举个例子,如果你想知道4,000,000区块的以太坊账户余额,那么就需要运行存档节点,然后查询这个数字。这个节点依赖于一些专门的用例,但是对区块链的安全性和信任模型来说其实并没有影响。
您正在查看: Ethereum 分类下的文章
以太坊源码解析:state
本篇文章分析的源码地址为:https://github.com/ethereum/go-ethereum
分支:master
commit id: 257bfff316e4efb8952fbeb67c91f86af579cb0a
引言
对于任何一个区块链项目来说,账户信息的保存都是关键。在以太坊中,保存账户信息的代码是由 state 模块实现的。
与比特币区块链不同的是,以太坊没有使用 UTXO(Unspent Transaction Output) 模型,而是使用的账户余额模型。这篇文章,我们就来看看 state 模块是如何实现账户余额模型的。
什么是 state
要介绍 state,就不得不提区块链的账户模型了。在各个区块链项目中,都会有一个账户地址,类似于我们的银行账户;每个账户都会对应着一些信息,比如有多少币等,类似于我们在银行某个账户下的余额。而保存这些账户对应信息的方式,就是账户模型。
目前在区块链的世界里有两种账户模型:UTXO(Unspent Transaction Output) 模型和账户余额模型。UTXO 的中文翻译为「未花费的交易输出」。这种方式不记录账户余额,只记录每笔交易(一次转账就是一笔交易),账户的余额是通过计算账户的所有历史交易得出的(想像一下如果你知道你老婆/老公的银行账户的每笔交易,那么你就可以算出她/他现在卡还有多少钱了)。(这篇文章里我们不详细讨论 UTXO 模型,感兴趣的读者可以自己搜索相关文章,网上的讲解还是挺多的)。
账户余额模型与我们常用到的银行账户相似,都是保存了我们账户的余额。当有人给我们转账时,就将余额的数字加上转账的值;当我们转账给别人时,就将余额的数字减去转账的值。
这么看来,账户余额模型是比较容易理解的。以太坊使用的就是账户余额模型,而实现这一模型的,正是 state 模块。之所以模块名叫 state,我猜也是因为它就像一个状态机:它记录了每个账户的状态,每当有交易发生时,就更改一下相应账户的状态。
state 模块中主要的对象是 StateDB 对象,正是它记录了每个账户的信息,其中包含 balance(以太币的数量)、nonce(交易标号,见「重放攻击」小节),等信息。这从它的方法中就能看出来,比如:
func (self *StateDB) GetBalance(addr common.Address) *big.Int
func (self *StateDB) AddBalance(addr common.Address, amount *big.Int)
func (self *StateDB) SubBalance(addr common.Address, amount *big.Int)
func (self *StateDB) SetBalance(addr common.Address, amount *big.Int)
func (self *StateDB) GetNonce(addr common.Address) uint64
func (self *StateDB) SetNonce(addr common.Address, nonce uint64)
func (self *StateDB) GetCode(addr common.Address) []byte
func (self *StateDB) SetCode(addr common.Address, code []byte)
......所以,总得来说,以太坊的 state 实现了账户余额模型,保存了以太坊账户的所有信息。每当这些信息发生改变,state 对象就会发生改变,就像一个状态机一样。
实现架构
state 的实现其实比较简单,但由于加了一些缓存功能,乍看上去会觉得比较乱。我画了一张图来示意 state 的主要实现:
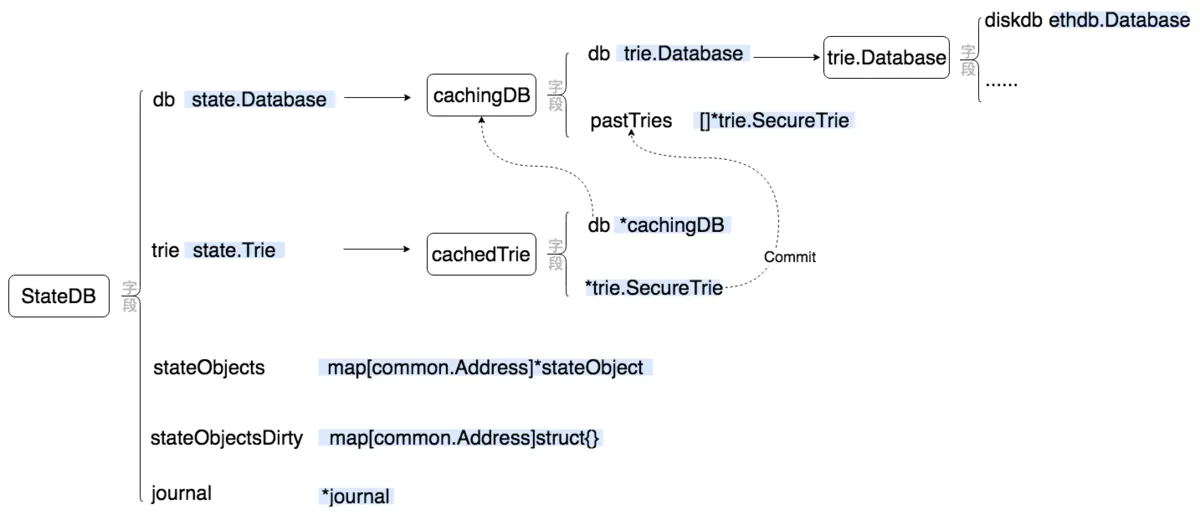
从图上可以看出,state 模块对外的主要对象是 StateDB,这个对象提供了各种管理账户信息的方法(可以很容易地在 state/statedb.go 中查看到,这里就不一一列举了)。在对象的内部主要有四个字段,下面我们分别简单的解释一下这四个字段。
