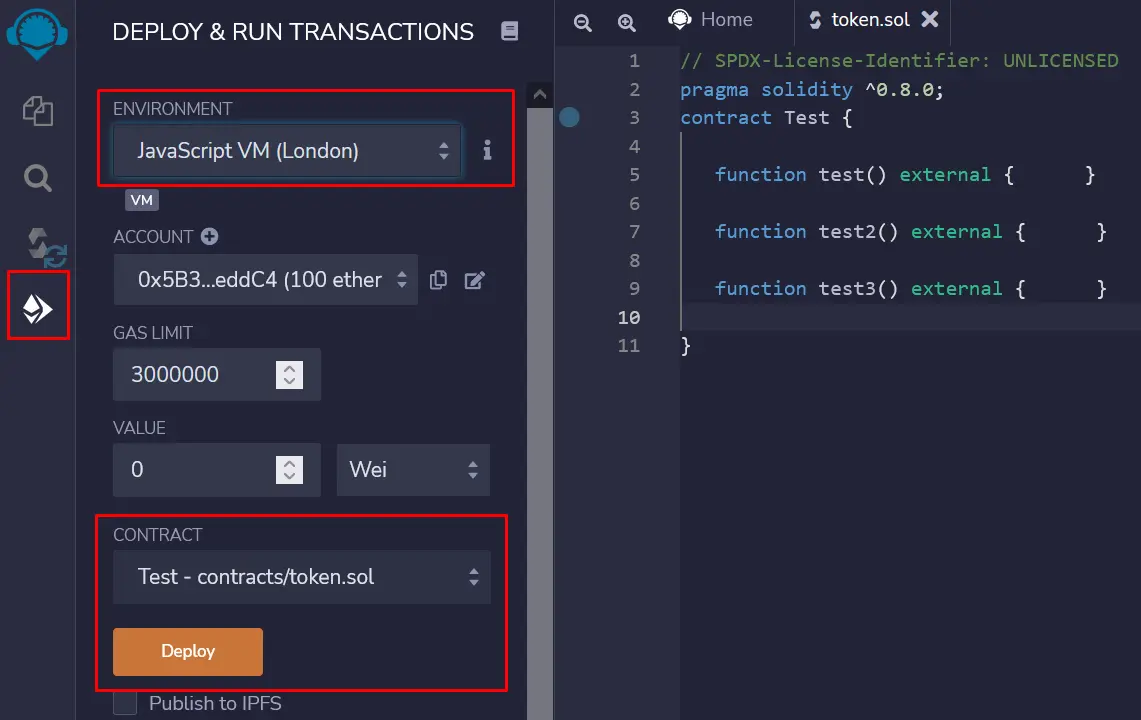
Solidity delegatecall (委托调用)是一个低级别的函数,其强大但棘手,如果使用得当,可以帮助我们创建 可扩展 的智能合约,帮助我们修复漏洞,并为现有的智能合约增加新的功能
Solidity delegatecall (委托调用)是一个低级别的函数,它允许我们在主合约的上下文的情况下加载和调用另一个合约的代码。这意味着被调用合约的代码被执行,但被调用合约所做的任何状态改变实际上是在主合约的存储中进行的,而不是在被调用合约的存储中。
这对创建库和代理合约模式很有用,我们把调用委托给不同的合约,"给它们"权限来修改调用合约的状态。
这个功能也有一些我们需要注意的隐患,基本上是本文要重点关注的内容。
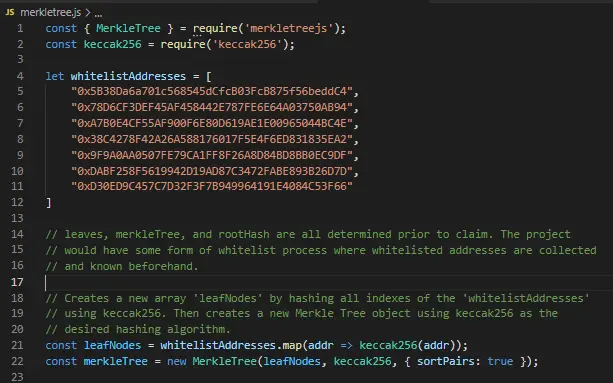
正如另一篇关于存储中状态变量布局的文章 和 Solidity 文档 中解释的那样,合约中声明的每个状态变量都在存储中占据一个槽,如果它们的类型小于32字节,并且可以一起放入一个槽中,则可能与其他状态变量共享一个公共槽。
所以,当我们访问这些状态变量,给它们赋值或从它们那里读取时,Solidity 用该状态变量的声明位置来知道访问哪个存储槽并从它那里读取或更新它。
例如,给定以下合约:
