背景
智能合约部署在区块链上,它们是包含一些逻辑的代码片段,由EVM执行,将以太坊区块链变成一种世界分布式计算机。
智能合约可以被链下用户/程序调用,向区块链提交交易。链上的合约之间也可以通过调用对方的方法进行交互(不过是在链下调用之后,智能合约不能 "主动触发" 调用)。
智能合约的交互必须遵循ABI规范,这是一套规则和定义,用于规范以太坊生态系统中的智能合约通信。
在这篇博客中,我将以简化的方式介绍,根据ABI规范,必须如何提交数据给区块链,以触发智能合约。然后,我将谈论用不同方法从链下和链上调用智能合约函数。
介绍
在我们开始之前,我将简单地说明我将在这篇博客中使用哪些工具。
对于链下实体,我将使用web3 javascript库(web3.js),因为它封装了JSON-RPC协议,这是用于与区块链通信的实际协议。, 也可以使用其他相同目的的库库,如:ethers.js,不过语法可能会有所不同。
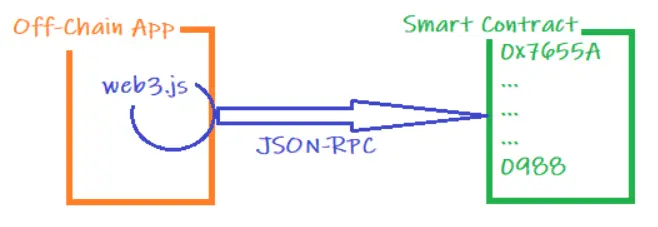
对于链上智能合约,我将使用solidity语言,但任何其他EVM兼容的编程语言也可以。
ABI规范
ABI规范指出了在调用智能合约函数时如何构建发送到 "交易"中作为 "data" 的字节数据。字节数据包含2个主要部分:
- 函数选择器:前4个字节。它们表明被调用的智能合约的确切函数。函数选择器是通过计算函数签名的哈希值(keccak256)获得的(函数名称及参数类型 "func1(bool,uint256,address) "),然后简单地提取其前4个字节。可能会出现一些函数碰撞,因为我们只是使用4个字节,但可能性非常小...
- 参数编码:从第5个字节开始,我们必须按照函数签名中指定的顺序添加作为输入参数传递的编码参数。有两种类型的参数,静态参数(值数据类型,如bool,unit256,...)和动态参数(引用数据类型,如数组,...)。静态参数需要32个字节(在方法签名所指示的位置),它们包含参数的值(必要时用0填充)。动态参数则以不同的方式编码。先预留32个字节(在方法签名所指示的位置)表示实际包含参数值的位置(作为从编码的参数部分开始计算的字节偏移),在指定的位置上,前32个字节表示参数的长度(它包含多少个值),然后列出实际的值。
示例 1
- 函数: baz(uint32 val, bool check) 返回 bool
- 函数签名 : baz(uint32,bool)
- 调用 : baz(69, true) 时,ABI 规范编码数据为:

- 橙色字节 = 函数选择器,keccak256("baz(uint32,bool)")的前4个字节。
- 蓝色字节 = 第一个编码参数,它是一个静态参数,值为 "69"(0x....45)。
- 红色字节 = 第二个编码参数,它是一个值为 "true"的静态参数(0x....01)。
示例 2
- 函数 : sam(bytes name, bool check, uint256[] ids)
- 函数签名 : sam(byte,bool,uint256[])
- 调用 : sam("dave", true, [1,2,3]) 时,ABI 规范编码数据为:
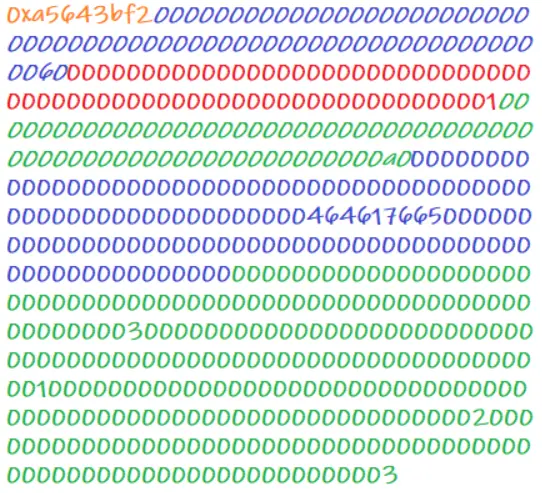
- 橙色字节=函数选择器, keccak256("sam(bytes,bool,uint256[])") 的前4个字节。
