链下签名,这个方法是当下通用的,以我们目前NFT这个例子来说,也会需要storage一个owner,但相较于Merkle Tree在白名单用户mint的时候会少传一个数组,少很多opcode,也就为用户节省了gas。下面让我们来实操一下。
前提
技术栈:hardhat(社区hardhat-deploy包)+ethers.js,以下我只针对于白名单这个知识点进行讲解,不涉及技术栈的知识。
我们将accounts[0]作为deployer和signer,account[1]、account[2]、account[3]作为白名单地址。
合约
import "@openzeppelin/contracts/utils/cryptography/ECDSA.sol";
import "@openzeppelin/contracts/token/ERC721/ERC721.sol";
error SignatureNFT__VerifyFailed();
contract SignatureNFT is ERC721 {
// signer address
address public immutable i_signer;
constructor(address signer) ERC721("Test Signature NFT", "TSN") {
// set signer address
i_signer = signer;
}
// mint NFT
function mintNft(
address account,
uint256 tokenId,
bytes memory signature
) public {
if (!verify(account, tokenId, signature)) {
revert SignatureNFT__VerifyFailed();
}
_safeMint(account, tokenId);
}
// Check if signer and i_signer are equal
function verify(
address account,
uint256 tokenId,
bytes memory signature
) public view returns (bool) {
address signer = recoverSigner(account, tokenId, signature);
return signer == i_signer;
}
// Return signer address
function recoverSigner(
address account,
uint256 tokenId,
bytes memory signature
) public pure returns (address) {
// 后招
bytes32 msgHash = keccak256(abi.encodePacked(account, tokenId));
bytes32 msgEthHash = ECDSA.toEthSignedMessageHash(msgHash);
address signer = ECDSA.recover(msgEthHash, signature);
return signer;
}
}
#### 签名脚本
- 逻辑:hash(签名参数) -> signMessage(hash(签名参数));
- 生产环境中,我们将signers[index].address换为白名单地址,将signers[0]换位signer即可;
```javascript
const { ethers } = require("hardhat")
// 对要签名的参数进行编码
function getMessageBytes(account, tokenId) {
// 对应solidity的Keccak256
const messageHash = ethers.utils.solidityKeccak256(["address", "uint256"], [account, tokenId])
console.log("Message Hash: ", messageHash)
// 由于 ethers 库的要求,需要先对哈希值数组化