contract EntryPointContract {
address public owner = msg.sender;
uint256 public id = 5;
uint256 public updatedAt = block.timestamp;
}我们看到它声明了3个状态变量,owner,id和updatedAt。这些状态变量有赋值,在存储中,它们看起来像这样:

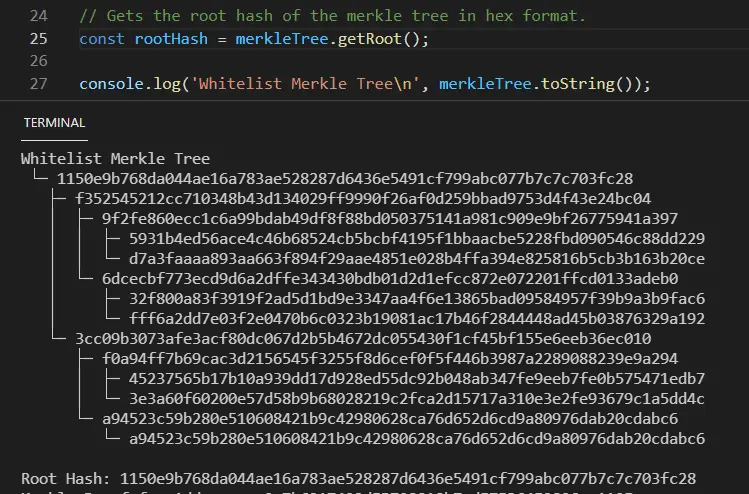
我们看到,在索引0 存储槽处,我们有第一个状态变量的值使用零填充,因为每个槽可以容纳32个字节的数据。
第二个槽,索引为1,保存了 "id"状态变量的值。
第三个槽,索引为2,有第三个状态变量updatedAt的值。所有存储的数据都以十六进制表示,所以转换 0x62fc3adb到十进制是1660697307,用js转换为日期:
const date = new Date(1660697307 * 1000);
console.log(date)结果:
Tue Aug 16 2022 20:48:27 GMT-0400 (Atlantic Standard Time))所以,在访问状态变量id时,我们是在访问索引为1的槽。
很好,那么,使用delegatecall的陷阱在哪里?
