文章较长,内容很详细、很深入。但是不要吓到,坐下来,喝杯咖啡或你最喜欢的饮料,慢慢体会。
我们来探索Solidity的一个新的和必不可少的部分:数据存储位置。具有挑战性的话题。非常底层,因为它与以太坊虚拟机(EVM)的架构有关。
但通过类比,我们总是可以更好地理解复杂的编程概念、架构、智能合约和一般的区块链。
在这篇文章中,我们将通过类比EVM如果是一个 "巨大的工业工厂 "来学习每个数据位置(我希望能帮助你理解)。
然后我们将进入Solidity代码,学习每个数据位置的参考类型的规则和行为。所有这些都有图画、架构图、代码片段以及你可能知道的流行项目的源代码例子来学习。
这个系列还有另外二篇文章分别介绍存储(Storage)及 内存(memory).
为什么要在 Solidity 中理解 Evm 数据位置?
学习每个数据位置是如何工作的,需要学习很多东西,比如 "存储"、"内存 "和 "calldata"的结构和布局,或者 "什么内容可以存储在哪里"。
但最重要的是,它教会了你与它们每一个相关的(Gas)成本,以及我所说的可变性/安全性的权衡。
作为一个Solidity开发者,对EVM中的数据位置以及如何充分使用它们的良好理解将使你能够:
- 提高你的智能合约的性能。
- 最小化其执行成本(调用其公共或内部函数时使用的Gas差异)。
- 强化安全性,防止潜在的错误。
数据位置 → 概述
本文旨在对这些不同的数据位置做一个很好的概述,数据可以被写入和读出。我们将看到,有些位置是只读的,不能写入,而其他位置是可变的,里面存储的值可以被编辑。
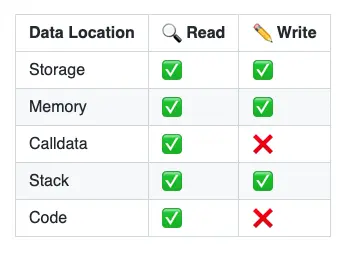
EVM有五个主要的数据位置:
- 存储(Storage)
- 内存(Memory)
- 调用数据(Calldata)
- 堆栈(Stack)
- 代码(Code)
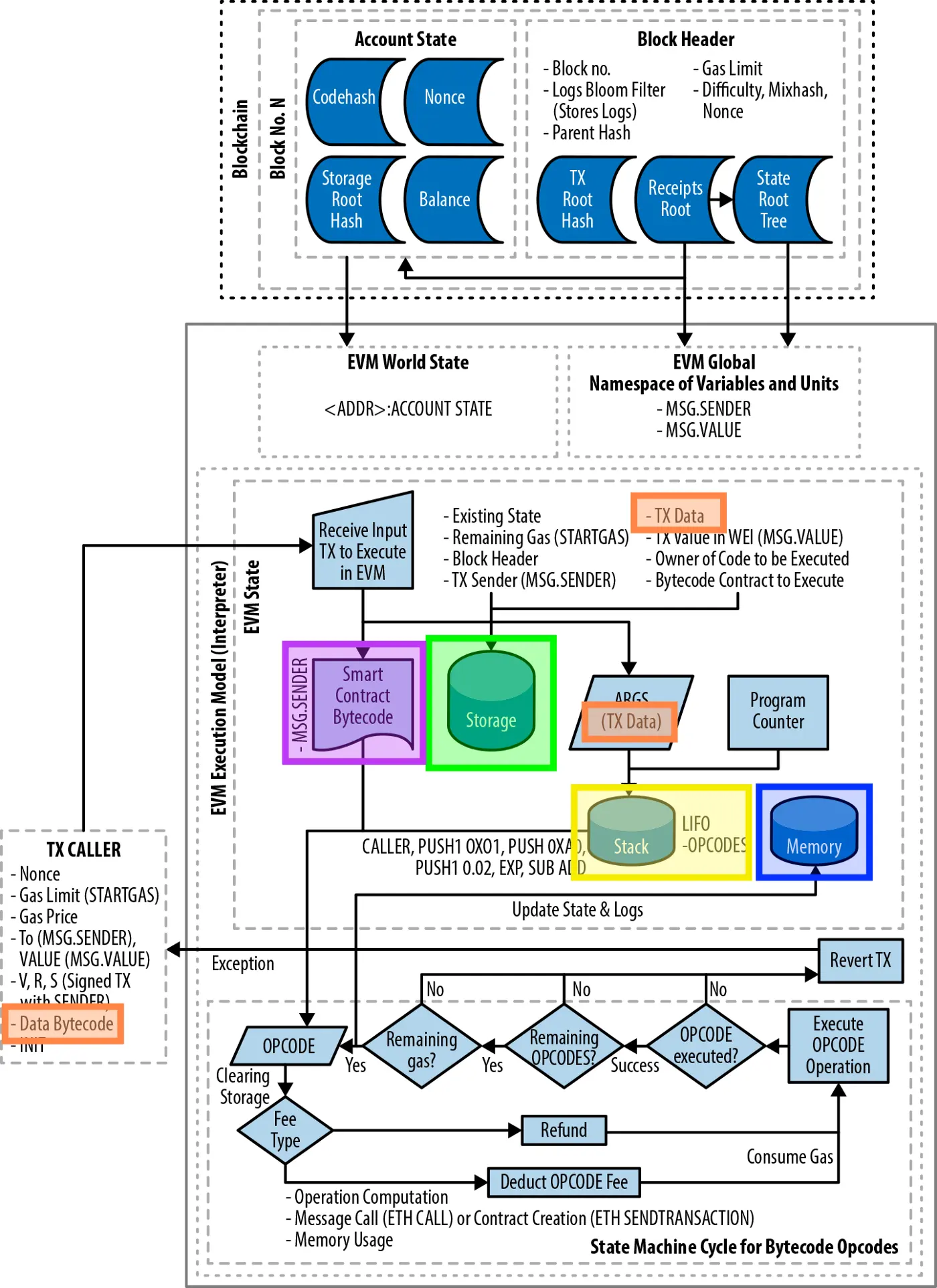
EVM中可用的数据位置概览,来源:精通以太坊 。
存储
在以太坊中,每个特定地址的智能合约都有自己的 "存储",由一个键值存储组成,将256位映射到256位。存储中的数据在函数调用和交易之间持续存在。
存储是所有合约状态变量所在的地方。每个合约都有自己的存储。存储中的变量在函数调用之间持续存在。然而,存储空间的使用是相当昂贵的。
由于存储指的是合约存储,它指的是永久存储在区块链上的数据。
你可以从/向合约存储中读取和写入。在低层,用于这样做的EVM操作码是SSTORE和SLOAD。
内存
EVM 内存是用来保存临时值的,在外部函数调用之间被擦除。然而,它的使用成本比较低。
在EVM中,内存是易失性的,是特定合约(环境)的上下文。这意味着,当执行环境从一个合约变为另一个合约时,“白板/写字板”被清除。在每一个新的消息调用中,都会获得一个新的被清除的内存实例。
因此,内存变量是暂时的。它们在对其他合约的外部函数调用之间被擦除。
你可以从/到EVM内存中读取和写入。在低层,用于从/向内存读写的EVM操作码是MLOAD, MSTORE, 和MSTORE8。
某些EVM操作码,如 "CALL"、"DELEGATECALL "或 "STATICCALL" 从EVM内存中消耗其参数。
Calldata