stateObjects 是一个 map,用来缓存所有从数据库(也就是 trie 字段)中读取出来的账户信息,无论这些信息是否被修改过都会缓存在这里。因此在需要将所有数据提交到数据库或 trie 字段代表的 trie 对象时,只需将 stateObjects 中保存的信息提交即可(当然需要借助 stateObjectsDirty 字段踢除没被修改过的信息)。
stateObjectsDirty 很显然是用来记录哪些账户信息被修改过了。需要注意的是,这个字段并不时刻与 stateObjects 对应,并且也不会在账户信息被修改时立即修改这个字段。事实上,这个字段是与 journal 字段相关的:在进行某些操作时(StateDB.Finalise 和 StateDB.Commit)时,才会将 journal 字段中记录的被修改的账户整理到 stateObjectsDirty 中。
journal 字段记录了 StateDB 对象的所有操作,以便用来进行回滚操作。需要注意的是,当 stateObjects 中的所有信息被写入到 trie 字段代表的 trie 树中后,journal 字段会被清空,无法再进行回滚了。
db 字段代表的是一个从数据库中访问 trie 对象的对象,比如 OpenTrie。db 是一个接口类型,但在实际的调用代码中,它只有一个实例就是 cachingDB 这个对象。这个对象是对 trie.Database 的一个包装,通过 pastTries 字段缓存了部分曾经访问过的 trie 对象。这样当下次再次访问这个 trie 时,就不需要从数据库中读取了。这个缓存的功能需要 cachedTrie 对象的配合,在将 trie 提交到数据库的同时通知 cachingDB 进行缓存。
trie 字段也是一个接口类型的字段,它代表了保存账户信息的 trie 对象。在实际调用代码中,它也只有一个实例,就是 cachedTrie 这个对象。这个对象是对 trie.SecureTrie 的一个封装,主要修改是改写了 trie.SecureTrie 的 Commit 方法:在新的 Commit 方法中,除了调用 trie.SecureTrie 的 Commit 方法外,还会与 cachingDB 配合,调用 cachingDB.pushTrie 将当前的 trie.SecureTtrie 缓存到 cachingDB 中。
可以看出代表账户余额模型的对象就是 StateDB 对象,它就像一个 KV 数据库,以账户地址作为 Key、以账户信息作为 Value 进行数据的存储和查询。其底层使用 trie 对象来实现这种类似 KV 结构的数据的存储。而在数据库层面,StateDB 又增加了一些缓存机制,使得运行时效率更高(但也使得代码更复杂一点)。
但不得不说,由于底层使用 trie 对象保存所有数据,StateDB 与 KV 数据库不同的是,在任意时刻或提交数据到数据库(Commit)后,可以得到 trie 对象的哈希值。在生成区块时,这个哈希值是保存在区块头的 Root 字段中的。如此一来,就能随时从数据库中读取任意区块的 state 信息了。
功能解析
了解了 state 模块的整体设计结构以后,其实代码是很容易读懂的。因此我不打算面面俱到的介绍 state 模块的所有功能。在这一节里,我选了几个比较重要的功能,进行简单的介绍。
保存账户信息
前面我们说过,StateDB 就像一个 KV 数据库,底层使用 trie 保存数据。那么到底 K 是什么、 V 是什么呢?
其实要了解 KV 分别是什么,从下面的代码就可以看出来:
func (self *StateDB) getStateObject(addr common.Address) (stateObject *stateObject) {
......
enc, err := self.trie.TryGet(addr[:])
if len(enc) == 0 {
self.setError(err)
return nil
}
var data Account
if err := rlp.DecodeBytes(enc, &data); err != nil {
return nil
}
......