为了让委托合约对主合约的存储进行修改,它同样需要声明自己的变量,其顺序与主合约的声明顺序完全相同,而且通常有相同数量的状态变量。
例如,上面的 EntryPointContract 的委托合约,需要看起来是这样的:
contract DelegateContract {
address public owner;
uint256 public id;
uint256 public updatedAt;
}有完全相同的状态变量,完全相同的类型,完全相同的顺序,最好有完全相同数量的状态变量。在此案例中,每个合约有3个状态变量。
让我们展示一下这两个合约:
contract DelegateContract {
address public owner;
uint256 public id;
uint256 public updatedAt;
function setValues(uint256 _newId) public {
id = _newId;
}
}
contract EntryPointContract {
address public owner = msg.sender;
uint256 public id = 5;
uint256 public updatedAt = block.timestamp;
address delegateContract;
constructor(address _delegateContract) {
delegateContract = _delegateContract;
}
function delegate(uint256 _newId) public returns(bool) {
(bool success, ) =
delegateContract.delegatecall(abi.encodeWithSignature("setValues(uint256)",
_newId));
return success;
}
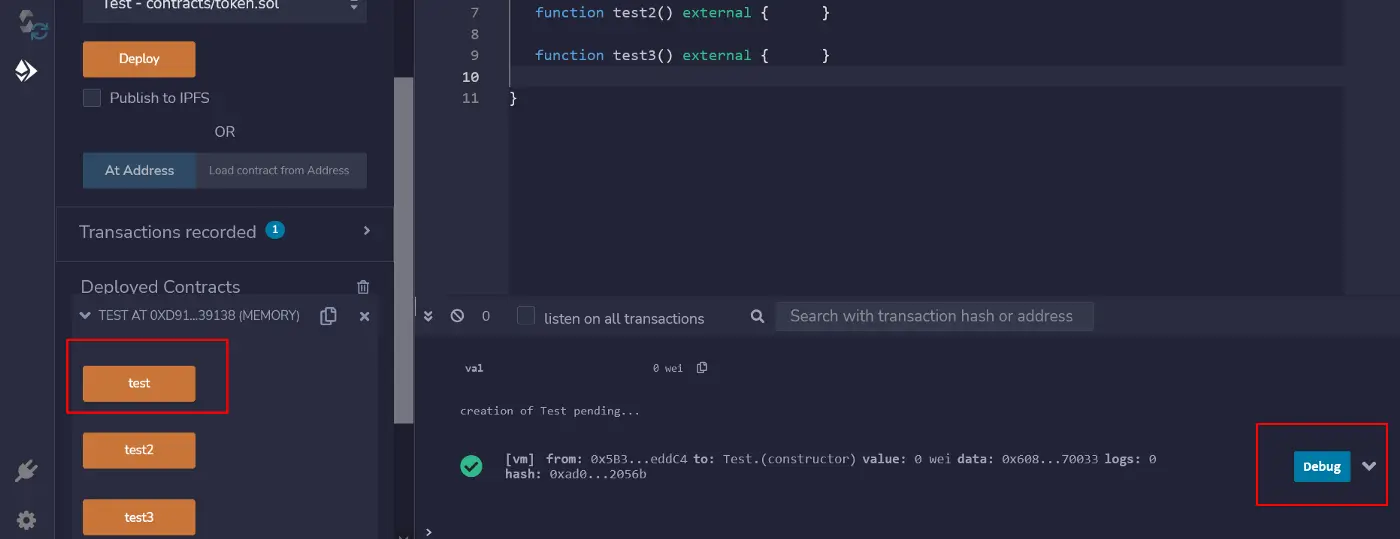
}这里我们看到了一个真正简单的代理合约的实现。EntryPointContract有一个构造函数,接收部署的DelegateContract的地址来委托它的调用,以便自己的状态被DelegateContract修改。
该delegate函数收到一个要设置的_newId,所以它使用低级别的delegatecall将该调用委托给DelegateContract 来更新id变量。
在用新的id值调用delegate函数,并检查EntryPointContract和DelegateContract合约的变量id值后,我们看到只有EntryPointContract的状态变量id有值,而DelegateContract的id状态变量没有赋值,仍然被设置为0,因为DelegateContract修改的不是它自己的存储,而是EntryPointContract的存储。
很好!
