eos源码分析之三交易
一、交易的介绍
说明:最新的1.0及以上代码中已经移除了相关的cycle和shared部分
基本上区块链都是这几板斧,又轮到交易了。一般交易都是最复杂的部分,因为它涉及到网络,帐户,数据库,共识,内存池等等好多部分。EOS的交易数据结构主要有两种:
1、signed_transaction:用户发起的交易
2、deferred_transaction:延期交易,注释的说明这种交易可以返回错误给当事人。
EOS为了应对海量的交易,引入分片(shard)技术,即在区块中维护了一条私有区块链,将一个block分割成多个cycle(循环),每个cycle的生成时间很短,而且不用等待完整的block确认完成(3秒),生成后直接异步广播发送,这样,交易在很快就被确认了。在一个cycle中,如果存在有大量互不想干的交易,但么多核多线程技术将极大的提高交易的处理速度 。
这次仍然从客户端发起一笔交易开始来查看整个代码的流程,基本上是cleos发出Transaction到nodeos的HTTP接口,接口接收到消息,分析打包。
二、交易的具体过程
1、客户端发起交易:
无论是send_actions 还是 send_transaction最终都落到push_transaction
fc::variant push_transaction( signed_transaction& trx, int32_t extra_kcpu = 1000, packed_transaction::compression_type compression = packed_transaction::none ) {
auto info = get_info();
trx.expiration = info.head_block_time + tx_expiration;
trx.set_reference_block(info.head_block_id);
if (tx_force_unique) {
trx.context_free_actions.emplace_back( generate_nonce() );
}
auto required_keys = determine_required_keys(trx);
size_t num_keys = required_keys.is_array() ? required_keys.get_array().size() : 1;
trx.max_kcpu_usage = (tx_max_cpu_usage + 1023)/1024;
trx.max_net_usage_words = (tx_max_net_usage + 7)/8;
if (!tx_skip_sign) {
//生成交易
sign_transaction(trx, required_keys);
}
if (!tx_dont_broadcast) {
//调用HTTP接口,packed_transaction打包交易
return call(push_txn_func, packed_transaction(trx, compression));
} else {
return fc::variant(trx);
}
}
void sign_transaction(signed_transaction& trx, fc::variant& required_keys) {
// TODO determine chain id
fc::variants sign_args = {fc::variant(trx), required_keys, fc::variant(chain_id_type{})};
const auto& signed_trx = call(wallet_host, wallet_port, wallet_sign_trx, sign_args);
trx = signed_trx.as<signed_transaction>();
}
看到调用call,那么进去:
template<typename T>
fc::variant call( const std::string& server, uint16_t port,
const std::string& path,
const T& v ) { return eosio::client::http::call( server, port, path, fc::variant(v) ); }
template<typename T>
fc::variant call( const std::string& path,
const T& v ) { return eosio::client::http::call( host, port, path, fc::variant(v) ); }
//最终调用
fc::variant call( const std::string& server, uint16_t port,
const std::string& path,
const fc::variant& postdata ) {
try {
......
while( endpoint_iterator != end ) {
// Try each endpoint until we successfully establish a connection.
tcp::socket socket(io_service);
try {
boost::asio::connect(socket, endpoint_iterator);
endpoint_iterator = end;
}
......
// Form the request. We specify the "Connection: close" header so that the
// server will close the socket after transmitting the response. This will
// allow us to treat all data up until the EOF as the content.
//组建请求的流
boost::asio::streambuf request;
std::ostream request_stream(&request);
request_stream << "POST " << path << " HTTP/1.0\r\n";
request_stream << "Host: " << server << "\r\n";
request_stream << "content-length: " << postjson.size() << "\r\n";
request_stream << "Accept: */*\r\n";
request_stream << "Connection: close\r\n\r\n";
request_stream << postjson;
// Send the request.发送组织好的Request
boost::asio::write(socket, request);
// Read the response status line. The response streambuf will automatically
// grow to accommodate the entire line. The growth may be limited by passing
// a maximum size to the streambuf constructor.