const messageBytes = ethers.utils.arrayify(messageHash)
console.log("messageBytes: ", messageBytes)
// 返回数组化的hash
return messageBytes
}
// 返回签名
async function getSignature(signer, account, tokenId) {
const messageBytes = getMessageBytes(account, tokenId)
// 对数组化hash进行签名,自动添加"\x19Ethereum Signed Message:\n32"并进行签名
const signature = await signer.signMessage(messageBytes)
console.log("Signature: ", signature)
}
async function main() {
signers = await ethers.getSigners()
// 我们将accounts[0]作为deployer和signer,account[1]、account[2]、account[3]作为白名单地址
for (let index = 1; index < 4; index++) {
await getSignature(signers[0], signers[index].address, index)
}
}
main()
.then(() => process.exit(0))
.catch((error) => {
console.error(error)
process.exit(1)
})
部署脚本
在部署脚本中,我们直接用deployer作为constructor参数传入,即用deployer当作signer;
const { network, ethers } = require("hardhat")
module.exports = async ({ getNamedAccounts, deployments }) => {
const { deployer } = await getNamedAccounts()
console.log(deployer)
const { deploy, log } = deployments
const chainId = network.config.chainId
const args = [deployer]
await deploy("SignatureNFT", {
contract: "SignatureNFT",
from: deployer,
log: true,
args: args,
waitConfirmations: network.config.waitConfirmations || 1,
})
log("[==>]------Deployed!------------------------------------------")
}
module.exports.tags = ["SignatureNFT"]
我们就选取最后一个Signature,即项目方给accounts[3]的签名。
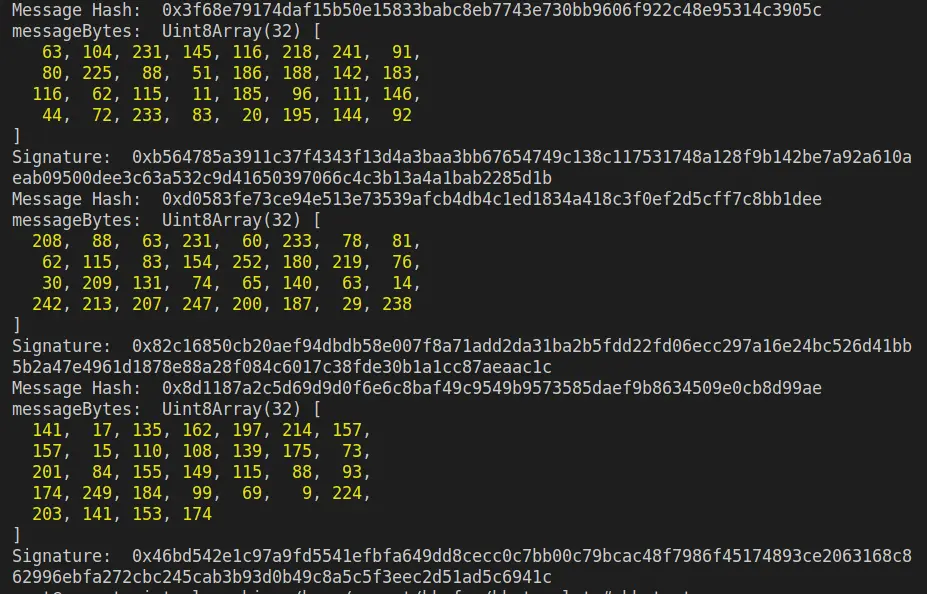
测试脚本
分别对每个函数进行测试,其中mintNft为模拟交易
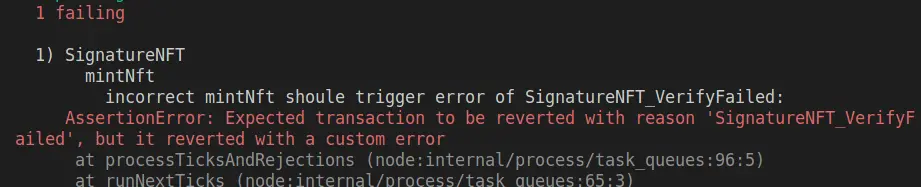
注意:
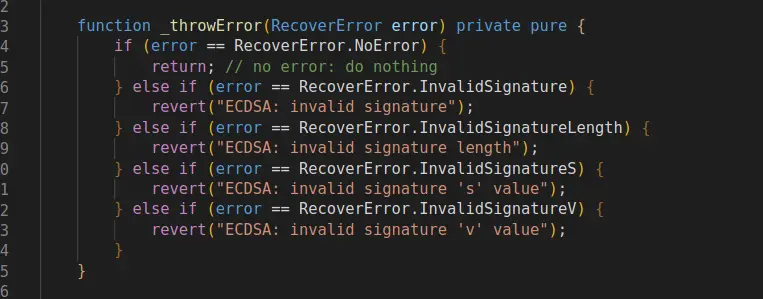
当我对mintNft函数进行错误性测试时(即第二个it,"incorrect mintNft shoule trigger error of SignatureNFTVerifyFailed"),我开始写的是.to.be.revertedWith("SignatureNFTVerifyFailed"),但出现了如下报错,于是我肯定ECDSA.recover这个函数中有先行报错,但我把其中四个revert报错都试过来了,还是会有but it reverted with a custom error这个提示,大家有兴趣可以找找这个先行报错在哪里,我就不找了,直接用.to.be.revertedWithCustomError()吧...