calldata相当于从船上或卡车上取出的一个集装箱。这些集装箱包含送到工厂进行加工的材料。Calldata是只读的。
calldata是交易的数据或外部函数调用的参数所在的位置。它是一个只读的数据位置。你不能写到它。
Calldata的行为主要类似于内存,是一个可由字节编址的空间。你必须为你想读取的字节数指定一个准确的字节偏移。
在低层,可用于从calldata读取的EVM操作码是CALLDATALOAD, CALLDATASIZE和CALLDATACOPY。
堆栈(Stack)
堆栈是用来存放小型局部变量的。它的使用几乎是免费的(用Gas很低),但大小有限,能容纳的项目数量也有限。
堆栈是大多数在函数内部创建的局部变量所在的地方。它是EVM的一个重要部分。
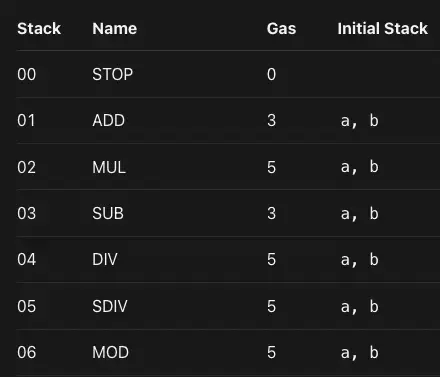
在低层,可以用来对堆栈进行操作的EVM操作码,包括PUSH、POP、SWAP和DUP指令。大多数其他的EVM操作码从堆栈中消耗数据(通过从堆栈中取出),并将结果推回堆栈中。
代码
代码指的是合约的字节码。你只能从合约字节码中读取,而不能写到它。通常是你在Solidity中定义为 constant的变量。大多数的EVM操作码从堆栈中消耗它们的参数。
字节码包含了很多关于合约的信息和逻辑,包括调度器,以及合约元数据。
在低层,从智能合约的代码中读取的EVM操作码是CODESIZE和CODECOPY及操作码EXTERNALCODESIZE和EXTERNALCODECOPY。
数据位置 - 规则
变量的默认位置
Solidity语言定义了一些默认的规则,围绕着一些变量的默认位置,取决于它们被定义的位置。
-
定义为 constant的变量 = 合约代码(=bytecode)。
这些变量是不可改变的,一旦合约被部署就不能改变。它们是只读的,可以被内联使用。
-
状态变量(在函数之外声明) = 默认情况下在存储中。
这些被称为状态变量,因为它们是合约状态的一部分,反过来也是区块链全局状态的一部分(=以太坊中所有智能合约的状态)。这些变量被永久地写入区块链。
-
本地变量(在函数体内声明)= 在堆栈中。
值类型的变量(例如,uint256, bytes8 , address)驻留在堆栈中。
大多数时候,你不需要使用数据位置关键字(storage,memory,或calldata),因为Solidity通过上面解释的默认规则处理数据的位置。
然而,有时你确实需要使用这些关键字并指定数据位置,即在处理复杂类型的变量时,如函数内的结构体和数组。
参考类型
对于数组(固定或动态大小的数组, 如uint256[]), bytes, string, 结构和映射, 你必须明确提供存储值的数据区域. 这可以是storage,memory或calldata。
通过使用这些关键字,你可以创建一个 "引用" 类型的变量。这种类型必须比值类型更仔细地处理。
下一个问题自然就出现了:
什么时候使用关键字存储(storage),内存(memory),和calldata?
你只能在函数中的3个地方指定引用一个变量的数据位置。
- A) 对于参数(=函数定义)
- B) 对于函数内部的局部变量(=函数主体)
- C) 返回值总是在内存中(=函数定义)。
在函数参数上的规则
