最近社区很多小伙伴来询问Chia分布式部署的方法,那我们今天就写一下Chia分布式的步骤以及测试环境验证
分布式的逻辑
其实前面已经写过部署的草稿了《Chia 分布式部署文档》,但是由于当时时间紧,对于没有开发基础的小伙伴理解上还是有些难度。
下面我们详细说下分布式拆分原理以及注意事项
下面是Chia架构模块结构
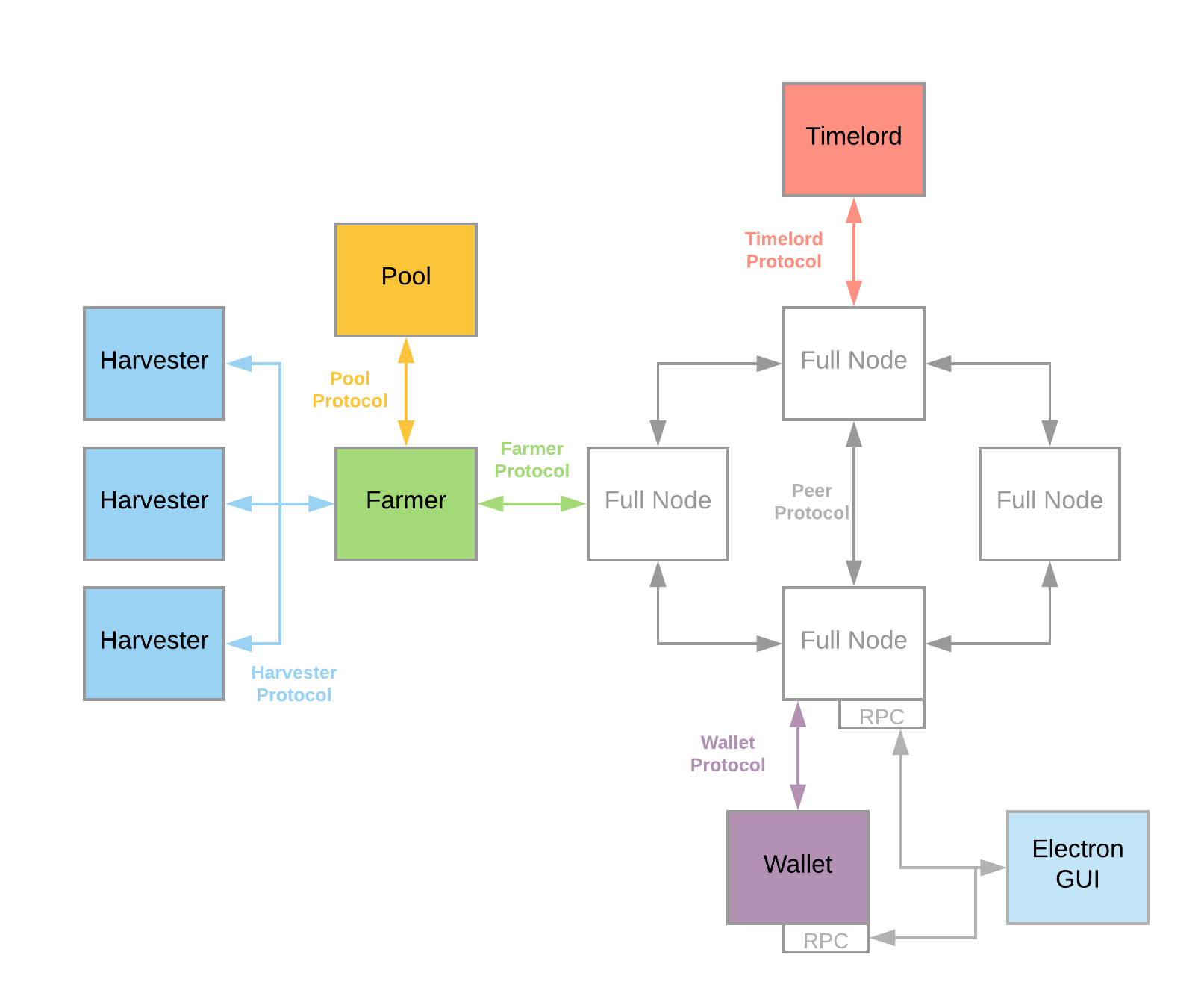
简单说每个模块都是单独的程序,都是通过TCP连接的,对于Chia Gui程序,默认运行是把各个模块都运行在本地,localhost连接的。对于分布式来说,就是把各个模块根据功能和负载等因素分不到不同机器。
模拟生产环境
由于plots存储量体量无上限,并且数据可重新生成,对于存储量和数据安全来说,优先选择存储量,所以单盘存储,不做raid。
