在2018年,我们(CheckMarx)曾对智能合约安全状况进行过初步研究,重点是Solidity编写的智能合约。 当时,我们根据公开的合约源代码(译者注:本文称之为已扫描合约,本文出现的 x% 是以此为基数)编写了最常见的10 个智能合约安全问题。 两年过去了该更新研究并评估智能合约安全性发展的如何了。
0. 值得关注的其他问题
尽管有一个安全问题排名很不错,但它往往一些有趣的细节,因为某些细节与排名列表并不完全一致。 在深入挖掘 10 大问题之前,必要阐述一下原始研究中一些值得关注的亮点问题:
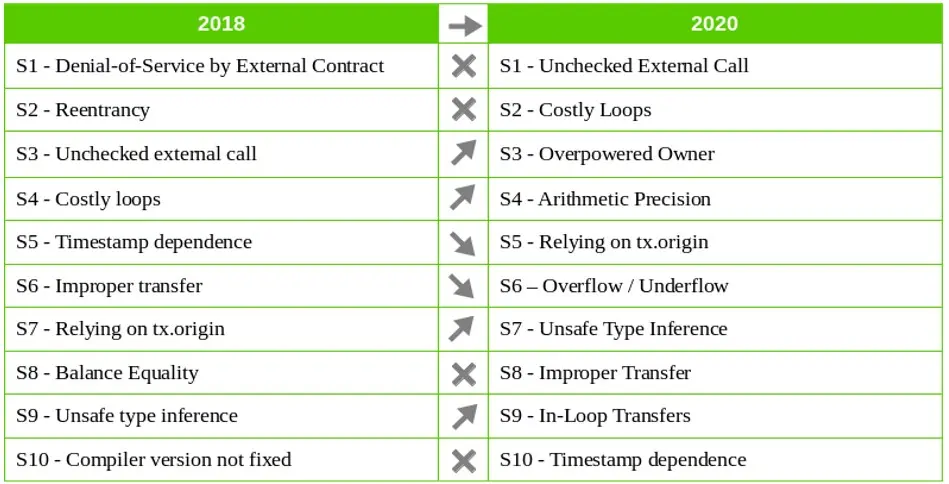
- 在2018年,最主要的两个问题是 外部合约拒绝服务和重入。 但是现在这些问题有所缓解(不过依旧值得关注)。 可以从我们的研究博客中了解更多有关Reentrancy的信息:从安全角度出发审视智能合约。
译者注: 实际上由于 DeFi 应用之间的组合应用(例如闪电贷),又导致了多起严重的重入攻击事件。 - 现在 Solidity v0.6.x 发布了,它带来了许多重大变化,然而扫描的智能合约中有50%甚至还没有准备好使用Solidity v0.5.0编译器。 另外 30% 智能合约使用了过时的语法(例如:使用 sha3、throw 、constant等),并且 83%的合约在指定编译器版本存在规范问题(pragma)。
- 尽管可见性问题没有出现在2018年的前10位,也没有出现今年的前 10,但可见性问题增加了48%,值得关注。
下表比较了2018年和2020年十大常见问题列表之间的变化。 这些问题按严重程度和流行程度排序:
1. 未检查的外部调用
在 2018 年 Solidity十大安全问题榜单上未检查的外部调用是第三个常见问题。由于现在前两个解决了, 因此未检查的外部调用成为了2020年更新列表中最常见的问题。
Solidity 底层调用方法,(例如 address.call()) 不会抛出异常。而是在遇到错误,返回false。
而如果使用合约调用ExternalContract.doSomething()时,如果 doSomething()抛出异常,则异常会继续“冒泡”传播。
应该通过检查返回值来显式处理不成功的情况,以下使用addr.send()进行以太币转账是一个很好的例子,这对于其他外部调用也有效。
if(!addr.send(1)) {
revert()
}2. 高成本循环
高成本循环从Solidity安全榜单的第四名上升至第二名。受该问题影响的智能合约数量增长了近30%。
大家都知道,以太坊上的运算是需要付费的。因此,减少完成操作所需的计算,不仅仅是优化问题(效率),还涉及到成本费用。
循环是一个昂贵的操作,这里有一个很好的例子:数组中包含的元素越多,就需要更多迭代才能完成循环。最终,无限循环会耗尽所有可用GAS。
for(uint256 i=0; i< elements.length; i++) {
// do something
}如果攻击者能够影响元素数组的长度,则上述代码将导致拒绝服务(执行无法跳出循环)。 而在扫描的智能合约中发现有8%的合约存在数组长度操纵问题。
3. 权力过大的所有者
这是Soldiity十大安全问题新出现的问题,该问题影响了约16%的合约,某些合约与其所有者(Owner)紧密相关,某些函数只能由所有者地址调用, 如下例所示:

只有合约所有者能够调用doSomething()和doSomethingElse()函数:前者使用onlyOwner修饰器, 而后者则显式执行该修饰器。这带来了严重的风险:如果所有者的私钥遭到泄露, 则攻击者可以控制该合约。
4. 算术精度问题
由于使用256位虚拟机(EVM),Solidity的数据类型有些复杂。 Solidity 不提供浮点运算, 并且少于32个字节的数据类型将被打包到同一个32字节的槽位中。考虑到这一点,你应该预见以下程序精度问题:
function calculateBonus(uint amount) returns (uint) {
return amount/DELIMITER * BONUS;
}如上例所示,在乘法之前执行的除法,可能会有巨大的舍入误差。
5. 依赖 tx.origin
智能合约不应依赖于tx.origin进行身份验证,因为恶意合约可能会进行中间人攻击,耗尽所有资金。 建议改用msg.sender:
function transferTo(address dest, uint amount) {
require(tx.origin == owner) {
dest.transfer(amount);
}
}可以在Solidity的文档中找到 Tx Origin攻击的详细说明 。简单的说,tx.origin始终是合约调用链中的最初的发起者帐户,而msg.sender则表示直接调用者。如果链中的最后一个 合约依赖于tx.origin进行身份验证,那么调用链中间环节的合约将能够榨干被调用合约的资金,因为身份验证没有检查究竟是谁(msg.sender)进行了调用。
6. 溢出(Overflow / Underflow)
Solidity的256位虚拟机存在上溢出和下溢出问题(译者注:由于结果超出取值范围称为溢出), 这里有具体的分析。 在for循环条件中使用uint数据类型时,开发人员要格外小心,因为它可能导致无限循环:
for (uint i = border; i >= 0; i--) {
ans += i;
}在上面的示例中,当i的值为0时,下一个值为2^256 -1,这使条件始终为true。 开发人员应当尽量使用<、>、!=和==进行比较。
7. 不安全的类型推导
该问题在Solidity十大安全问题排行榜中上升了两位,现在影响到的智能合约比之前多了 17%以上。
Solidity 支持类型推导,但有一些奇怪的表现。例如,字面量0会被推断为byte类型, 而不是通常期望的整型。
在下面的示例中,i的类型被推断为uint8,因为这时能够存储i的值 uint8 就足够。但如果elements数组包含256个以上的元素,则下面的代码就会发生溢出:
for (var i = 0; i < elements.length; i++) {
// to something
}建议明确声明数据类型,以避免意外的行为和/或错误。
译者注: 在 Solidity 0.6 已经移除了var 定义变量( Solidity 0.6之后不再有类型推导了),如果使用新的编译器,将不是问题。
8. 不正确的转账
此问题在Solidity十大安全问题榜单中从第六位下降到第八位,目前影响不到1%的智能合约。
在合约之间进行以太币转账有多种方法。虽然官方推荐使用addr.transfer(x)函数,但我们仍然找到了还在使用send()函数的智能合约:
if(!addr.send(1)) {
revert()
}请注意,如果转账不成功,则addr.transfer(x)会自动引发异常,同样减轻第一个未检查外部调用的问题
9. 循环内转帐
当在循环体中进行以太币转账时,如果其中一个转账失败(例如,一个合约不能接收),那么整个交易将被回滚。
for (uint i = 0; i < users.lenghth; i++) {
users[i].transfer(amount);
}在这个例子中,攻击者可能利用此行为来进行拒绝服务攻击,从而阻止其他用户接收以太币。
10. 时间戳依赖
在2018年,时间戳依赖问题排名第五,重要的是要记住,智能合约在不同时刻多个节点上运行的。以太坊虚拟机(EVM)不提供时钟时间,并且通常用于获取时间戳的now变量(block.timestamp的别名)实际上是矿工可以操纵的环境变量。
if (timeHasCome == block.timestamp) {
winner.transfer(amount);
}由于矿工可以操纵当前的环境变量,因此只能在不等式>、<、>=和<=中使用其值。
如果你的应用需要随机性,可以参考RANDAO合约, 该合约基于任何人都可以参与的去中心化自治组织(DAO),是所有参与者共同生成的随机数。
总结
比较2018年和2020年十大常见问题时,我们可以观察到开发最佳实践的一些进展,尤其是那些影响安全性的实践。 看到2018年排名前2位的问题:外部合约拒绝服务和重入,已经不再榜单了,这是一个积极的信号,但仍然需要采取措施来避免这类常见错误。
请记住,智能合约在设计上是不可变的,这意味着一旦创建,就无法修补源代码。 这对安全性构成了巨大挑战,开发人员应利用可用的安全测试工具来确保在部署之前对源代码进行了充分的测试和审核。
链接:https://securityboulevard.com/2020/05/solidity-top-10-common-issues/
转载:https://learnblockchain.cn/article/1218