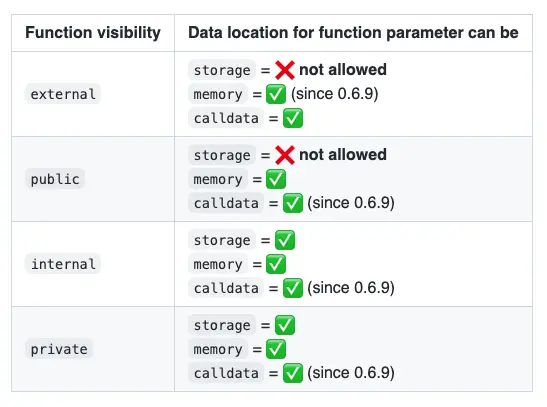
当storage被用作一个函数参数的引用时,它是一个指向合约存储的指针。
对于memory和calldata也是如此。这样的关键字指向EVM内存中的某个位置或从交易中进来的输入数据(=calldata)的指针。
在函数体内的规则
在函数内部,无论函数的可见性如何,都可以指定所有三个数据位置:
然而,引用类型之间的赋值是受特定规则约束的。(这里是变得复杂和 "略微扭曲舌头的地方!")。
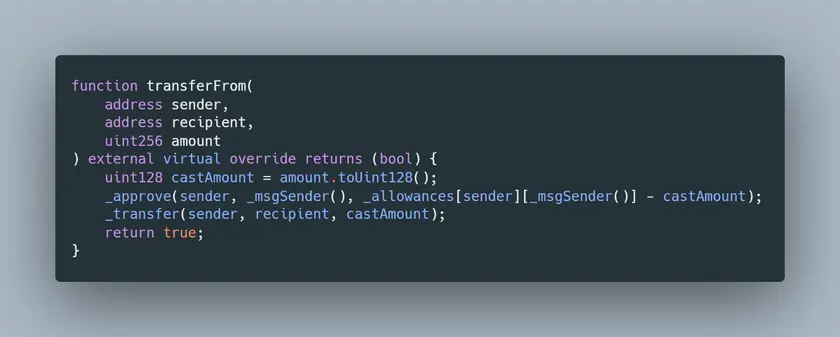
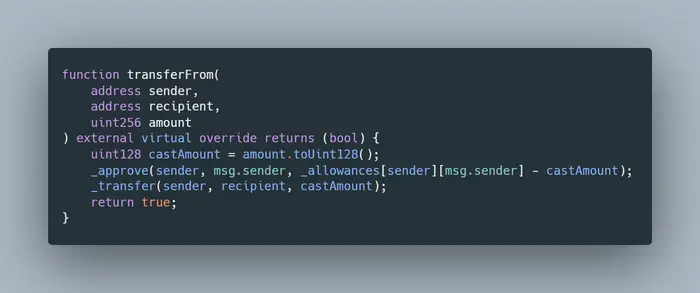
- storage 引用:总是可以直接从合约存储中(=状态变量)或通过另一个 "存储" 引用 给一些变量赋值,但它们不能赋值一个 "内存 "或 "calldata "引用。
- memory引用:可以被分赋值任何东西(直接的状态变量,或storage、memory或calldata引用)。它总是创建一个副本。
- calldata引用:总是可以直接从calldata(= tx/message调用的输入),或通过另一个calldata引用赋值,但它们不能从storage或memory引用赋值。
为了更简单地描述它。
- 对于memory =总是可以复制内存中的任何数据(无论它来自合约的存储还是calldata)。
- 对于存储和calldata = 我们只能分配来自指定数据位置的值(无论是直接类型还是通过相同类型的引用)。
让我们看看一些真实的、实用的Solidity例子:

// SPDX-License-Identifier: Apache-2
pragma solidity ^ 0.8 .0;
contract StorageReferences {
bytes someData;
function storageReferences() public {
bytes storage a = someData;
bytes memory b;
bytes calldata c;
// storage variables can reference storage variables as long as the storage
reference they refer to is initialized.
bytes storage d = a;
// if the storage reference it refers to was not initiliazed, it will lead
to an error
// "This variable (refering to a) is of storage pointer type and can be
accessed without prior assignment,
// which would lead to undefined behaviour."
// basically you cannot create a storage reference that points to another
storage reference that points to nothing