}很明显,所谓的 Key 就是账户地址,Value 就是一个 Account 对象。它的定义如下:
type Account struct {
Nonce uint64
Balance *big.Int
Root common.Hash // merkle root of the storage trie
CodeHash []byte
}因此每个账户中,都包含了四个信息:代表账户操作编号的 Nonce,代表账户余额的 Balance,代表数据存储 trie 哈希的 Root,和代表合约代码哈希的 CodeHash。我们会在介绍以太坊合约时再介绍 Root 和 CodeHash 字段代表的含义;关于 Nonce 的意义,参看本篇文章中的「重放攻击」小节。
可以看到,所谓的余额模型真的非常简单,就是用 Balance 字段记录当前余额就可以了。在矿工生成一个新的区块时,会处理所有的交易和合约。如果涉及到A账户给B账户转账的操作,就从A的账户中减去交易数值,然后给B账户加上同一数值。当所有交易处理完成后,这些交易引起的 StateDB 的变化使其内容的 trie 对象生成了新的 root 哈希;矿工将这个啥希记录到区块的 header 中。这样当别人收到这个区块时,可以重复这一过程,如果得到的 StateDB 的哈希与区块头中记录的哈希一致,则交易验证成功,说明这个区块的交易是正确的。
重放攻击
我们知道,以太坊中的转账是通过一个个交易完成的。现在设想这样一个场景:A 给 B 发起了一笔转账交易,这次交易被所有矿工确认为合法的,因此转账成功;这时候 B 机灵一动,突然想到这笔交易既然之前被认定为合法的,那再次把这笔交易发给矿工,应该还是合法的吧?毕竟交易本身的数据没有变过。所以 B 把之前 A 发起的这笔交易找出来,又重新发到了网络上。这就是重放攻击。如果没有预防措施,那么 B 就可以用这个交易不断地把 A 的钱转给自己。
在以太坊中,防止重放攻击的任务正是由前面提到的 Account 结构中的 Nonce 字段完成的。具体来说,以太坊中每笔交易中都需要记录一个发起账户的 nonce 值:
type Transaction struct {
data txdata
......
}
type txdata struct {
AccountNonce uint64 `json:"nonce" gencodec:"required"`
......
}一笔交易就是由 Transaction 结构代表的,而 txdata 结构中的 AccountNonce 就是 Account.Nonce 的值。在构造一笔交易时,发起者需要将 txdata.AccountNonce 字段设置为发起账户的 Account.Nonce 值加 1。
在矿工出块进行验证时,会对 Transaction 中的 AccountNonce 值进行验证,如果这个值确实比发起者账户的 Account.Nonce 值大 1,则为有效的;否则这个交易目前是无效的(如果 txdata.AccountNonce 与 Account.Nonce 的差 > 1,说明这笔交易可能以后会生效,就暂时保留;如果这个差 < 1,则直接丢弃这个交易)。
除了验证 Transaction 与 Account 的 nonce 值,还需要在 Transaction 结构整体验证成功、转账完成后,将发起账户的 Account.Nonce 值加 1。这样才能在使用这笔交易发起重放攻击后,让这种攻击失效。
可以看到,Account.Nonce 主要功能就是用来避免重放攻击。但这需要代表交易的 Transaction 结构和矿工的配合,即 Transaction 中有 AccountNonce 字段记录着此次转账完成后账户的 Account.Nonce 值应该是多少;而矿工需要验证这个值,且在转账完成后修改账户的 Account.Nonce 值。
快照与回滚
在 StateDB 的实现中,还有快照与回滚的功能,这两个功能主要是由下面两个方法提供的:
func (self *StateDB) Snapshot() int {
id := self.nextRevisionId
self.nextRevisionId++
self.validRevisions = append(self.validRevisions, revision{id, self.journal.length()})
return id
}
func (self *StateDB) RevertToSnapshot(revid int) {
// 根据快照 id,从 validRevisions 中查找快照信息
idx := sort.Search(len(self.validRevisions), func(i int) bool {
return self.validRevisions[i].id >= revid
})
if idx == len(self.validRevisions) || self.validRevisions[idx].id != revid {
panic(fmt.Errorf("revision id %v cannot be reverted", revid))
}
snapshot := self.validRevisions[idx].journalIndex
// 恢复快照
self.journal.revert(self, snapshot)
self.validRevisions = self.validRevisions[:idx]
}StateDB.Snapshot 方法创建一个快照,返回一个 int 值作为快照的 ID。StateDB.RevertToSnapshot 用这个 ID 将 StateDB 的状态恢复到某一个快照状态。
这两个方法的实现都很简单,从中可以看出,StateDB.nextRevisionId 字段用来生成快照的有效 ID,而 StateDB.validRevisions 记录所有有效快照的信息。关键实现其实在 StateDB.journal 字段中,这个字段的类型是 journal 结构。我们详细看一下这个结构的实现。
journal 结构在 state/journal.go 中,它的定义如下:
type journal struct {
entries []journalEntry // Current changes tracked by the journal
dirties map[common.Address]int // Dirty accounts and the number of changes
}其中 entries 字段的类型是 journalEntry 类型的数组,journalEntry 是一个接口类型,主要方法就是用来恢复数据的 revert 方法,它代表了对某一操作进行回滚的操作,因此实现了 journalEntry 接口的对象有很多个,我把它们罗列在这里:
type createObjectChange struct
type resetObjectChange struct
type suicideChange struct
type balanceChange struct
type nonceChange struct
type storageChange struct
type codeChange struct
type refundChange struct
type addLogChange struct
type addPreimageChange struct
type touchChange struct可以看到这些代表具体回滚操作的对象,对应了所有对 StateDB 的操作。每当有对 StateDB 的操作时,就会构造一个对应的回滚操作并调用 journal.append 方法将其加入到 journal.entries 中。比如对于增加余额的操作:
func (self *StateDB) AddBalance(addr common.Address, amount *big.Int) {
stateObject := self.GetOrNewStateObject(addr)
if stateObject != nil {
stateObject.AddBalance(amount)
}
}
func (c *stateObject) AddBalance(amount *big.Int) {
......