//读取并处理Response
boost::asio::streambuf response;
boost::asio::read_until(socket, response, "\r\n");
// Check that response is OK.判断格式
std::istream response_stream(&response);
std::string http_version;
response_stream >> http_version;
unsigned int status_code;
response_stream >> status_code;
std::string status_message;
std::getline(response_stream, status_message);
FC_ASSERT( !(!response_stream || http_version.substr(0, 5) != "HTTP/"), "Invalid Response" );
// Read the response headers, which are terminated by a blank line.
boost::asio::read_until(socket, response, "\r\n\r\n");
// Process the response headers.读取头
std::string header;
while (std::getline(response_stream, header) && header != "\r")
{
// std::cout << header << "\n";
}
// std::cout << "\n";
std::stringstream re;
// Write whatever content we already have to output.
if (response.size() > 0)
// std::cout << &response;
re << &response;
// Read until EOF, writing data to output as we go.读取数据
boost::system::error_code error;
while (boost::asio::read(socket, response,
boost::asio::transfer_at_least(1), error))
re << &response;
......
}
FC_ASSERT( !"unable to connect" );
} FC_CAPTURE_AND_RETHROW() // error, "Request Path: ${server}:${port}${path}\nRequest Post Data: ${postdata}" ,
// ("server", server)("port", port)("path", path)("postdata", postdata) )
}
在HTTP的名空间里定义了一大堆的API接口,这里用的是:
const string chain_func_base = "/v1/chain";
const string push_txns_func = chain_func_base + "/push_transactions";(httpc.hpp中)
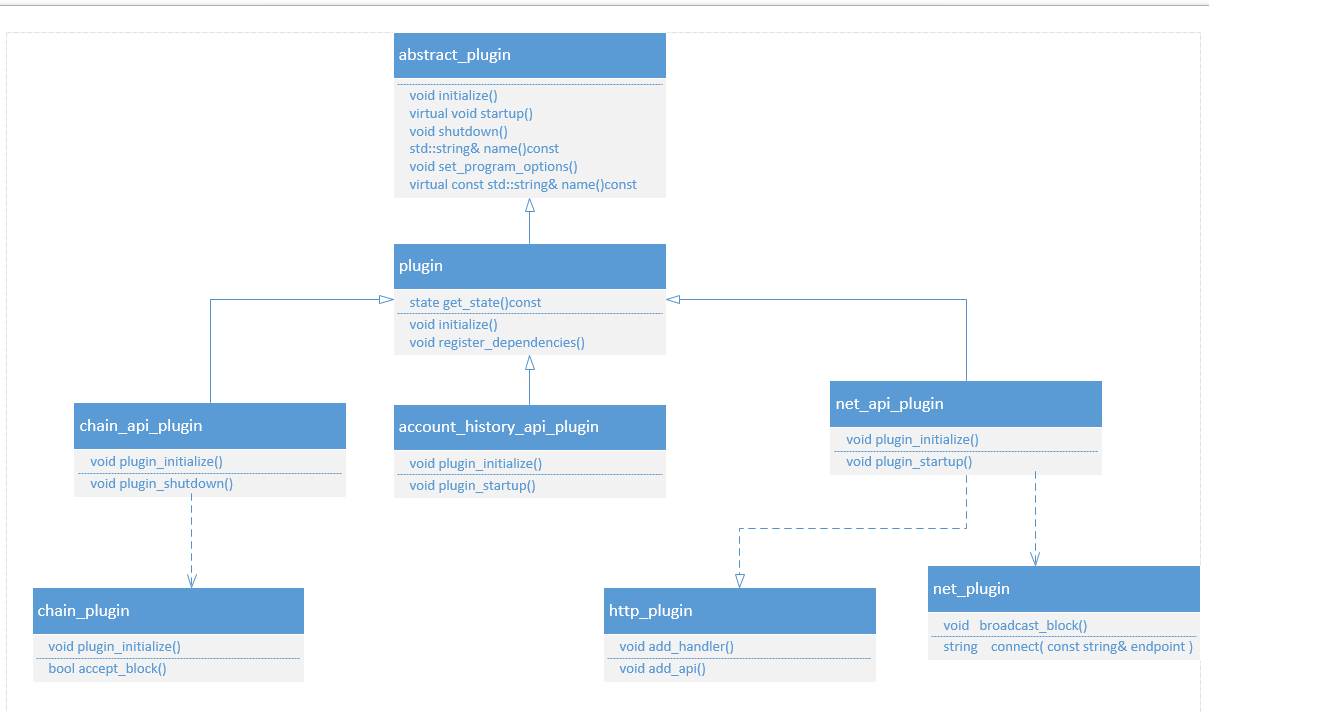
这里基本就相当于调用HTTP的接口了,也就是说cleos把相关的API调用及内容发到了服务端,也就是nodeos端。那就去服务端看看nodeos接收到请求后干了些什么,有什么具体的动作。上面使用的路径是chain, 所以到chain_api_plugin.cpp中去看。
在前面的整体NODEOS启动时,会有插件启动这个函数执行:
//最终调用下面这个宏,这个宏展开稍微有一些复杂,其实就是名字替换和参数转换 类似struct get_account_params {name account_name;};
#define CALL(api_name, api_handle, api_namespace, call_name, http_response_code) \
{std::string("/v1/" #api_name "/" #call_name), \
[this, api_handle](string, string body, url_response_callback cb) mutable { \
try { \
if (body.empty()) body = "{}"; \
auto result = api_handle.call_name(fc::json::from_string(body).as<api_namespace::call_name ## \_params>()); \
cb(http_response_code, fc::json::to_string(result)); \
} \
......//去除异常