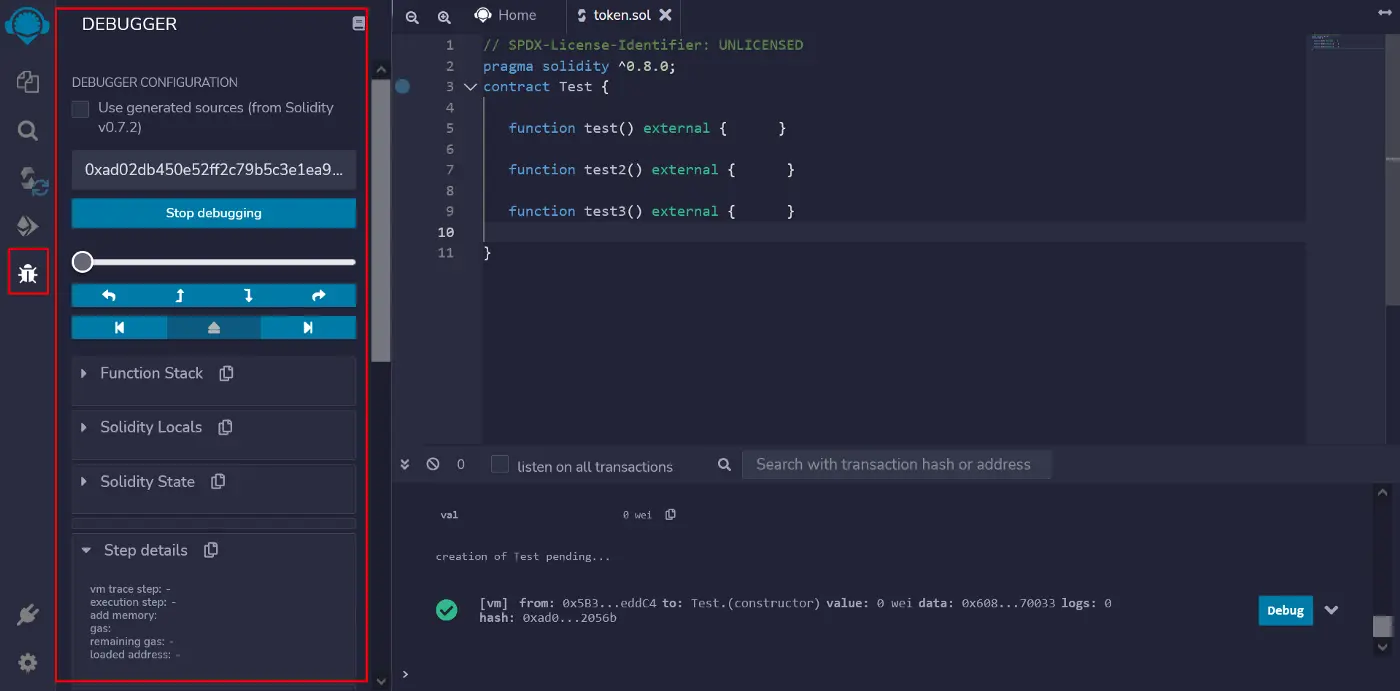
在第7行,我们看到id = _newId,但是,虽然听起来很奇怪,它并没有修改EntryPointContract的id变量,却实际上修改了EntryPointContract的存储槽, 我们知道EntryPointContract中的id变量被声明在索引为1的槽中,如上图所示。
这可能会引起混淆,因为我们实际上看到代码正在给DelegateContract中的id变量赋值,你可能认为不管这个变量在EntryPointContract或DelegateContract中的位置在哪里,它仍然会修改EntryPointContract中的id状态变量槽。但是不是这样的。
例如,在下面的合约中,我在DelegateContract中声明了id状态变量的第三个位置,这意味着现在它指向索引为2的槽,而不管EntryPointContract中的id 状态变量名。
contract DelegateContract {
address public owner;
// 注意:两个变量换了位置
uint256 public updatedAt;
uint256 public id;
function setValues(uint256 _newId) public {
id = _newId;
}
}
contract EntryPointContract {
address public owner = msg.sender;
uint256 public id = 5;
uint256 public updatedAt = block.timestamp;
address delegateContract;
constructor(address _delegateContract) {
delegateContract = _delegateContract;
}
function delegate(uint256 _newId) public returns(bool) {
(bool success, ) =
delegateContract.delegatecall(abi.encodeWithSignature("setValues(uint256)",
_newId));
return success;
}
}现在 ,如果我用一个新的id值15再次调用delegate,会发生什么?
让我们看看...