对于专门做Chia挖矿的,一般的硬件配置是搞一部分配置稍微好的机器做P盘机(绘图机/work机..){稍后会专门写一篇推荐生产P盘配置的文章},一些二手的存储机做存储(服务器前部分是磁盘阵列),P盘机硬件配置存储部分只有SSD临时绘图用,最终的plots存储到存储机《为Chia P盘机器提供存储服务》
此篇文章我们主要讲挖矿的分布式,对于P盘自动化,后面会有专门的程序和文章做讲解。
生产环境中,一般是把所有的机器放到一个IDC机房,或者自己来管理,所以模块内服务器都是内网连接,网络环境相对简单。
中控高度可控
对于系统化架构的设计大致如下,各模块彼此低耦合,对于一台机器只要装上中控子服务,配置好Chia中控调度地址,Chia中控调度服务会自动配置该机器的环境,并自动下发相应的任务,减少用户的学习成本。
也可以用于推广绘图算力和绘图存储,
用户只需要安装对应中控子服务(绘图/存储),Chia中控调度中心即可自动下发对应的任务,对于绘图任务类似POW,根据用户绘图量用户得到相应的奖励。
用户也可以选择存储任务,此时中控子服务会下发已经会好的图,用户无感知,只需要准备好足够容量的存储空间即可,子服务会自动安装好Harvester相关服务配置,中控调度只需要定时检查用户存储状态和网络环境,就可以根据工作量进行奖励发放。当然发放的可以别的链的对应代币,可以用于对冲推广代币等。
只是对调度服务的另一个使用场景吧,
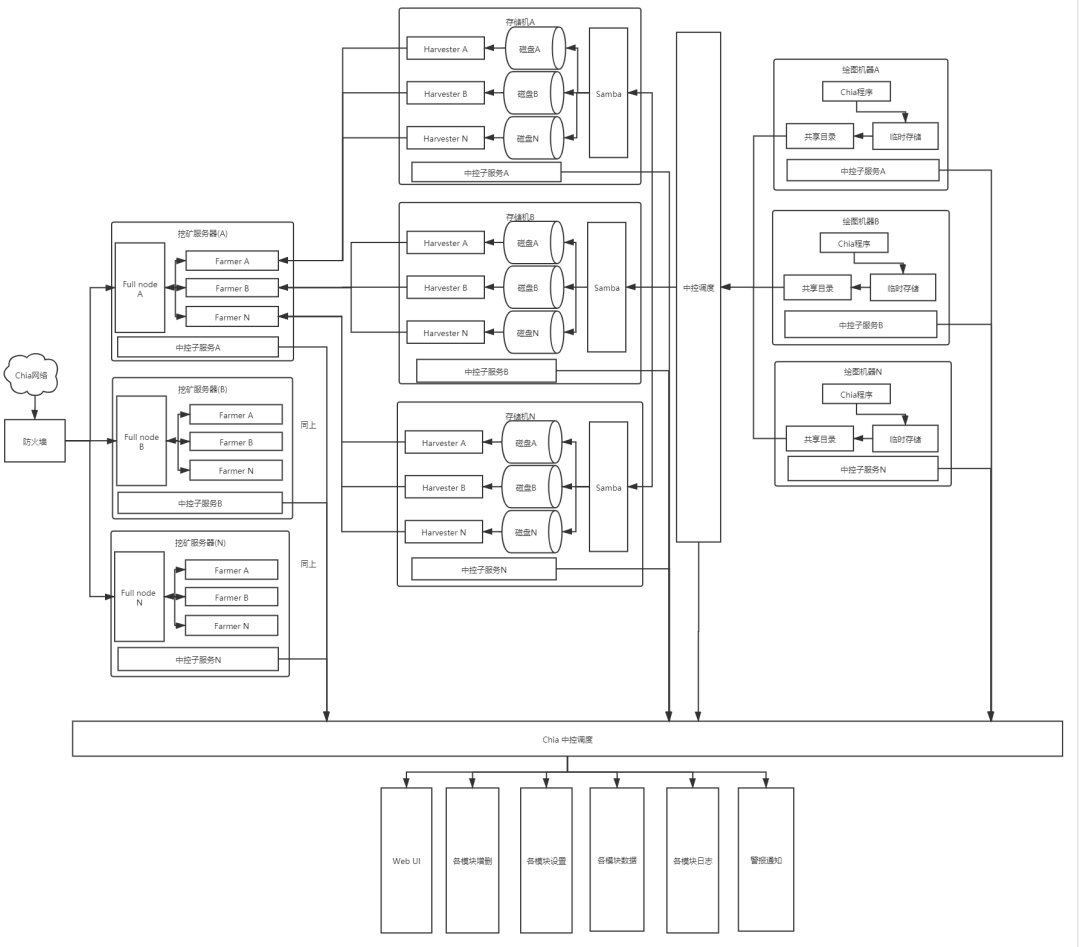