}}
//用下面两个宏来展开增加的API
#define CHAIN_RO_CALL(call_name, http_response_code) CALL(chain, ro_api, chain_apis::read_only, call_name, http_response_code)
#define CHAIN_RW_CALL(call_name, http_response_code) CALL(chain, rw_api, chain_apis::read_write, call_name, http_response_code)
void chain_api_plugin::plugin_startup() {
ilog( "starting chain_api_plugin" );
my.reset(new chain_api_plugin_impl(app().get_plugin<chain_plugin>().chain()));
auto ro_api = app().get_plugin<chain_plugin>().get_read_only_api();
auto rw_api = app().get_plugin<chain_plugin>().get_read_write_api();
//注册相关API
app().get_plugin<http_plugin>().add_api({
CHAIN_RO_CALL(get_info, 200),
CHAIN_RO_CALL(get_block, 200),
CHAIN_RO_CALL(get_account, 200),
CHAIN_RO_CALL(get_code, 200),
CHAIN_RO_CALL(get_table_rows, 200),
CHAIN_RO_CALL(get_currency_balance, 200),
CHAIN_RO_CALL(get_currency_stats, 200),
CHAIN_RO_CALL(abi_json_to_bin, 200),
CHAIN_RO_CALL(abi_bin_to_json, 200),
CHAIN_RO_CALL(get_required_keys, 200),
CHAIN_RW_CALL(push_block, 202),
CHAIN_RW_CALL(push_transaction, 202),
CHAIN_RW_CALL(push_transactions, 202)
});
}
上面的api_handle.call_name展开后是:read_write::push_transaction_results read_write::push_transaction(),在chain_plugin.cpp文件中。
read_write::push_transaction_results read_write::push_transaction(const read_write::push_transaction_params& params) {
packed_transaction pretty_input;
auto resolver = make_resolver(this);
try {
abi_serializer::from_variant(params, pretty_input, resolver);
} EOS_RETHROW_EXCEPTIONS(chain::packed_transaction_type_exception, "Invalid packed transaction")
auto result = db.push_transaction(pretty_input, skip_flags);//这行是根本,db定义为chain_controller
#warning TODO: get transaction results asynchronously
fc::variant pretty_output;
abi_serializer::to_variant(result, pretty_output, resolver);
return read_write::push_transaction_results{ result.id, pretty_output };
}
因为这个函数其实是调用的chain_controller的同名函数:
/**
* Attempts to push the transaction into the pending queue
*
* When called to push a locally generated transaction, set the skip_block_size_check bit on the skip argument. This
* will allow the transaction to be pushed even if it causes the pending block size to exceed the maximum block size.