// f -> e -> (nothing) ???
/// bytes storage e;
/// bytes storage f = e;
// storage pointers cannot point to memory pointers (whether the memory
pointer was initialized or not
/// bytes storage x = b;
/// bytes memory r = new bytes(3);
/// bytes storage s = r;
// storage pointer cannot point to a calldata pointer (whether the calldata
pointer was initialized or not).
/// bytes storage y = c;
/// bytes calldata m = msg.data;
/// bytes storage n = m;
}
}

// SPDX-License-Identifier: Apache-2
pragma solidity ^ 0.8 .0;
contract DataLocationsReferences {
bytes someData;
function memoryReferences() public {
bytes storage a = someData;
bytes memory b;
bytes calldata c;
// this is valid. It will copy from storage to memory
bytes memory d = a;
// this is invalid since the storage pointer x is not initialized and does
not point to anywhere.
/// bytes storage x;
/// bytes memory y = x;
// this is valid too. `e` now points to same location in memory than `b`;
// if the variable `b` is edited, so will be `e`, as they point to the same
location
// same the other way around. If the variable `e` is edited, so will be `b`
bytes memory e = b;
// this is invalid, as here c is a calldata pointer but is uninitialized,
so pointing to nothing.
/// bytes memory f = c;
// a memory reference can point to a calldata reference as long as the
calldata reference
// was initialized and is pointing to somewhere in the calldata.