const { getNamedAccounts, ethers, network } = require("hardhat")
const { assert, expect } = require("chai")
describe("SignatureNFT", function () {
let signatureNFT, deployer
beforeEach(async function () {
// 我们将accounts[0]作为deployer和signer,account[1]、account[2]、account[3]作为白名单地址
accounts = await ethers.getSigners()
console.log(`accounts[0]:${accounts[0].address}`)
console.log(`accounts[1]:${accounts[1].address}`)
// 通过hardhat.config.js配置deployer就是accounts[0]
// 当然直接用accounts[0]也行,这里显得直观些
deployer = (await getNamedAccounts()).deployer
console.log(`deployer:${deployer}`)
// 部署合约
await deployments.fixture(["SignatureNFT"])
// 获得合约对象,若getContract没有account传入,则为deployer连接
signatureNFT = await ethers.getContract("SignatureNFT")
})
// test constructor
describe("constructor", function () {
it("i_signer is deploy_address when deploy constract", async function () {
const signer = await signatureNFT.i_signer()
assert.equal(signer, deployer)
})
})
//test recoverSigner
describe("recoverSigner", function () {
it("recoverSigner could return address of account[0](deployer) when contract deploy in default chain", async function () {
const signature =
"0x46bd542e1c97a9fd5541efbfa649dd8cecc0c7bb00c79bcac48f7986f45174893ce2063168c862996ebfa272cbc245cab3b93d0b49c8a5c5f3eec2d51ad5c6941c"
const tokenId = 3
const account = accounts[3]
const signer = await signatureNFT.recoverSigner(account.address, tokenId, signature)
assert.equal(signer, deployer)
})
})
//test varify
describe("varify", function () {
it("function varify should return ture", async function () {
const signature =
"0x46bd542e1c97a9fd5541efbfa649dd8cecc0c7bb00c79bcac48f7986f45174893ce2063168c862996ebfa272cbc245cab3b93d0b49c8a5c5f3eec2d51ad5c6941c"