* Although the transaction will probably not propagate further now, as the peers are likely to have their pending
* queues full as well, it will be kept in the queue to be propagated later when a new block flushes out the pending
* queues.
*/
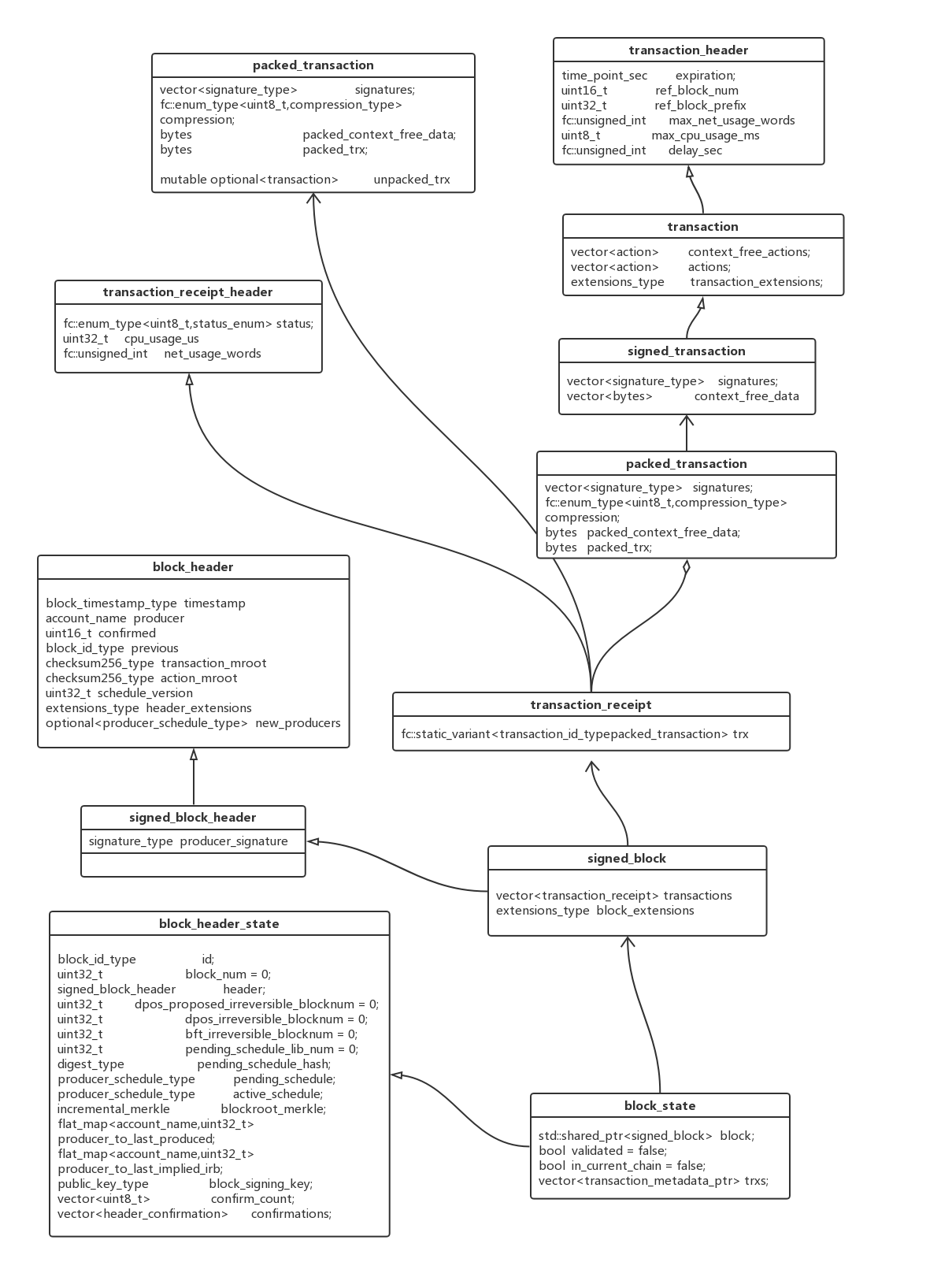
transaction_trace chain_controller::push_transaction(const packed_transaction& trx, uint32_t skip)
{ try {
// If this is the first transaction pushed after applying a block, start a new undo session.