// This simply result in copying the offset in the calldata pointed by the
variable reference
// inside the memory
bytes calldata g = msg.data[10: ];
bytes memory h = g;
// this is valid. It can copy the whole calldata (or a slice of the
calldata) in memory
bytes memory i = msg.data;
bytes memory j = msg.data[4: 16];
}
}

// SPDX-License-Identifier: Apache-2
pragma solidity ^ 0.8 .0;
contract DataLocationsReferences {
bytes someData;
function calldataReferences() public {
bytes storage a = someData;
bytes memory b;
bytes calldata c;
// for calldata, the same rule than for storage applies.
// calldata pointers can only reference to the actual calldata or other
calldata pointers.
}
}
你可以在这里找到Solidity合约代码
内存←状态变量
contract MemoryCopy {
bytes someData;
constructor() {
someData = bytes("All About Solidity");
}
function copyStorageToMemory() public {
// assigning memory <\-- storage
// this load the value from storage and copy in memory
bytes memory value = someData;
// changes are not propagated down in the contract storage
value = bytes("abcd");
}
}
当我们将一个状态变量赋值给一个内存引用的变量时,基本上是将数据从存储空间→复制到内存。
= 我们正在向内存写入 =新的内存被分配。
这意味着对变量的任何修改都不会影响到合约存储(=合约状态)。
= 合约存储将不会被重写。
在上面的例子中,运行函数后,状态变量someData没有被改变。
状态变量 ←内存
这是前一个例子 "内存←状态变量 "的反例。同样会进行整体拷贝,这个例子可以在Solidity文档部分找到。
存储指针
contract StoragePointer {
uint256[] someData;
uint256[] moreData;
function createStoragePointer() public {
// pointer to storage
uint256[] storage value = someData;
// pointer to somewhere else in storage
value = moreData;
}
}
当一个storage变量在一个函数中被创建时,这基本上是作为一个存储指针。存储指针简单地引用已经分配到存储空间的数据。
你可以重新分配存储指针,将其指向存储中的其他地方。
= 引用存储中的一些现有值 = 不创建新的存储
然而,我们可以通过直接给查找变量分配一个新的值来覆盖合约存储。看一下这个例子。
contract StoragePointer {
uint256[] public someData;
function pushToArrayViaPointer() public {
uint256[] storage value = someData;
value.push(1);
}
}
如果你接着查询someData的第一个索引,你会得到1
内存←存储指针
当我们将一个storage引用的数据分配给一个memory引用的变量时, 我们是在从storage → memory中复制数据。
= 我们是在向内存写数据 = 新的内存被分配。
这等同于我们之前涉及的第一种情况 "内存←状态变量",并通过存储引用增加了 "中间的额外路径"。存储引用将解析到状态变量,然后将其复制到内存。下面是一个建立在前面的代码片段上的基本例子。
contract MemoryCopy {
uint256[] public someData;
function copyStorageToMemoryViaRef() public {
uint256[] storage storageRef = someData;
uint256[] memory copyFromRef = storageRef;
}
}
这里copyFromRef是整个数组someData的拷贝。这个数组是通过存储引用storageRef在内存中复制的。
同样在此案例中,由于我们从存储空间复制到内存,我们是在操作数据的副本,而不是在存储空间中的实际数据上。因此,对copyFromRef所做的任何修改都不会影响合约存储,也不会修改合约状态。
为了说明这一点,请在Remix中复制以下合约,然后。
- 运行函数test()。
- 在索引1处读取someData数组。
contract MemoryCopy {
uint256[] public someData;
constructor() public {
someData.push(1);
someData.push(2);
someData.push(3);
}
function doesNotPropagateToStorage() public {
uint256[] storage storageRef = someData;
uint256[] memory copyFromRef = storageRef;
copyFromRef[1] = 12345;
}
}
你会看到在运行函数后,someData[1]的值仍然是2,而且12345并没有传播回合约存储。
calldata引用
Calldata引用的行为与storage引用相同。它只能作为交易数据的引用,或者作为用calldata关键字提供的复杂类型的函数参数的引用。
简而言之,一个calldata类型的变量总是创建一个引用。
唯一的主要区别是,作为calldata引用的变量不能被修改,因为calldata是只读的。
这与storage引用恰恰相反。当你给storage引用分配一个新的值时,这个变化会传播到合约状态。
数据位置 - 行为
本节借鉴了Forest Fang 的文章
我强烈推荐你阅读它! 我曾用它来分析更多的底层EVM操作代码,以了解在背后发生了什么。
Solidity文档中提到了以下内容:
"数据位置不仅与数据的持久性有关,而且还与赋值的语义有关"。