后面社区也许会推出整体服务,暂时不确定
对于没有开发能力的,架构中的中控服务可以先用人工来代替
简化后架构如下
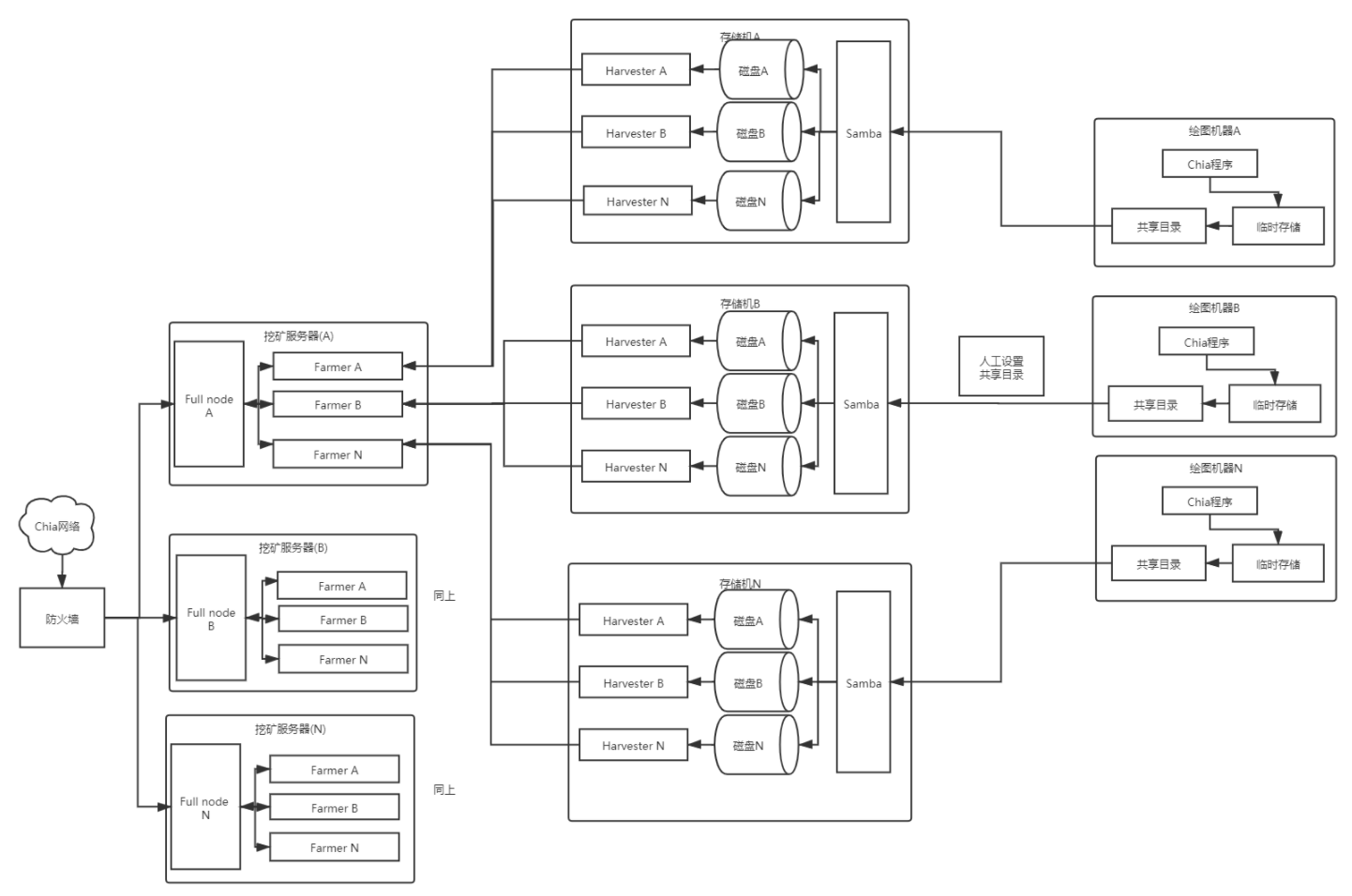
对于各模块的增改也先人工处理
实际测试
我们来演示最基础的分布式挖矿配置,一台挖矿服务器和两台存储服务器之前的配置,以及验证配置是否正确。
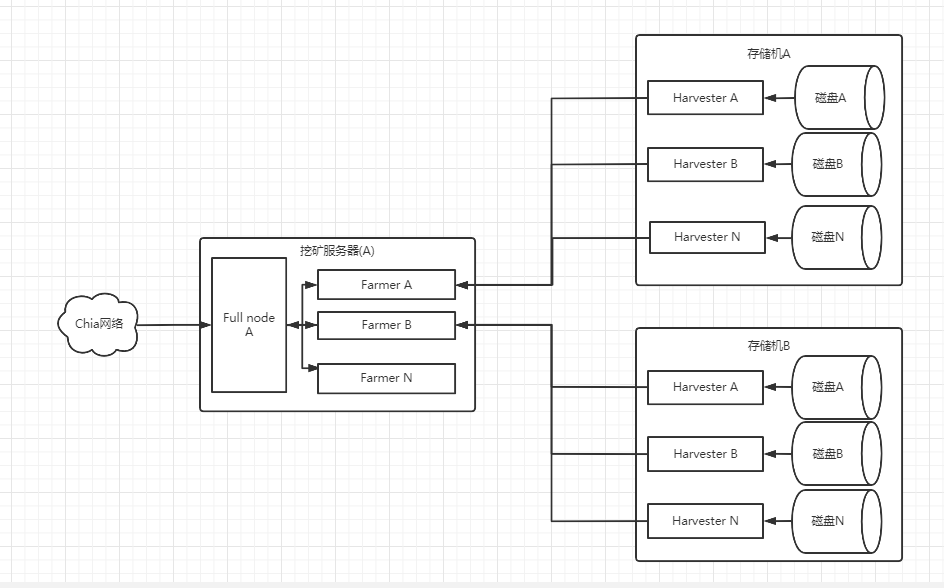
稍后继续补充
版权属于:区块链中文技术社区 / 转载原创者
本文链接:https://bcskill.com/index.php/archives/1084.html
相关技术文章仅限于相关区块链底层技术研究,禁止用于非法用途,后果自负!本站严格遵守一切相关法律政策!