// This allows us to quickly rewind to the clean state of the head block, in case a new block arrives.
if( !\_pending_block ) {
_start_pending_block();
}
return with_skip_flags(skip, [&]() {
return \_db.with_write_lock([&]() {
return _push_transaction(trx);
});
});
} EOS_CAPTURE_AND_RETHROW( transaction_exception ) }
看注释说得很清楚了,
如果是交易写入块后的第一个交易,是启动一个可撤销的Session,保证在新块到来时可以进行回滚:
void chain_controller::_start_pending_block( bool skip_deferred )
{
//配置等待块
FC_ASSERT( !\_pending_block );
\_pending_block = signed_block();
\_pending_block_trace = block_trace(\*\_pending_block);
\_pending_block_session = \_db.start_undo_session(true);
\_pending_block->regions.resize(1);
\_pending_block_trace->region_traces.resize(1);
_start_pending_cycle();//处理里块的cycle
_apply_on_block_transaction();
_finalize_pending_cycle();
_start_pending_cycle();
if ( !skip_deferred ) {
_push_deferred_transactions( false );
if (\_pending_cycle_trace && \_pending_cycle_trace->shard_traces.size() > 0 && \_pending_cycle_trace->shard_traces.back().transaction_traces.size() > 0) {
_finalize_pending_cycle();
_start_pending_cycle();
}
}
}
//下面的两个函数比较关键,一个是处理cycle,一个是添加交易,下面的英文注释说得也比较清楚
/**
* Wraps up all work for current shards, starts a new cycle, and
* executes any pending transactions
*/
void chain_controller::_start_pending_cycle() {
// only add a new cycle if there are no cycles or if the previous cycle isn't empty
if (\_pending_block->regions.back().cycles_summary.empty() ||
(!\_pending_block->regions.back().cycles_summary.back().empty() &&
!\_pending_block->regions.back().cycles_summary.back().back().empty()))
\_pending_block->regions.back().cycles_summary.resize( \_pending_block->regions[0].cycles_summary.size() + 1 );
\_pending_cycle_trace = cycle_trace();
\_pending_cycle_trace->shard_traces.resize(\_pending_cycle_trace->shard_traces.size() + 1 );//当前分片
auto& bcycle = \_pending_block->regions.back().cycles_summary.back();
if(bcycle.empty() || !bcycle.back().empty())
bcycle.resize( bcycle.size()+1 );
}
void chain_controller::_apply_on_block_transaction()
{
\_pending_block_trace->implicit_transactions.emplace_back(_get_on_block_transaction());
transaction_metadata mtrx(packed_transaction(\_pending_block_trace->implicit_transactions.back()), get_chain_id(), head_block_time(), optional<time_point>(), true /*is implicit*/);
_push_transaction(std::move(mtrx));
}
//再处理一下deferred
vector<transaction_trace> chain_controller::_push_deferred_transactions( bool flush )
{
FC_ASSERT( \_pending_block, " block not started" );
if (flush && \_pending_cycle_trace && \_pending_cycle_trace->shard_traces.size() > 0) {
// TODO: when we go multithreaded this will need a better way to see if there are flushable
// deferred transactions in the shards
auto maybe_start_new_cycle = [&]() {
for (const auto &st: \_pending_cycle_trace->shard_traces) {
for (const auto &tr: st.transaction_traces) {
for (const auto &req: tr.deferred_transaction_requests) {
if ( req.contains<deferred_transaction>() ) {
const auto& dt = req.get<deferred_transaction>();
if ( fc::time_point(dt.execute_after) <= head_block_time() ) {
// force a new cycle and break out
_finalize_pending_cycle();
_start_pending_cycle();
return;
}
}
}
}
}
};
maybe_start_new_cycle();
}
}
这里得重点看看下面这个函数:
void chain_controller::_finalize_pending_cycle()
{
// prune empty shard
if (!\_pending_block->regions.back().cycles_summary.empty() &&
!\_pending_block->regions.back().cycles_summary.back().empty() &&
\_pending_block->regions.back().cycles_summary.back().back().empty()) {
\_pending_block->regions.back().cycles_summary.back().resize( \_pending_block->regions.back().cycles_summary.back().size() - 1 );
\_pending_cycle_trace->shard_traces.resize(\_pending_cycle_trace->shard_traces.size() - 1 );
}
// prune empty cycle
if (!\_pending_block->regions.back().cycles_summary.empty() &&