DelegateContract被部署在:0x2eD309e2aBC21e6036584dD748d051c0a6E03709
我们可以用Remix来分析它:
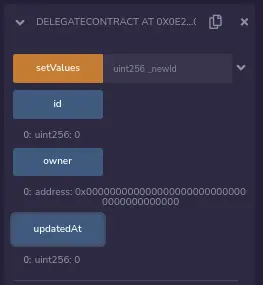
EntryPointContract被部署在: 0x172443F1D272BB9f6d03C35Ecf42A96041FabB09
我们可以用Remix检查它的值:
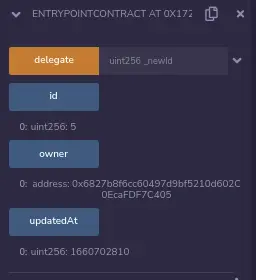
很好!
现在让我们 用参数 15调用delegate,看看会发生什么。
检查一下DelegateContract的状态变量值:
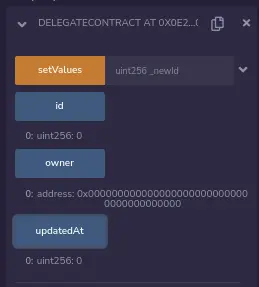
没有变化,正如预期的那样,因为它不应该改变自己的状态,因为它被委托了EntryPointContract的状态。
让我们检查一下EntryPointContract的状态变量值(记住,我们希望id现在是15,其他都保持不变)。
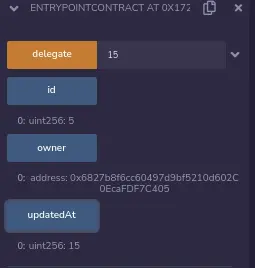
哦哦! EntryPointContract的id仍然是5,实际受到影响的状态变量是updatedAt。为什么?
正如我在上面解释的,DelegateContract实际上不是通过名字来修改状态变量,而是通过它们在存储中的声明位置。
我们知道,id状态变量在EntryPointContract中被声明在第二位,这意味着它将在存储中占据索引为1的槽。updatedAt在EntryPointContract中被声明为第三位,因此占据了索引为2的存储槽。但是我们看到,DelegateContract将id变量声明为第三位,而将updatedAt声明为第二位。所以,当DelegateContract试图修改id时,它实际上是在修改EntryPointContract存储槽的索引2,也就是updatedAt状态变量在EntryPointContract中的位置。这就是为什么我们看到updatedAt是被更新的,而不是id。
让我们来详细说明一下:
EntryPointContract存储显示了声明的状态变量的顺序和它们的值。

EntryPointContract存储“发送到”(委托的)DelegateContract,按照DelegateContract中声明的顺序显示状态变量,但按照EntryPointContract状态变量的声明顺序显示数值:

所以,我们清楚地看到,在DelegateContract中,id变量实际上是指向EntryPointContract存储中的updatedAt值,而DelegateContract的updatedAt值实际上是指向id变量在EntryPointContract存储中有其值的槽。
所以,这就是为什么我们在委托调用另一个合约时需要非常小心的原因,因为拥有相同的变量类型和名称并不能确保调用合约中的这些变量会被使用。它们需要在两个合约中以相同的顺序声明。
另一个有趣的事实是,委托合约可以比主合约有更多的状态变量,有效地将值添加到主存储区,但它不能直接访问,因为主合约没有一个变量指向该存储区。
让我们看看这些合约,以便更清楚理解:
contract DelegateContract {
address public owner;
uint256 public id;
uint256 public updatedAt;
address public addressPlaceholder;
uint256 public unreachableValueByTheMainContract;
function setValues(uint256 _newId) public {
id = _newId;
unreachableValueByTheMainContract = 8;
}
}
contract EntryPointContract {
address public owner = msg.sender;
uint256 public id = 5;
uint256 public updatedAt = block.timestamp;
address public delegateContract;
constructor(address _delegateContract) {
delegateContract = _delegateContract;
}
function delegate(uint256 _newId) public returns(bool) {
(bool success, ) =
delegateContract.delegatecall(abi.encodeWithSignature("setValues(uint256)",
_newId));
return success;
}
}我们看到,EntryPointContract仍然声明了4个状态变量,而DelegateContract声明了5个。我们知道,当EntryPointContract委托调用DelegateContract时,它将把自己的存储发送到DelegateContract.,但是EntryPointContract没有第五个状态变量(unreachableValueByTheMainContract)。那么,当DelegateContract修改它声明的但EntryPointContract没有声明的第五个变量时会发生什么?