c.SetBalance(new(big.Int).Add(c.Balance(), amount))
}
func (self *stateObject) SetBalance(amount *big.Int) {
// 构造 SetBalance 的回滚操作 balanceChange 并加其记录到 `journal.entries` 中
self.db.journal.append(balanceChange{
account: &self.address,
prev: new(big.Int).Set(self.data.Balance),
})
self.setBalance(amount)
}journal.append 的实现很简单直接:
func (j *journal) append(entry journalEntry) {
j.entries = append(j.entries, entry)
if addr := entry.dirtied(); addr != nil {
j.dirties[*addr]++
}
}这样,journal.entries 中积累了所有操作的回滚操作。当调用 StateDB.RevertToSnapshot 进行回滚操作时,就会调用 journal.revert 方法:
func (j *journal) revert(statedb *StateDB, snapshot int) {
for i := len(j.entries) - 1; i >= snapshot; i-- {
// Undo the changes made by the operation
j.entries[i].revert(statedb)
// Drop any dirty tracking induced by the change
if addr := j.entries[i].dirtied(); addr != nil {
if j.dirties[*addr]--; j.dirties[*addr] == 0 {
delete(j.dirties, *addr)
}
}
}
j.entries = j.entries[:snapshot]
}在 journal.revert 中,会从 journal.entries 中最后一项开始、向前至参数中指定的项,调用它们的 revert 方法。我们以 balanceChange 为例看看这些回滚对象是如何操作的。刚才提到过在修改 balance 的 stateObject.SetBalance 中会构造一个 balanceChange 对象:
func (self *stateObject) SetBalance(amount *big.Int) {
// 构造 SetBalance 的回滚操作 balanceChange 并加其记录到 `journal.entries` 中
self.db.journal.append(balanceChange{
account: &self.address,
prev: new(big.Int).Set(self.data.Balance),
})
self.setBalance(amount)
}其中 balanceChange.prev 字段保存了修改之前的 balance 值。那么在 balanceChange.revert 中就将这个值重新恢复到账户信息中就行了:
func (ch balanceChange) revert(s *StateDB) {
s.getStateObject(*ch.account).setBalance(ch.prev)
}注意这里调用的是 stateObject.setBalance 而不是 stateObject.SetBalance,后者会再次将修改加入到 journal 中,这并不是我们想要的操作。
现在我们可以总结一下 state 模块是如何实现快照和回滚功能的:
- 将所有可能的修改作一个统计。
- 实现所有可能操作对应的回滚操作对象。
- 在每次进行操作前,将对应的回滚对象加入到回滚操作的数组中,例如 journal.entries。
- 要在当前状态下创建一个快照,就记录下当前 journal.entries 的长度(因为 journal.entries 中一个数组)。
- 要恢复某个快照(即实现回滚操作),就从 journal.entries 中最后一项开始,向前至指定的快照索引,逐一调用这些对象的 revert 操作。
其实还是挺简单的,我们日常开发中要实现类似的功能,也可以参考这个实现方式。
要注意一点的是快照与回滚只能针对还未提交到数据库中的账户信息,即存在于 stateObject 中的信息。如果已经被提交到数据库中,就无法回滚了。(其实要想实现也是可以的,只是以太坊的代码没有这么实现而已)
总结
在这篇文章里,我们介绍了以太坊的 state 模块。 state 模块实现了以太坊的账户余额模型,它以一种类似 KV 数据库的形式存储账户信息,其中以账户地址作为 Key,以账户信息(Account 结构)作为 Value。它的底层使用 trie 对象对数据进行存储,这样不但可以快速获取某一账户的信息,还可以得到 trie 的 root 哈希保存到区块头中,这样矿工生成区块后,别的节点就可以重现交易对账户的修改,并将最终的保存账户信息的 trie 的 root 哈希与区块头中保存的哈希进行比较,方便对区块进行验证。
以上就是对 state 模块的所有分析。水平有限,如果有错误还请留言或邮件指出,非常感谢。
什么是以太坊eth伦敦升级?会带来哪些改变?