\_pending_block->regions.back().cycles_summary.back().empty()) {
\_pending_block->regions.back().cycles_summary.resize( \_pending_block->regions.back().cycles_summary.size() - 1 );
\_pending_cycle_trace.reset();
return;
}
for( int idx = 0; idx < \_pending_cycle_trace->shard_traces.size(); idx++ ) {
auto& trace = \_pending_cycle_trace->shard_traces.at(idx);
auto& shard = \_pending_block->regions.back().cycles_summary.back().at(idx);
trace.finalize_shard();
shard.read_locks.reserve(trace.read_locks.size());
shard.read_locks.insert(shard.read_locks.end(), trace.read_locks.begin(), trace.read_locks.end());
shard.write_locks.reserve(trace.write_locks.size());
shard.write_locks.insert(shard.write_locks.end(), trace.write_locks.begin(), trace.write_locks.end());
}
_apply_cycle_trace(*\_pending_cycle_trace);
\_pending_block_trace->region_traces.back().cycle_traces.emplace_back(std::move(*\_pending_cycle_trace));
\_pending_cycle_trace.reset();
}
这里遇到的问题是,没有找到Cycle的周期性增加,对块内的分片也因此不是非常清楚。
现在接着回到交易,看前面调用了_push_transaction, 它有两个重载,前面的重载会在函数内调用后面的重载函数,即:
transaction_trace chain_controller::_push_transaction(const packed_transaction& packed_trx)
{ try {
......
// 根据情况来分别打包普通交易和延迟交易
if( mtrx.delay.count() == 0 ) {
result = _push_transaction( std::move(mtrx) );
} else {
result = wrap_transaction_processing( std::move(mtrx),
[this](transaction_metadata& meta) { return delayed_transaction_processing(meta); } );
}
// notify anyone listening to pending transactions
//这个最终会调用connections的enqueue-queue_write-do_queue_write,然后发送广播消息
on_pending_transaction(\_pending_transaction_metas.back(), packed_trx);
\_pending_block->input_transactions.emplace_back(packed_trx);//插入到区块中
......
} FC_CAPTURE_AND_RETHROW( (transaction_header(packed_trx.get_transaction())) ) }
transaction_trace chain_controller::_push_transaction( transaction_metadata&& data )
{ try {
auto process_apply_transaction = [this](transaction_metadata& meta) {
......
/// TODO: move \_pending_cycle into db so that it can be undone if transation fails, for now we will apply
/// the transaction first so that there is nothing to undo... this only works because things are currently
/// single threaded
// set cycle, shard, region etc
meta.region_id = 0;
meta.cycle_index = cyclenum;
meta.shard_index = 0;
return _apply_transaction( meta );//交易打入块中
};
// wdump((transaction_header(data.trx())));
return wrap_transaction_processing( move(data), process_apply_transaction );
} FC_CAPTURE_AND_RETHROW( ) }
经过上面的处理之后,最后通过_apply_transaction把交易最终打入块中:
//写入并执行交易
transaction_trace chain_controller::__apply_transaction( transaction_metadata& meta )
{ try {
transaction_trace result(meta.id);
for (const auto &act : meta.trx().context_free_actions) {
apply_context context(\*this, \_db, act, meta);
context.context_free = true;
context.exec();//执行
fc::move_append(result.action_traces, std::move(context.results.applied_actions));
FC_ASSERT( result.deferred_transaction_requests.size() == 0 );
}
for (const auto &act : meta.trx().actions) {
apply_context context(\*this, \_db, act, meta);
context.exec();
context.results.applied_actions.back().auths_used = act.authorization.size() - context.unused_authorizations().size();
fc::move_append(result.action_traces, std::move(context.results.applied_actions));
fc::move_append(result.deferred_transaction_requests, std::move(context.results.deferred_transaction_requests));
}
update_resource_usage(result, meta);
update_permission_usage(meta);
record_transaction(meta.trx());//保存到数据库
return result;
} FC_CAPTURE_AND_RETHROW() }
transaction_trace chain_controller::_apply_transaction( transaction_metadata& meta ) { try {
auto execute = [this](transaction_metadata& meta) -> transaction_trace {
try {
auto temp_session = \_db.start_undo_session(true);
auto result = __apply_transaction(meta);
......