const tokenId = 3
const account = accounts[3]
const verify = await signatureNFT.verify(account.address, tokenId, signature)
assert.equal(verify, true)
})
})
// correct mintNft
describe("mintNft", function () {
it("the third tokenId should belong to account[3] when mint the third signature", async function () {
const signature =
"0x46bd542e1c97a9fd5541efbfa649dd8cecc0c7bb00c79bcac48f7986f45174893ce2063168c862996ebfa272cbc245cab3b93d0b49c8a5c5f3eec2d51ad5c6941c"
const tokenId = 3
const account = accounts[3]
const verify = await signatureNFT.mintNft(account.address, tokenId, signature)
const owner = await signatureNFT.ownerOf(3)
assert.equal(owner, account.address)
})
// incorrect mintNft shoule trigger error of SignatureNFT__VerifyFailed
it("incorrect mintNft shoule trigger error of SignatureNFT__VerifyFailed", async function () {
const signature =
"0x46bd542e1c97a9fd5541efbfa649dd8cecc0c7bb00c79bcac48f7986f45174893ce2063168c862996ebfa272cbc245cab3b93d0b49c8a5c5f3eec2d51ad5c6941c"
// 我们规定accounts[3]只能Mint tokenId_3,他想Mint tokenId_2,那肯定不可以。
const tokenId = 2
const account = accounts[3]
// 这里有个注意点
await expect(
signatureNFT.mintNft(account.address, tokenId, signature)
).to.be.revertedWithCustomError(signatureNFT, "SignatureNFT__VerifyFailed")
})
})
})
综上
通用签名方法实现逻辑为:
- 签名逻辑:parameter... -> keccak256得到"消息Hash" -> 以太坊签名消息Hash -> 加入私钥进行运算得到"签名”。
- 消息HASH -> keccak256(abi.encodePacked(parameter...) 。
- 以太坊签名消息 -> keccak256(abi.encodePacked("\x19Ethereum Signed Message:\n32", hash)) 。
- 合约验证逻辑:ecrecover(_msgHash, v, r, s) 可以"消息"和"签名"中的vrs推出地址,然后我们在我们需要的程序中对其进行对比即可。
EIP-191