在过去数月里,以太坊核心开发者一直在进行伦敦网络升级的工作。它是继柏林升级(四月在主网实现分叉)后的一次升级。尽管各个网络的升级区块高度目前还未定,但纳入伦敦升级的 EIP 已经确定了。根据升级规范,EIP 如下:
➤ EIP-1559: Eth1.0 费用市场变更
➤ EIP-3198: BASEFEE 操作码
➤ EIP-3529: 减少gas返还
➤ EIP-3541: 拒绝以 0xEF 字节开头的新地址
➤ EIP-3554: 难度炸弹延迟至 2021 年 12 月
现在看看每个 EIP 的详细内容吧!
EIP-1559: Eth1.0 费用市场变更
EIP-1559 是以太坊史上最令期待的变更之一,也是伦敦升级里带来最大变更的EIP。这份 EIP 将在网络区块里引入“基本费用 (basefee)",它会追踪 gas 价格,这些价格来自网络将接受的、基于对区块空间需求的交易。这意味着钱包和用户将可以更容易预测他们交易的价格。另外,EIP-1559 新增了一种交易类型,用户可以指定他们愿意支付的最高限额,当他们把这个最高限额费用发送给矿工时,会获得最高限额费用减去基本费用与矿工小费之和的差值退款。最后,这份 EIP 还将导致部分交易费被烧毁,这一点被社区的大部分人认为是以太坊网络经济上的一个重要改善举措。
一篇简单的文章难以涵盖EIP-1559 的机制、裨益与影响。这份清单汇总了这份 EIP 各方面内容。还有关于 EIP-1559 的一期 PEEPanEIP, 这是完整视频。
EIP-3198: BASEFEE 操作码
这份 EIP 是与 EIP-1559 搭配的。它只是简单添加了一个BASEFEE操作码,它返回的是执行交易所在的区块的基本费用。这将使得智能合约可以在链上访问这个值,这有助于提交欺诈证明和创建去信任的 gas 价格衍生品。通过这期由Ratan Rai Sur 主讲的 PEEPanEIP,读者可以对这份 EIP 有一个全面的认识。
EIP-3529: 减少 gas 返还
在伦敦引入的另一个重大变更是取消了操作码SELFDESTRUCT 的 gas 返还和减少了操作码 SSTORE 的 gas 返还。虽然设立返还的初衷是希望激励开发者在可能的情况下清除状态,然而现实是,这导致了Gas Token的出现,反而增加了状态大小。利用这些返还的 gas,Gas Token 可以在 gas 价格很低的时候填满状态,然后在 gas 价格上升的时候获得执行这些交易的返还。
除此外,gas 返还还会导致区块执行时间的变化。在伦敦升级之前,多达 50% 的返还 gas 可以在同一个区块里进一步执行计算。也就是说,在实际上,最大的区块容量可达 1.5 倍的 gas limit。EIP-2539 把"执行 gas 返还"从 50% 下调到最多 20%。这一变更将有助于抵消由 EIP-1559 引入的额外区块大小变化,因为 EIP-1559 允许区块使用的 gas 是现在 gas limit 的两倍。
EIP-3541: 拒绝以 0xEF 字节开头的新地址
EIP-3541 是一个简单的变更,为以后更广泛的 EVM 改善奠定基础,想看 EIP-3540。这份 EIP 将使得以 0xEF 比特开头的新合约无法部署。现有的合约将不受影响。主网进行伦敦升级后,以 0xEF 开头的最短字节序列与现有合约的开头序列并不匹配,它们可以保留作为识别与 EIP-3540 语义相符的合同的方式。请注意:EIP-3540 将要求一次额外的网络升级来部署。值得注意的是,如果 EIP-3540 从未被部署,EIP-3541保留下来的开头字节也在其他方案里使用。
EIP-3554:2021难度炸弹延迟至2021年12月
EIP-3554 延迟难度炸弹,也以冰河时代为人所知。难度炸弹或冰河时代是以太坊引入的一种机制,在网络过渡到权益证明时”冻结“挖矿。由于权益证明的过渡还未准备好,我们需要推迟炸弹的”爆炸“时间。这在过去已经进行过三次:在大都会(EIP-649)、君士坦丁堡 (EIP-1234) 和穆尔冰川 (EIP-2384)。
尽管之前的延迟时间都相当长,但这次核心开发者选择了较短时间的延迟,把难度炸弹推迟到2021年12月。到时,网络不是要进行到权益证明的过渡就是另一次网络升级。
这就是纳入伦敦升级的整个变更列表了。测试网的升级区块高度和相关的客户端发布版本很快会在以太坊基金会博客上发布。
Transaction gasPrice (0) is too low for the next block, which has a baseFeePerGas of
问题描述
为了对比数据方便,排除发起交易gas消耗引起的账户余额差别,会将hardhat test 脚本中设置发起交易,设置gasPrice:0
await contract.withdraw({from: accounts[15], gasPrice: 0})执行hardhat test时报以下错误
Transaction gasPrice (0) is too low for the next block, which has a baseFeePerGas of 8解决方案
hardhat-config.js中设置initialBaseFeePerGas: 0
networks: {
hardhat: {
...