} catch (...) {
......
}
};
......
} FC_CAPTURE_AND_RETHROW( (transaction_header(meta.trx())) ) }
交易完成后,就需要打包到块并进行广播了.这里只简单说一下,在介绍区块和共识时再详细说明:
在producer_plugin插件中:
void producer_plugin::plugin_startup()
{ try {
ilog("producer plugin: plugin_startup() begin");
chain::chain_controller& chain = app().get_plugin<chain_plugin>().chain();
if (!my->_producers.empty())
{
......
my->schedule_production_loop();
} else
......
} FC_CAPTURE_AND_RETHROW() }
void producer_plugin_impl::schedule_production_loop() {
//Schedule for the next second's tick regardless of chain state
// If we would wait less than 50ms (1/10 of block_interval), wait for the whole block interval.
......
//\_timer.expires_from_now(boost::posix_time::microseconds(time_to_next_block_time));
\_timer.expires_from_now( boost::posix_time::microseconds(time_to_next_block_time) );
//\_timer.async_wait(boost::bind(&producer_plugin_impl::block_production_loop, this));
\_timer.async_wait( [&](const boost::system::error_code&){ block_production_loop(); } );
}
block_production_condition::block_production_condition_enum producer_plugin_impl::block_production_loop() {
block_production_condition::block_production_condition_enum result;
fc::mutable_variant_object capture;
try
{
result = maybe_produce_block(capture);//生产块
}
catch( const fc::canceled_exception& )
{
......
}
if(result != block_production_condition::produced && result == \_prev_result) {
\_prev_result_count++;
}
else {
\_prev_result_count = 1;
\_prev_result = result;
switch(result)
{
case block_production_condition::produced: {
const auto& db = app().get_plugin<chain_plugin>().chain();
auto producer = db.head_block_producer();
......
break;
}
......
}
}
schedule_production_loop();//循环调用
return result;
}
block_production_condition::block_production_condition_enum producer_plugin_impl::maybe_produce_block(fc::mutable_variant_object& capture) {
chain::chain_controller& chain = app().get_plugin<chain_plugin>().chain();
fc::time_point now = fc::time_point::now();
if (app().get_plugin<chain_plugin>().is_skipping_transaction_signatures()) {
\_production_skip_flags |= skip_transaction_signatures;
}
// If the next block production opportunity is in the present or future, we're synced.
if( \!\_production_enabled )
{
if( chain.get_slot_time(1) >= now )
\_production_enabled = true;
else
return block_production_condition::not_synced;
}
// is anyone scheduled to produce now or one second in the future?
uint32_t slot = chain.get_slot_at_time( now );
if( slot == 0 )
{
capture("next_time", chain.get_slot_time(1));
return block_production_condition::not_time_yet;
}
//
// this assert should not fail, because now <= db.head_block_time()
// should have resulted in slot == 0.