我们再一次看看这张图,第一个红框就是EIP-191的实现格式,以0x1900,0x1945开头的数据段可视为EIP191,它有什么作用?在https://eips.ethereum.org/EIPS/eip-191的Motivation中可以看出,EIP-191提出了在签名中加入合约自身的address参数,以防止重放攻击的手法。
我们这里不多阐述EIP-191,因为在生产中,人们似乎用更高端的EIP-712更多,EIP-712相当于继承了EIP-191,而且签名时还能小狐狸上显示签名内容,既高端又安全。那么这里我们就略过EIP-191,直接进行EIP-712,对EIP-191有兴趣的同学可以去看看https://eips.ethereum.org/EIPS/eip-191 最下方的例子。
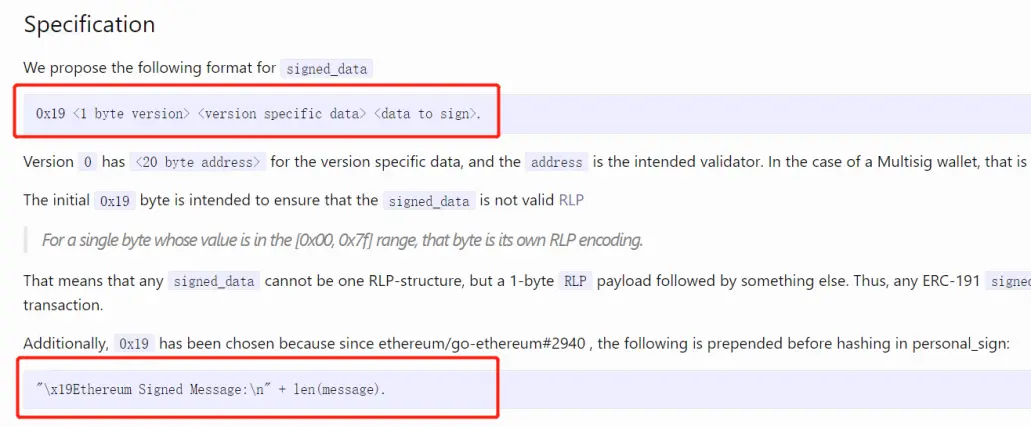
把Version byte写为0x01就是EIP-712啦。
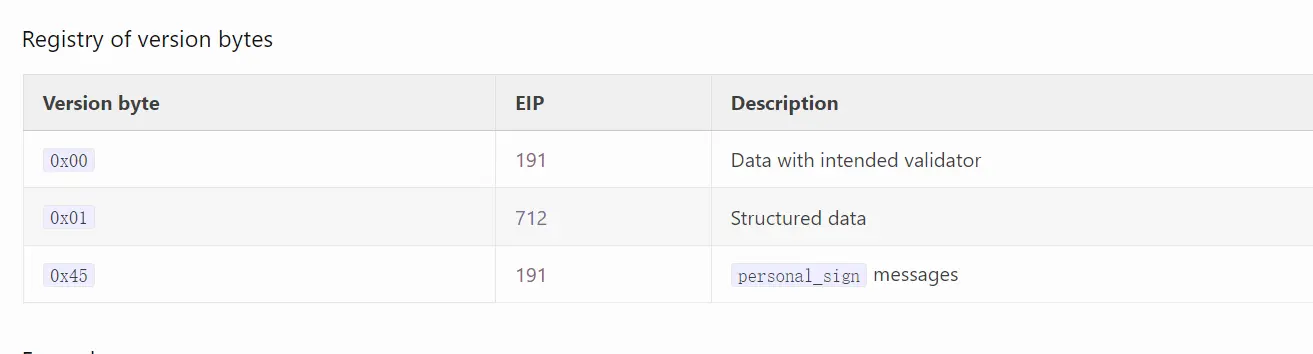
关于重放攻击
例子Motivation中用多签钱包举例,实际上任何两个实现逻辑相同的合约,都会存在重放攻击的风险,如我们举例NFT白名单,试想项目方想布置另一套NFT,只是修改了URI就进行部署了,那么毫无疑问上一个项目的白名单撸穿。
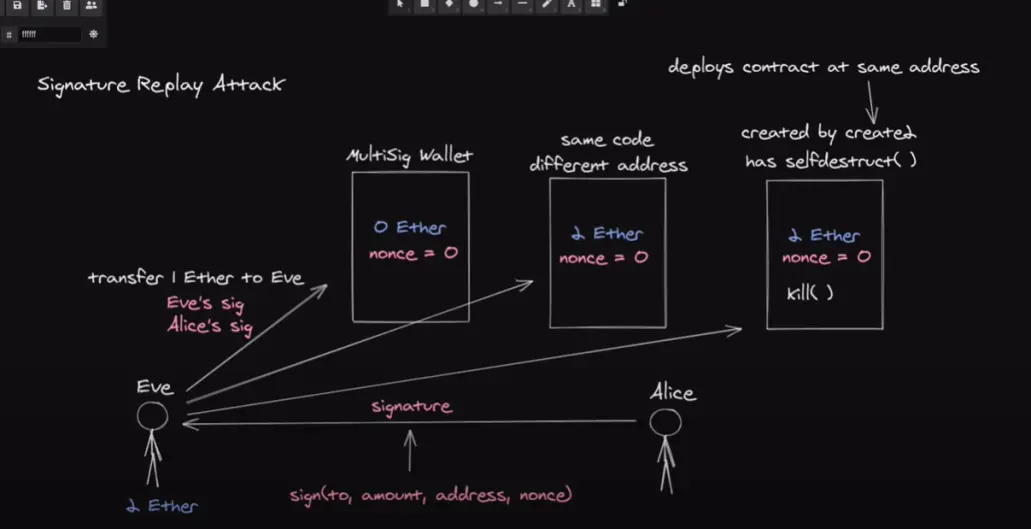
这是一个油管视频截图(https://www.youtube.com/watch?v=jq1b-ZDRVDc, 再看看这个https://solidity-by-example.org/hacks/signature-replay/) ,很好的解释了如何防范重放攻击:
- 没有任何防护的多签钱包,Eve重放Signature就会再次取出eth
- 在encodePacked的时候加入nonce参数,这就相当于每个Signature具备唯一性;
- 在合约逻辑上加入一个mapping,当一个Signature用过后就将其设置为true,表示已用过;
- 如果这个多签钱包的代码被被另一个项目方复用,正巧我在Eve和Alice也想在此放置资产,怎么防止重放?
- 在encodePacked的时候加入合约的address参数,这就相当于每个Signature对每个地址具备唯一性;
- 一个合约工厂用create2在可预测地址创建多签钱包,并且带有selfdestruct(),管理员没事还运行selfdestruct(),如何防范重放?(哪个奇葩会写出这样的合约)
- 防不了了,Alice在A地址的多签钱包存了10ETH,然后给Eve一个Signature,同意其取5个ETH,Eve正常取了5个之后想要重放攻击,因为有nonce并且Signature被记录,所以重放不了,但合约的owner在某种情况下selfdestruct()了合约,这是nonce恢复初始值,但Alice没注意到selfdestruct()事件,仍然向A地址的多签钱包存钱,这时Eve就可以重放Signature了,再拿走5ETH。
这里我再加一个:
- 加入chainId,防范在不同链的、逻辑相同的合约的重放攻击
EIP-712
在学习EIP-712时,不妨让我们先看一下其具体实现。以代码下是UniswapV2ERC20合约的实现,在20行bytes32 digest由三部分组成:
- '\x19\x01' ,固定字符串;
- DOMAIN_SEPARATOR,由constructor中定义;
- keccak256(abi.encode(PERMIT_TYPEHASH, owner, spender, value, nonces[owner]++, deadline)),其中PERMIT_TYPEHASH是constant变量
而EIP-712就是由以上三部分组成。