initialBaseFeePerGas: 0
}
}参考
https://github.com/nomiclabs/hardhat/issues/1216
https://github.com/nomiclabs/hardhat/blob/8e219bfc4112488953508eddd826d537bc71e803/docs/hardhat-network/reference/README.md
了解 Geth 客户端:快照加速机制
本文为 Geth 客户端有问必答系列的第一篇文章,大家可以就 Geth 客户端的问题踊跃提问,我会每周用一篇小文章回答得票最高的问题。本周呼声最高的问题是:你能说说 flat 数据库结构与 legacy 结构的主要区别吗?
以太坊的状态
在深入了解加速结构(acceleration structure)之前,我们先回顾一下以太坊的 “状态” 概念、在涉及到不同层次的抽象时又是如何存储的。
以太坊有两种不同类型的状态:账户的集合;每一合约账户存储槽的集合。从 完全抽象的角度 来看,两种数据都是 键-值 对。账户集合把地址映射到该地址的 nonce、余额,等等。而一个合约的存储领域把任意的值(由该合约定义并使用)映射到某个值。
但糟糕的是,虽然把这些键值对存储成扁平数据(flat data)可以非常高效,但验证它们的正确性在计算上就会变得很难。每当对数据修改时,我们都要自下而上对所有数据做哈希运算。
为免去总是对整个数据库做哈希运算的需要,我们可以把数据库分割成连续的小片,然后建立出一种树状结构!最原始、最有用的数据就放在叶子节点上,然后树上每一个内部节点都是该节点以下内容的哈希值。如此一来,当我们要修改某些值时,就只需做对数次的哈希运算。这种数据结构其实有一个路人皆知的名字,就是 “默克尔树”。
但还没完,这种办法在计算复杂性上还是有所欠缺。默克尔树结构虽然在修改现有数据时非常高效,但是,如果插入数据和删除数据会更改底层小数据块的边界,那就会让所有已经算好的哈希值全都变为无效。
这时候,与其盲目地对数据库分组,我们可以使用键本身来组织数据、基于共同前缀将数据都安排到树状格式中!这样插入和删除操作都不会影响到所有节点,只会影响到从树根到叶子路径上的(对数个)节点。这种数据结构就叫 “帕特里夏树”。
把上面两种办法合在一起 —— 帕特里夏树的树状分层和默克尔树的哈希算法 —— 就是所谓的 “默克尔-帕特里夏树”,也是实践中用于代表以太坊状态的数据结构。无论是修改、插入、删除还是验证,都只有对数复杂度!唯一的小小例外是,有些键会在插入前做哈希运算(存入树中),以平衡整棵树(A tiny extra is that keys are hashed before insertion to balance the tries)。
以太坊的状态存储
上文解释了为什么以太坊要用默克尔帕特里夏树结构来存储其状态。遗憾的是,虽然所需操作的速度都很快,但每一种选择都有所牺牲。更新操作和验证操作的对数复杂性 意味着对 每一个单独的密钥 的读取和存储都是对数复杂的(logarithmic reads and logarithmic storage)。这是因为树状结构的每一个内部节点都要单独保存在硬盘上。
此时此刻,账户树的深度确切是多少我不知道,但在大约一年以前,账户状态就已填满了 7 层高的树。这就意味着,每一次树操作(例如读取余额、写入 nonce)都要触达至少 7~8 个内部节点,因此会做至少 7~8 次持久数据库访问(persistent database accesses)。LevelDB 组织数据时最多也是 7 层,所以还有一个额外的乘数。最终的结果是,单次 状态访问预计会放大为 25~50 次随机的 硬盘访问。你再乘上一个区块中的所有交易的所有状态读取和写入,你会得到一个 吓人 的数字。
[当然,所有客户端实现都在尽力降低开销。Geth 使用更大的内存区域来缓存树节点;还使用了内存内的修剪机制、避免将几个块之后就会删除的数据写入硬盘。不过这需要另外一篇文章才能讲清楚。]
可怕之处还在于,这个数字就是运行一个以太坊节点、保证能全时验证所有状态的成本。
我们能做得更好一点吗?