在指定函数体内部的数据位置时,必须考虑两个主要问题:效果和Gas消耗。
让我们用一个简单的合约作为例子来更好地理解。这个合约在存储中持有一个结构体的映射。为了比较每个数据位置的行为,我们将使用不同的函数,使用不同的数据位置关键字。
- 使用存储 "storage"的getter。
- 使用内存 "memory"的getter。
- 使用存储 "storage"的setter。
- 使用内存 "memory"的setter。
// SPDX-License-Identifier: Apache-2.0
pragma solidity ^ 0.8 .0;
contract Garage {
struct Item {
uint256 units;
}
mapping(uint256 => Item) items;
// gas (view): 24,025
function getItemUnitsStorage(uint _itemIndex) public view returns(uint) {
Item storage item = items[_itemIndex];
return item.units;
}
// gas (view): 24,055
function getItemUnitsMemory(uint _itemIndex) public view returns(uint) {
Item memory item = items[_itemIndex];
return item.units;
}
// gas: 50,755 (1st storage write)
function setItemUnitsStorage(uint256 _id, uint256 _units) public {
Item storage item = items[_id];
item.units = _units;
}
// gas: 27,871
function setItemUnitsMemory(uint256 _id, uint256 _units) public {
Item memory item = items[_id];
item.units = _units;
}
}
使用存储的Getter 与 内存的Getter 对比
我们要问自己的第一个问题是:使用内存的getter还是使用存储的getter更便宜?它们各自是如何工作的?
// gas (view): 24,025
function getItemUnitsStorage(uint _itemIndex) public view returns(uint) {
Item storage item = items[_itemIndex];
return item.units;
}
// gas (view): 24,055
function getItemUnitsMemory(uint _itemIndex) public view returns(uint) {
Item memory item = items[_itemIndex];
return item.units;
}
使用 "storage "的getter比使用 "memory "的getter稍微便宜一些,因为它充当了一个存储指针。
使用memory的getter更贵,花费更多的Gas,因为要创建一个新的变量。在上面的例子中,除了读取存储映射items[_itemIndex]里面的值之外,它还会复制内存中的值。
让我们确保理解这里到底发生了什么。根据关键字 "storage "或 "memory",EVM在幕后做了什么?
我在下面列出了两种获取器类型的操作码序列(为了清晰和简洁,左边没有写程序计数器)。你可以通过在Remix中调试代码来查看它们。
如果我们比较两个getter函数的操作码,我们会发现,与使用内存的getter(45条指令)相比,使用存储的getter包含更少的操作码(30条指令)。
建议:我强烈建议使用evm.codes网站来测试这两个函数,并分析操作码和存储/内存中一个又一个操作码的变化。
; getItemUnitsStorage = 30 instructions
PUSH1 00 ; 1) manipulate + prepare the stack
DUP1
PUSH1 00
DUP1
DUP5
DUP2
MSTORE ; 2.1) prepare the memory for hashing (1)
PUSH1 20
ADD
SWAP1
DUP2
MSTORE ; 2.2) prepare the memory for hashing (2)
PUSH1 20
ADD
PUSH1 00
SHA3 ; 3) compute the storage number to load via hashing
SWAP1
POP
DUP1
PUSH1 00
ADD
SLOAD ; 4) load mapping value from storage
SWAP2
POP
POP
SWAP2
SWAP1
POP
JUMP
JUMPDEST
; getItemUnitsMemory = 47 instructions
PUSH1 00
DUP1
PUSH1 00
DUP1
DUP5
DUP2
MSTORE
PUSH1 20
ADD
SWAP1
DUP2
MSTORE
PUSH1 20
ADD
PUSH1 00
SHA3
PUSH1 40 ; <------ additional opcodes start here
MLOAD ; 1) load the free memory pointer
DUP1 ; 2) reserve the free memory pointer by duplicating it
PUSH1 20
ADD ; 3) compute the new free memory pointer
PUSH1 40
MSTORE ; 4) store the new free memory pointer
SWAP1
DUP2
PUSH1 00
DUP3
ADD
SLOAD ; 5) load mapping value from storage
DUP2
MSTORE ; 6) store mapping value retrieved from storage in memory
POP
POP ; <------------ additional opcodes end here
SWAP1
POP
DUP1
PUSH1 00
ADD
MLOAD
SWAP2
POP
POP
SWAP2
SWAP1
POP
在底层,EVM对一个使用storage的getter执行以下步骤。
- 操作 + 准备堆栈
- 为 hash准备内存((1)和(2))。
- 计算要通过hash和SHA3加载的值的存储槽(=来自映射的值在哪个存储槽。见我的文章 关于映射,以更好地理解如何计算/计算映射的存储槽)。
- 通过SLOAD从存储空间加载值。
你可以在这里看到存储版本的getter函数堆栈的所有细节说明 。
然后出现的下一个问题是: 为什么内存的getter函数底层字节码指令中多了17条?