string public constant name = 'Uniswap V2';
// keccak256("Permit(address owner,address spender,uint256 value,uint256 nonce,uint256 deadline)");
bytes32 public constant PERMIT_TYPEHASH = 0x6e71edae12b1b97f4d1f60370fef10105fa2faae0126114a169c64845d6126c9;
constructor() public {
uint chainId;
assembly {
chainId := chainid
}
DOMAIN_SEPARATOR = keccak256(
abi.encode(
keccak256('EIP712Domain(string name,string version,uint256 chainId,address verifyingContract)'),
keccak256(bytes(name)),
keccak256(bytes('1')),
chainId,
address(this)
)
);
}
function permit(address owner, address spender, uint value, uint deadline, uint8 v, bytes32 r, bytes32 s) external {
require(deadline >= block.timestamp, 'UniswapV2: EXPIRED');
bytes32 digest = keccak256(
abi.encodePacked(
'\x19\x01',
DOMAIN_SEPARATOR,
keccak256(abi.encode(PERMIT_TYPEHASH, owner, spender, value, nonces[owner]++, deadline))
)
);
address recoveredAddress = ecrecover(digest, v, r, s);
require(recoveredAddress != address(0) && recoveredAddress == owner, 'UniswapV2: INVALID_SIGNATURE');
_approve(owner, spender, value);
}
"面子"上的区别
在https://eips.ethereum.org/EIPS/eip-712 中,我们可以看出,EIP-712与通用签名消息方法、EIP-191的"面子"上的区别为在钱包签名时显示的不同,遵循EIP-712方法可使签名内容可视化,这会提高我们签名时的安全性,试想,你的主机被黑客控制,准备签名的Message被替代,凭借肉眼,你肯定看不出签名的内容有何不同。
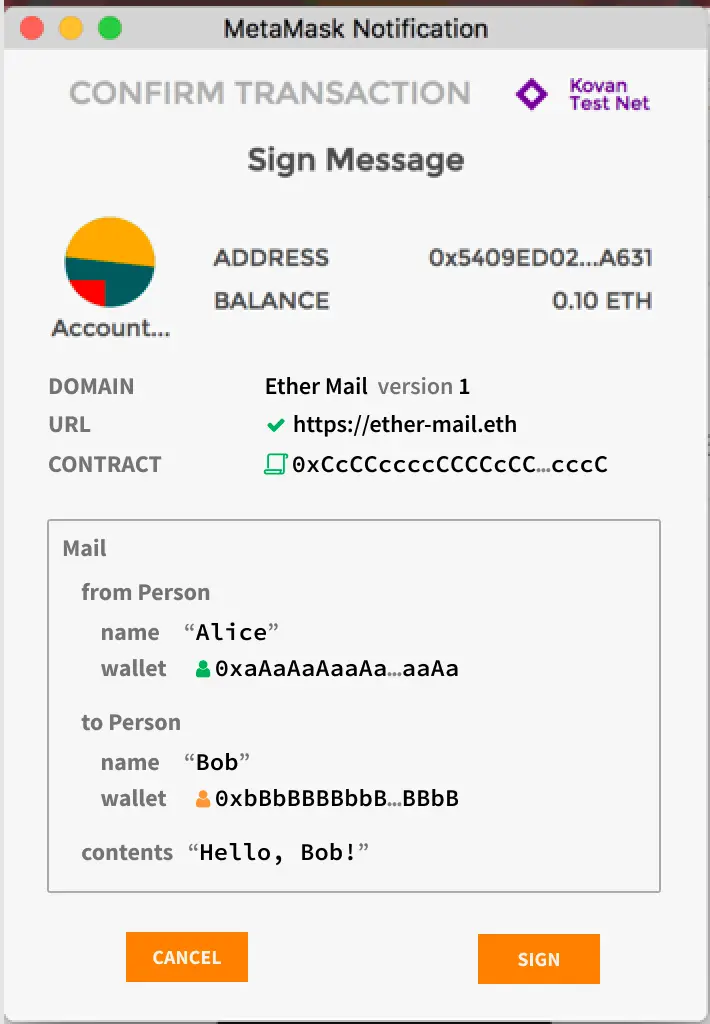
"里子"上的区别
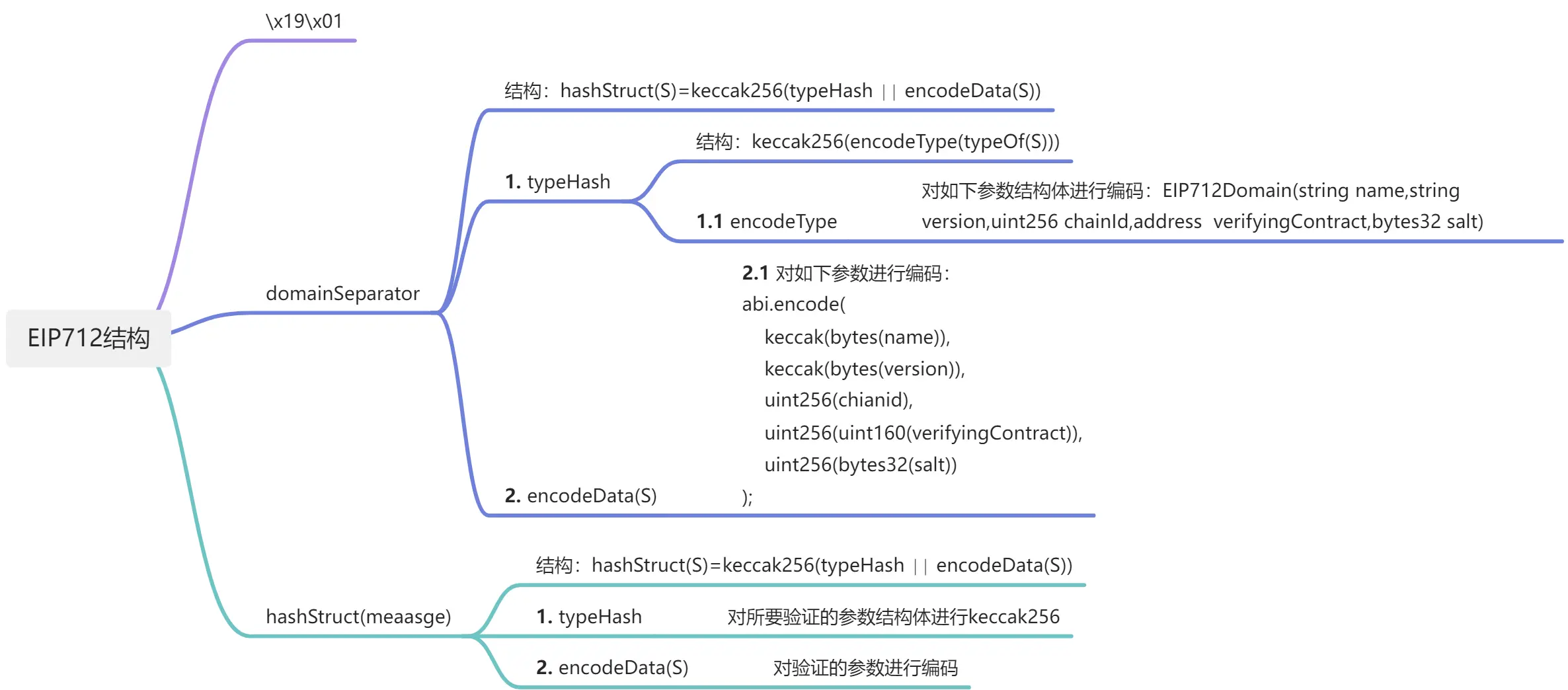
EIP-712 结构式
encode(domainSeparator,message)=x19x01∣∣domainSeparator∣∣hashStruct(message)
EIP-712 结构解析
对比我们上述"通用消息签名方法"中只是对要签名的参数进行序列化、keccak256、添加"\x19Ethereum Signed Message:\n32"后再次序列化与keccak256、签名相比,EIP-712是有着结构化上的要求的,我这里针对其结构式进行一个思维导图上的解析,大家如果想看文字上的描述,可以研读如下资料:
下面让我们对照UniswapV2ERC20和思维导图看看domainSeparator和hashStruct(meaasge)具体实现。