并不是所有访问都要一视同仁
以太坊的运行依赖于对状态的密码学证明。只要我们还想保持对所有数据的验证能力,就绕不开硬盘读写放大问题。也就是说,我们 —— 可以并且也事实上 —— 相信我们已经验证过的数据。
不断重复验证每一个状态物是没有意义的,但如果每次从硬盘中拉取数据都要验证一次的话,就是在做这样没有意义的事。默克尔帕特里夏树结构本质上是为写入操作设计的,但反过来就成了读取操作的负担。我们摆脱不了它,也无法让它瘦身,但 这绝不意味着 我们在每一个场合都必须使用它。
以太坊节点访问状态的场景可大致分为以下三类:
- 在导入一个新区块的时候,EVM 代码的执行会产生或多或少基本平衡的状态读取和写入次数。不过,一个用于拒绝服务式攻击的区块可能会产生远多于写入操作的读取操作次数。
- 当节点运营者检索状态的时候(例如调用 eth_call 及类似操作),EVM 代码执行仅产生读取操作(当然也可能有写入操作,但这些操作产生的数据最终会丢弃掉,不会持久化到硬盘里面)。
- 当节点在同步区块链的时候,同步者会向远程节点请求状态,被请求者会将数据挖掘出来并通过网络传播给同步者。
基于上述访问模式,如果我们可以短路(short circuit)读取操作而不触及状态树,则许多节点操作都可以变得快 很多。这样甚至能开启一些新奇的访问模式(比如状态迭代),让原来因为太过昂贵而不可行的模式变为可能。
当然,还是不免有所牺牲。没有去掉树结构,任何新的加速结构都会带来额外的开销。问题只在于:额外的开销是否能带来足够多的好处,值得我们一试?
请循其本
我们已经开发出了神奇的默克尔帕特里夏树结构来解决我们所有的问题,现在,我们希望让读取操作能绕过它。那么,我们应该用什么样的加速结构来让读取操作重新变得快起来呢?显然,如果我们不需要树结构,那就大可以把伴随树结构而生的复杂性都丢在一边,我们可以直接回到原始状态。
如同在本文开头说到的那样,理论上的理想状态下 以太坊状态的数据存储方式应是简单键值对,没了默克尔帕特里夏树构成的限制,那就没有什么能阻止我们去实现这种理想方案了!
不久之前,Geth 引入了 snapshot(快照)加速结构(不是默认开启的)。一个快照就是给定一个区块处的以太坊状态的完整视图。抽象掉实现方面的细节,它就是把所有账户和合约存储槽堆放在一起,都由扁平的键值对来表示。
每当我们想要访问某个账户或者某个存储槽的时候,我们只需付出一次 LevelDB 的查询操作即可,而不用在每棵树上查询 7~8 次。理论上来说,更新快照也很简单,处理完一个区块后,我们只需为每个要更新的存储槽多做 1 次额外的 LevelDB 写入操作即可。
快照加速结构实际上将读取操作的计算复杂性从 O(log n) 降到了 O(1) (乘以 LevelDB 的开销),代价是将写入操作的计算复杂性从 O(log n) 变成了 O(1 + log n) (乘以 LevelDB 的开销),并将硬盘存储空间从 O(n log n) 增加到了 O(n + n log n)。
魔鬼藏在细节中
维持以太坊状态快照的可用性也不容易。只要区块还在一个接一个地产生,一个接一个地摞在最后一个区块上,那将最新变更合并到快照中的粗疏办法就能正常工作。但是,哪怕有微小的区块链重组(即便只有一个区块),快照机制就崩溃了,因为根本没有设计撤销操作。对扁平数据表示模式来说,持久化写入是单向的操作。而且让事情变得更糟糕的是,我们没办法访问更老的状态了(例如某些 dApp 需要 3 个区块以前的状态;或者 fast/snap 同步模式中要访问 64 个区块以前的状态)。
为了克服这些限制,Geth 客户端的快照由两部分组成:一部分持久化的硬盘层,是对旧区块(例如顶端区块前 128 个区块)处状态的完整快照;还有一棵内存内 diff 层组成的树,用于收集最新的写入操作。
处理新区块的时候,我们不会直接合并这些写入操作到硬盘层,而仅仅是创建一个新的、包含这些变更的内存内 diff 层。当内存内部的 diff 层积累到足够高的层数时,最底部的一个就开始合并更新并推到硬盘层。当需要读取一个状态物时,我们就从最顶端的 diff 层开始查找,一直往下,直至在 diff 层中或者在硬盘层中找到。
这种数据表示方法非常强大,解决了很多问题。因为内存内部的 diff 层组成了一棵树,所以 128 个区块以内的链重组只需取出属于父块的 diff 层,然后就此开始构建即可。需要较旧状态的 dApp 和远程同步者可以访问到最近 128 个最近的状态。开销变成了 128 次映射查找,但 128 次内存内的查找比起 8 次硬盘读取及 Level DB 的 4~5 倍放大要快上几个数量级。
当然,这里面还有很多很多的坑。就不讲太深了,简单列举就有下面这张清单:
- Self-destruct (合约自毁操作)(以及删除操作)特别难以对付,因为它们需要短路 diff 层的沉降(descent)。
- 如果出现了比持久硬盘层更深的链重组,那现在的快照就要完全废弃掉、重新生成。整套操作非常昂贵。
- 在节点关机时,内存内的 diff 层需要持久化到日志并加载备份,不然重启之后快照就没用了。
- 使用最底层的 diff 层作为一个累加器,仅在其超过一定的内存使用时才刷新到硬盘。这就允许跨区块对同一存储槽执行去重写入操作(deduping write)。
- 要为硬盘层分配一个读取缓存,这样合约重复访问同一个古老的存储槽时硬盘才不会损坏。