//
// if this assert triggers, there is a serious bug in get_slot_at_time()
// which would result in allowing a later block to have a timestamp
// less than or equal to the previous block
//
assert( now > chain.head_block_time() );
auto scheduled_producer = chain.get_scheduled_producer( slot );
// we must control the producer scheduled to produce the next block.
if( \_producers.find( scheduled_producer ) == \_producers.end() )
{
capture("scheduled_producer", scheduled_producer);
return block_production_condition::not_my_turn;
}
auto scheduled_time = chain.get_slot_time( slot );
eosio::chain::public_key_type scheduled_key = chain.get_producer(scheduled_producer).signing_key;
auto private_key_itr = \_private_keys.find( scheduled_key );
......
//此处产生块
auto block = chain.generate_block(
scheduled_time,
scheduled_producer,
private_key_itr->second,
\_production_skip_flags
);
capture("n", block.block_num())("t", block.timestamp)("c", now)("count",block.input_transactions.size())("id",string(block.id()).substr(8,8));
app().get_plugin<net_plugin>().broadcast_block(block);//广播块消息
return block_production_condition::produced;
}
产生块的代码也比较简单,在chain-controller.cpp中:
signed_block chain_controller::generate_block(
block_timestamp_type when,
account_name producer,
const private_key_type& block_signing_private_key,
uint32_t skip /* = 0 */
)
{ try {
return with_skip_flags( skip | created_block, [&](){
return \_db.with_write_lock( [&](){
//直接调用同名函数
return _generate_block( when, producer, block_signing_private_key );
});
});
} FC_CAPTURE_AND_RETHROW( (when) ) }
signed_block chain_controller::_generate_block( block_timestamp_type when,
account_name producer,
const private_key_type& block_signing_key )
{ try {
try {
//检测并获取相关参数值
FC_ASSERT( head_block_time() < (fc::time_point)when, "block must be generated at a timestamp after the head block time" );
uint32_t skip = \_skip_flags;
uint32_t slot_num = get_slot_at_time( when );//获取当前生产者的位置
FC_ASSERT( slot_num > 0 );
account_name scheduled_producer = get_scheduled_producer( slot_num );//获得当前区块的生产者
FC_ASSERT( scheduled_producer == producer );
const auto& producer_obj = get_producer(scheduled_producer);
//如果符合条件,创建一个未决的块
if( !\_pending_block ) {
_start_pending_block();
}
//完成Cycle的构建
_finalize_pending_cycle();
if( !(skip & skip_producer_signature) )
FC_ASSERT( producer_obj.signing_key == block_signing_key.get_public_key(),
"producer key ${pk}, block key ${bk}", ("pk", producer_obj.signing_key)("bk", block_signing_key.get_public_key()) );
//设置未决块转成正式块的相关参数
\_pending_block->timestamp = when;
\_pending_block->producer = producer_obj.owner;
\_pending_block->previous = head_block_id();
\_pending_block->block_mroot = get_dynamic_global_properties().block_merkle_root.get_root();
\_pending_block->transaction_mroot = \_pending_block_trace->calculate_transaction_merkle_root();
\_pending_block->action_mroot = \_pending_block_trace->calculate_action_merkle_root();
if( is_start_of_round( \_pending_block->block_num() ) ) {
auto latest_producer_schedule = _calculate_producer_schedule();
if( latest_producer_schedule != _head_producer_schedule() )
\_pending_block->new_producers = latest_producer_schedule;
}
\_pending_block->schedule_version = get_global_properties().active_producers.version;
if( !(skip & skip_producer_signature) )
\_pending_block->sign( block_signing_key );
//结束块并广播消息保存相关数据
_finalize_block( *\_pending_block_trace, producer_obj );
\_pending_block_session->push();
auto result = move( *\_pending_block );
clear_pending();
if (!(skip&skip_fork_db)) {
\_fork_db.push_block(result);//加入到链中
}
return result;
} catch ( ... ) {
clear_pending();
elog( "error while producing block" );
_start_pending_block();
throw;
}
} FC_CAPTURE_AND_RETHROW( (producer) ) }
交易基本就完成了,这块比较麻烦,而且有些细节其实资料和代码有此不匹配,留待后面继续解决。
转载自:https://github.com/XChainLab/documentation/edit/master/eos/eos%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%E4%B9%8B%E4%B8%89%E4%BA%A4%E6%98%93.md