签名域-domainSeparator
domainSeparator由两部分组成,第一部分为对结构体的keccak256(encodeType),第二部分为结构体的具体实现(encodeData);
domainSeparator结构体如下所示,一般来说salt(随机数)会省略;
struct EIP712Domain{
string name, //用户可读的域名,如DAPP的名字
string version, // 目前签名的域的版本号
uint256 chainId, // EIP-155中定义的chain ID, 如以太坊主网为1
address verifyingContract, // 用于验证签名的合约地址
bytes32 salt // 随机数
}
- 再让我们对照UniswapV2ERC20来记几个结论:
- encodeType与encodeData都要按照如上的结构体顺序来实现,其中字段可以省略,但不可以颠倒顺序,如UniswapV2ERC20所示,省略了salt字段,但是按照name、version、chainId、verifyingContract来排序的;
- 针对string 或者 bytes 等动态类型,即长度不定的类型,其取值为 keccak256(string) 、 keccak256(bytes) 即内容的hash值;
- 我们可以看到这里用的是abi.encode而非abi.encodePacked,这是因为domainSeparator结构体要求每个字段占据256位,以便于前端分割。
DOMAIN_SEPARATOR = keccak256(
abi.encode(
// encodeType
keccak256('EIP712Domain(string name,string version,uint256 chainId,address verifyingContract)'),
// encodeData
keccak256(bytes(name)),
keccak256(bytes('1')),
chainId,
address(this)
)
);
签名对象-hashStruct(message)
- 一般来讲,hashStruct(message)与domainSeparator格式相同,也是由由两部分组成,第一部分为对自定义结构体的keccak256(encodeType),第二部分为自定义结构体的具体实现(encodeData);
- 由注释可知,PERMIT_TYPEHASH就是Permit(address owner,address spender,uint256 value,uint256 nonce,uint256 deadline)的hash,注意自定义对象名要首字母大写;
- encodeData与encodeType顺序要相同;
// keccak256("Permit(address owner,address spender,uint256 value,uint256 nonce,uint256 deadline)");
bytes32 public constant PERMIT_TYPEHASH = 0x6e71edae12b1b97f4d1f60370fef10105fa2faae0126114a169c64845d6126c9;
bytes32 digest = keccak256(
abi.encodePacked(
'\x19\x01',
DOMAIN_SEPARATOR,
keccak256(abi.encode(PERMIT_TYPEHASH, owner, spender, value, nonces[owner]++, deadline))
)
);
然后就是熟悉的套路,ecrecover出address,进行比较,最后授权。