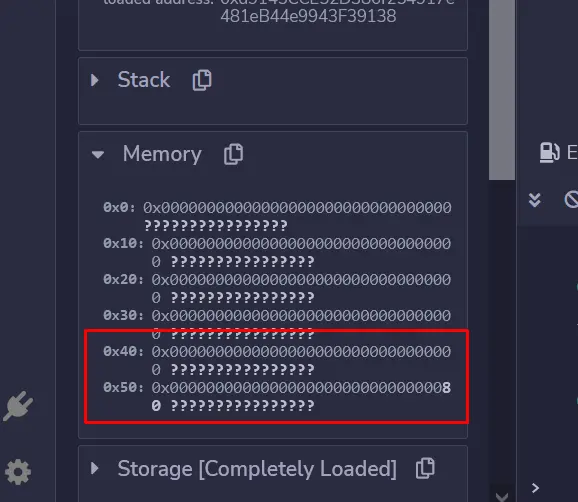
嗯,它实际上会修改EntryPointContract存储的槽索引4(第五个位置)。EntryPointContract将不能直接访问它,因为该槽没有对应声明的状态变量,但该值将在那里,我们可以用web3.eth.getStorageAt(entryPointContractAddress, 4)这样的方法来访问它。
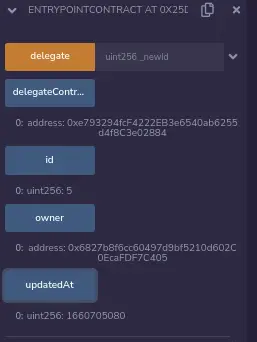
EntryPointContract被部署在0xA80a6609e0cA08ed3D531FA1B8bbCC945b8ff409,我们看到它的值:
现在让我们调用delegate,其值为18:
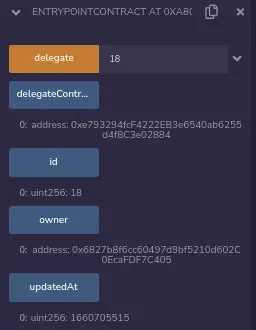
棒极了! 但是设置为unreachableValueByTheMainContract的值8在哪里呢?让我们看看它是否在 DelegateContract 状态下。
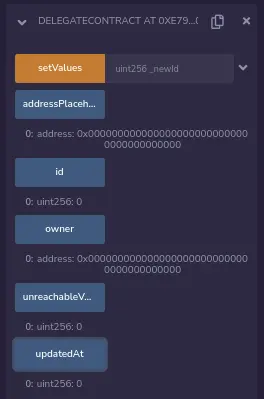
可以看到,它没有值。因为DelegateContract没有修改自己的状态,即使状态变量没有在EntryPointContract中声明。但由于unreachableValueByMainContract状态变量被声明在第五个位置(存储槽索引4),那么它无论如何都会影响EntryPointContract索引4的存储槽。我们可以直接检查它的值:
web3.eth.getStorageAt("0xA80a6609e0cA08ed3D531FA1B8bbCC945b8ff409", 4)返回:
0x0000000000000000000000000000000000000000000000000000000000000008是的! 说明EntryPointContract 确实保存了这个数据。
这是一种有趣的方式,即智能合约可以在部署后被 "扩展",只需在第一时间将其行动委托给另一个合约。这需要精心制作和设计。委托合约的地址需要能够在需要时被动态替换,这样入口点合约就可以在任何时候指向一个新的实现。
有一些方法可以解决这个问题,其中之一就是EIP-1967: Standard Proxy Storage Slots。
结论
delegatecall是一个强大但棘手的功能,如果使用得当,我们可以创建 可扩展 的智能合约,帮助我们修复漏洞,并为现有的智能合约增加新的功能,使其动态地将其行动委托给另一个合约并由其修改自己的状态。
我们需要牢记代理合约和执行合约中的状态变量的顺序,以避免对存储数据进行非预期的修改。