答案就在上面的汇编代码的描述注释中。这17条额外的EVM指令执行以下内容:
它在内存中预留了一些空间用于存储数值,方法是:
- 加载空闲内存指针,
- 预留,
- 计算内存中下一个空闲空间,
- 更新新的空闲内存指针。(mload + mstore)
- 一旦数值通过SLOAD从合约存储中加载,然后通过MSTORE写入内存。
你可以在这里看到内存版的getter堆栈的所有细节的说明。
使用storage 与memory的 Setter 函数对比
我推荐来吃Rob Hitchens这篇文章"Solidity中的存储指针:'这里有龙'"
以更好地理解使用setter函数的行为:
// gas: 50,755 (1st storage write)
function setItemUnitsStorage(uint256 _id, uint256 _units) public {
Item storage item = items[_id];
item.units = _units;
}
// gas: 27,871
function setItemUnitsMemory(uint256 _id, uint256 _units) public {
Item memory item = items[_id];
item.units = _units;
}
当为一个变量指定storage并设置其值时,它将修改状态变量并覆盖合约存储。这将使用SSTORE操作码。
相反,如果使用关键字memory,它将仅仅覆盖本地变量,而不覆盖合约存储。这将使用MSTORE操作码。
当涉及到EVM指令集时,我们可以从下面的片段中看到,使用storage产生的指令要少很多(storage产生28条,而memory产生48条)。然而,使用storage将花费更多的Gas,因为存储读/写是EVM中最昂贵的操作。
; setItemUnitsStorage = 28 instructions
PUSH1 00
DUP1
PUSH1 00
DUP5
DUP2
MSTORE
PUSH1 20
ADD
SWAP1
DUP2
MSTORE
PUSH1 20
ADD
PUSH1 00
SHA3
SWAP1
POP
DUP2
DUP2
PUSH1 00
ADD
DUP2
SWAP1
SSTORE
POP
POP
POP
POP
; setItemUnitsMemory = 46 instructions
PUSH1 00
DUP1
PUSH1 00
DUP5
DUP2
MSTORE
PUSH1 20
ADD
SWAP1
DUP2
MSTORE
PUSH1 20
ADD
PUSH1 00
SHA3
PUSH1 40
MLOAD
DUP1
PUSH1 20
ADD
PUSH1 40
MSTORE
SWAP1
DUP2
PUSH1 00
DUP3
ADD
SLOAD
DUP2
MSTORE
POP
POP
SWAP1
POP
DUP2
DUP2
PUSH1 00
ADD
DUP2
DUP2
MSTORE
POP
POP
POP
POP
POP
映射的(边缘)情况
映射可以作为参数传递给函数或定义在函数体内。然而,它们是一个边缘案例,有两个特定的规则:
- 它们只能被分配到storage数据位置,作为对已经存在于合约存储中的映射的引用。
- 它们必须被初始化为一个值。
这是因为映射不能被动态地创建。它们只能被定义在函数体内,作为对已经作为状态变量存在的映射的引用。
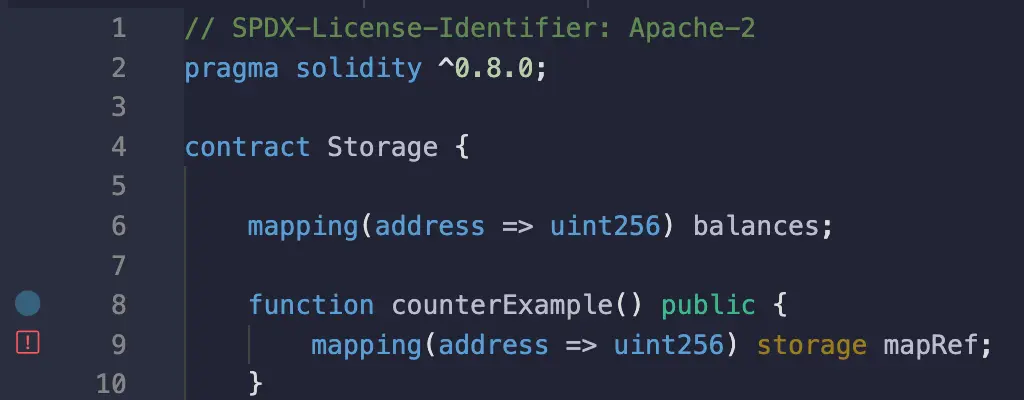
如果你在Remix中这样写...