- 蓝色字节=第一个编码参数,它是一个动态的参数,首先表明它的位置(字节0x60)。然后在位置0x60上,第一个字节表示长度(0x.....04 = 4字节,因为数据类型是字节),第二个字节表示参数的实际值: "dave" (0x646176650.........0)。
- 红色字节=第二个编码参数,它是一个静态参数,值为 "true"(0x....01)。
- 绿色字节=第三个编码参数,它是一个动态参数,首先指示它的位置(字节0xa0)。然后在位置0xa0上,第一个字节表示长度(0x....03 = 3个字,因为它是一个uint256数组),然后三个字节表示值: "1"、"2"、"3"(0x.....01, 0x....02, 0x......03)。
链下到链上的通信
你有一个前端或后端应用程序,需要与一些以太坊智能合约交互。我将使用javascript的web3.js库,它将处理JSON-RPC协议,也会生成必须提交给区块链的符合abi规范的字节串。
有两种可能的情况,你要么有智能合约JSON ABI,要么没有。
有智能合约JSON ABI
智能合约JSON ABI是一个JSON文件,在你构建智能合约时由solidity编译器生成。编译器实际上会生成两个文件:
- ByteCode: 将被部署在区块链上的操作码(EVM操作)和来自 "构造函数 "函数的操作码(如果存在的话),在部署智能合约时只执行一次,为字节格式。
- JSON ABI: 一个json数组,包含与你的智能合约相关的 public 和 external函数、事件和错误的列表。每个函数、事件和错误都是数组中的一个json对象,它们包含所有必要的信息,以便链下实体与合约交互。
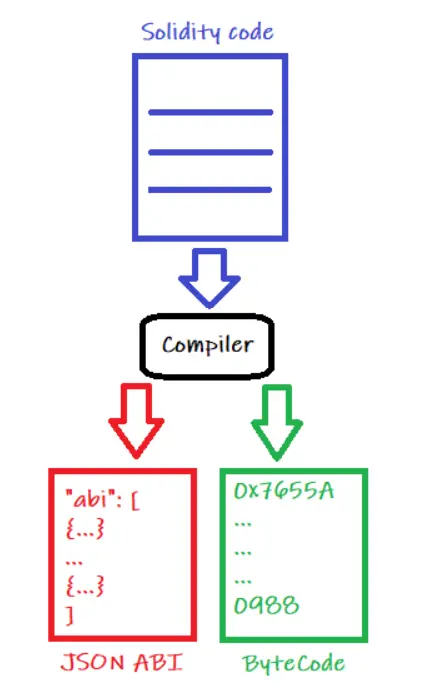
JSON ABI对象包含以下信息:
函数对象:
- Type(类型) : 表示函数的类型,选项有 "function"(用于常规函数)、"receive"、"fallback" 和 "constructor"(用于特殊以太坊函数)。
- Name :函数名称。
- Inputs(参数) :包含每个函数输入参数的名称、类型和组件的对象数组。
- Outputs(返回值) : 就像输入参数一样,但对于函数的输出参数。
- 状态可变性 :函数的可变性:选项是 "view"(只从区块链中读取),"pure"(既不写也不从区块链中读取),"nonpayable"(不能接收以太币)和 "payable"(可接收以太币)。
事件对象:
- Type : 总是 "事件" 。
- Name :事件名称 。
- Inputs : 包含每个事件参数的数组,其名称、类型、组件和(是否有)索引。
- Anonymous : 如果事件被声明为匿名,则为真。
错误对象:
- Type(类型) : 总是 "error"
- Name(名称) :错误名称
- Inputs : 包含每个错误参数的对象数组,其名称、类型和组件。
为了从你的链下应用程序与智能合约进行交互,首先需要导入JSON Abi文件,然后提供JSON Abi和指向智能合约的地址来实例化一个的对象。从那一刻起,你可以像对待其他对象一样直接调用合约的方法。
智能合约的调用将以异步方式完成:
// Reference the smart contract
const SmartContract= require(“SmartContract”);
// Retrieve the JSON ABI and address
const SmartContractAbi = SmartContract.abi;
const SmartContractAddress = "0x......"