- 在内存内 diff 层中使用累积的布隆过滤器(bloom filter),以便快速检测出状态物有没有可能存在于 diff 层中,还是应该直接跳到硬盘中查找。
- 不把原始数据(账户地址、合约存储键)设为键,而是以这些数据的哈希值为键,以保证快照的迭代顺序与默克尔帕特里夏树相同。
- 生成持久化硬盘层的时间要比剪除状态树窗口的时间多得多,所以即使是生成器,也需要动态地追踪链的运行。
美丑并存
Geth 的快照加速结构将状态读取的复杂性降低了一个数量级。这就意味着基于读取操作的 DoS 攻击的发动难度上了一个数量级,而 eth_call 调用也快了一个数量级(假设 CPU 不存在瓶颈的话)。
快照还让对最近的块进行极速状态迭代成为可能。实际上这曾是我们开发快照机制的主要理由,因为我们可以此为基础创造新的 snap 同步算法。讲清楚它需要一篇全新的文章,但最近我们在 Rinkeby 测试网上的基准测试很能说明问题:

当然,这一切同样不是没有代价的。当初始同步完成之后,参与主网的节点需要 9~10 小时来建构初始快照(此后再维持其可用性),还需要额外的 15 GB 以上的硬盘。
那糟糕的部分是哪里呢?我们花了 6 个月时间才积累起足够的自信、发布了快照机制,而且现在它仍然不是默认功能,需要主动使用 --snapshot 标记来开启,而且还有一些围绕内存使用和崩溃恢复的打磨工作要做。
总而言之,对于这一提升,我们非常自豪。其中有巨大的工作量,而且是在黑暗中摸索、自己实现所有东西并祈祷它能工作。还有一个有趣的事情,第一个版本的快照同步(leaf sync)是在两年半以前写的,但一直都处于被阻塞的状态,因为我们缺乏必要的加速结构来驱动它。
结语
希望你能喜欢 Geth 客户端有问必答 的这一篇文章。我花了比自己所预想的多出一倍的时间,但我并不后悔,因为这个主题值得。下周见。
[又:我故意不在文章里留下 提问/投票 的网站,因为我确信这个活动只是暂时的,我不想留下一个没用的超链接,也不希望有人会在未来买下那个域名并托管恶意信息。你可以在我的 Twitter 中找到那个网站。]
(完)
原文链接: https://blog.ethereum.org/2020/07/17/ask-about-geth-snapshot-acceleration/
作者: Péter Szilágyi
翻译: 阿剑
本文由原作者授权 EthFans 翻译及再出版。
转载自:https://ethfans.org/posts/ask-about-geth-snapshot-acceleration
最新回复
fzd: 请问这个解决了吗
StarkWare explained: layer 2 solution provider of dYdX and iMMUTABLE R11; BitKeep News: [...]Layer 2: https://...
一文读懂 StarkWare:dYdX 和 Immutable 背后的 L2 方案 R11; BitKeep 博客: [...]Layer 2:Comparing Laye...
http://andere.strikingly.com/: Regards, Great stuff!
surou: 需要先执行提案合约申请,等待出块节点地址同意后,才会进...
heco: WARN [11-19|11:26:09.459] N...
P: 你好,我在heco链上遇到了“tx fee excee...
Peng: 楼主安装成功了吗?我正在同步区块链,一天了,差不多才同...
joyhu: 你好,请问下安装好之后如何获取到bee.yaml配置文...
kaka: 支票最终怎么提币呢?
归档
April 2024March 2024January 2024December 2023November 2023October 2023September 2023August 2023July 2023June 2023April 2023March 2023February 2023January 2023December 2022November 2022October 2022August 2022July 2022June 2022May 2022March 2022February 2022January 2022December 2021November 2021October 2021September 2021August 2021July 2021June 2021May 2021April 2021March 2021February 2021January 2021December 2020November 2020October 2020September 2020July 2020June 2020May 2020April 2020March 2020February 2020January 2020December 2019November 2019October 2019September 2019August 2019July 2019June 2019May 2019April 2019March 2019February 2019January 2019December 2018November 2018October 2018September 2018August 2018July 2018June 2018