这就是你将得到的错误。
结论
你应该使用storage, memory, 还是calldata取决于你在合约中试图做什么。
对于某些数据类型,如果数据很大,把它们从存储空间复制到内存中可能会很昂贵。
然而,在某些情况下,如果你想在函数中覆盖变量,而不把结果传播到合约存储中,这可能是必要的。
另一方面,calldata提供了比内存更多的好处:
- 节省Gas=通过避免将数据复制到内存中(从而在之后不得不从内存中加载)。
- 更安全(在某些情况下) = 因为calldata是一个只读的数据位置,它可以确保数据不能被修改。这可能会增加安全性,特别是当传递给函数的参数代表 敏感 数据(例如64字节的签名)时。
calldata在 Solidity 文档中确实被推荐:

然而,在某些情况下,使用memory而不是calldata可以提高可组合性
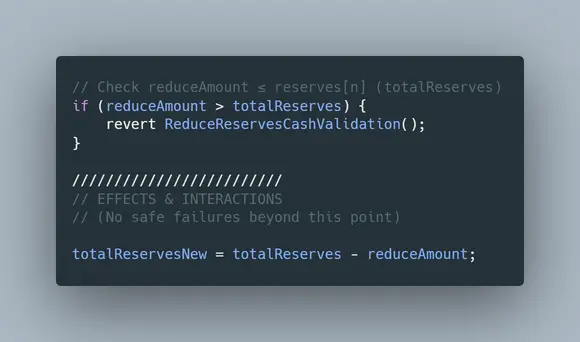
最后,请注意,在你的函数中不使用适当的数据位置会导致潜在的错误和漏洞。一个现实世界的例子是对Cover协议的无限铸币攻击。
看看这个来自Cover协议的Blacksmith.sol合约的代码片断:
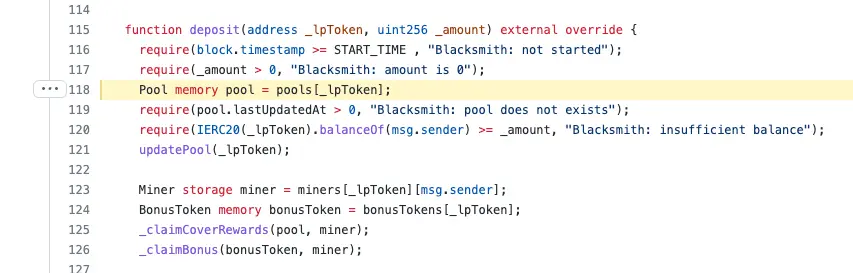
对池变量所做的任何改变都是在内存中进行的,而不是传回合约存储。
关于这个错误的更多细节,请看Mudti Gupta的博文:https://mudit.blog/cover-protocol-hack-analysis-tokens-minted-exploit/
参考文献
Solidity中的数据表示
以太坊 Solidity: 内存与存储以及在本地函数中使用哪一种?
深入以太坊, Part 2
类型 - Solidity 0.8.15 文档
All-About-Solidity/Data-Locations.md
EVMillustrated
以太坊虚拟机
深入EVM
cover 分析
本翻译由 Duet Protocol 赞助支持。
转载自:https://learnblockchain.cn/article/4864

 ,编译器会优化以便在运行时尽可能低 gas 消耗,不过部署时的字节码可能大一些。
,编译器会优化以便在运行时尽可能低 gas 消耗,不过部署时的字节码可能大一些。