address recoveredAddress = ecrecover(digest, v, r, s);
require(recoveredAddress != address(0) && recoveredAddress == owner, 'UniswapV2: INVALID_SIGNATURE');
_approve(owner, spender, value);
### 签名脚本
用uniswapV2结构体进行举例,注意我们要先确定verifyingContract,即pair的地址。
```javascript
const { ethers } = require("hardhat")
async function signTypedData(signer) {
const domain = {
name: "Uniswap V2",
version: "1",
chainId: 1,
verifyingContract: "0xCcCCccccCCCCcCCCCCCcCcCccCcCCCcCcccccccC",
}
// The named list of all type definitions
const types = {
Permit: [
{ name: "owner", type: "address" },
{ name: "spender", type: "address" },
{ name: "value", type: "uint256" },
{ name: "nonce", type: "uint256" },
{ name: "deadline", type: "uint256" },
],
}
// The data to sign
const value = {
owner: xx,
spender: xx,
value: xx,
nonce: xx,
deadline: xx,
}
const signature = await signer._signTypedData(domain, types, value)
return signature
}
async function main() {
signers = await ethers.getSigners()
signature = await signTypedData(signers[0])
console.log(signature)
}
main()
.then(() => process.exit(0))
.catch((error) => {
console.error(error)
process.exit(1)
})
uniswap为什么要应用EIP712?
实质上还是和NFT白名单的目的一样——为了节省GAS,uniswapV2分为pair合约UniswapV2Pair.sol和路由合约UniswapV2Router02.sol。当我们要移除流动性时需要通过路由合约来操作pair合约,试想如果没有应用消息签名,其操作路径为先在pair合约进行授权,然后在路由合约中移除流动性,也就是两笔交易。而应用消息签名只需要一笔交易即可完成。可想而知,面对Uniswap这种海量交易的情况下,也节省海量的GAS,也节省了海量的链上资源。
后记:
- 以上为签名相关的知识点讲解,内容肯定有疏忽或者理解不到位的情况,欢迎各位大佬交流指正。
- 封面出自Jose Aguinaga文章,如涉及侵权,请站内私信,我会及时整改。
- 如需转载本文,请注明出处。
- ethsamgs 2022.11.8
参考&致谢
- 整体知识
- 通用消息签名方法-NFT白名单
- EIP-712
转载:https://learnblockchain.cn/article/5012











{kind=link}
{kind=link}