// Instantiate an object that "encapsulates" the smart contract
const SmartContractObject = new web3.eth.Contract(SmartContractAbi, SmartContractAddress);
// Now you are ready to interact with the smart contract. Functions // invocations will return promises.
SmartContractObject.methods.func1(…).send({from: …, …}).on(…);
SmartContractObject.methods.func2(…).call({from: …}).on(…);没有智能合约的JSON ABI
如果你没有JSON ABI,你仍然可以与智能合约进行交互,但这将是一个有点麻烦和烦人的过程。
你将不得不自己从方法定义(json格式)、希望提交的输入参数中创建区块链交易,并将其直接发送到智能合约地址。
你可以提交一个 "send"交易(将改变区块链状态的实际交易)或一个 "call" 交易(从以太坊的角度看不是一个实际的交易,因为它将只读取数据)。
交易将以异步方式提交:
// Define the Transaction Data
const TransactionData = web3.eth.abi.encodeFunctionCall({
name: 'myMethod',
type: 'function',
inputs: [{
type: 'uint256',
name: 'myNumber'
},{
type: 'string',
name: 'myString'
}]
}, ['2345675643', 'Hello!%']);
// Now you can either send a transaction or make a call. In both
// cases you will be dealing with Promises
web3.eth.sendTransaction({from: …, to: …, data: TransactionData, …}).on(…);
web3.eth.call({from: …, to: …, data: TransactionData, …}).on(…);链上到链上的通信
你正在实现一个智能合约,想从你的代码中调用另一个合约的函数。可以使用 solidity 编程语言,它提供了一些内置的函数,来生成符合 abi 规范的字节串。
就像链下到链上的情况一样,有两种可能的情况,你要么有智能合约接口,要么没有。
有智能合约接口
如果你有你想调用的智能合约的接口,solidity将为你做大部分的工作。
你只需要将接口导入到智能合约文件,实例化一个接口类型的对象,并传递智能合约地址,你就可以开始了。就可以像其他对象一样调用合约的方法了。
// Import the interface and define the contract object using the
// interface as a data type
import "IContract.sol";
IContract Contract;
// Instantiate the contract with its address
address contractAddress = 0x.......;
Contract = IContract(contractAddress);
// Invoke the contract's methods as defined by the interface
Contract.func1(....);没有智能合约接口
如果你没有合约接口,那么你将不得不构建整个消息。
你将需要合约地址,方法签名(方法名称和输入参数类型用逗号分隔)和你希望提交的参数(也用逗号分隔)。
// Contract Address and function signature
address contractAddress = 0x.......;
string memory Method = “func1(uint256,bool)”;
// Define the abi compliant data
bytes memory AbiData = abi.encodeWithSignature(Method, 345223, true);
// Send the message
(bool success, bytes memory data) = contractAddress.call(AbiData);警告
需要注意的是,不管你与智能合约的交互方式如何,如果你使用的智能合约地址是错误的,你仍然可以提交交易,没有任何的检查。如果智能合约确实有一个与你的调用相匹配的函数,它将被执行,如果没有,那么交易可能失败,也可能成功,如果智能合约有一个 "fallback()" 函数......重点是,后果可能是意想不到的,而且可能是无法检测的,这就是为什么你必须确定你向哪个合约发送交易,始终确保合约地址是正确的。
参考原文: https://medium.com/coinmonks/ethereum-smart-contracts-how-to-communicate-with-them-abi-specification-web3-solidity-db056218b251
转载:https://learnblockchain.cn/article/5090