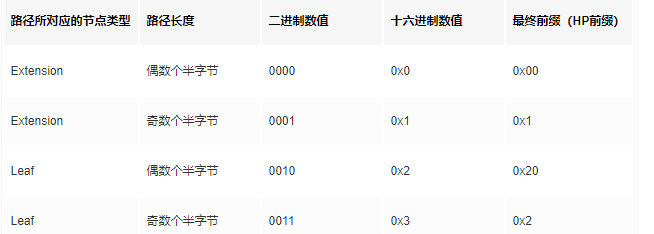
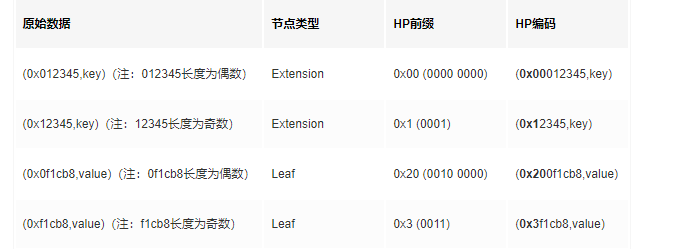
在传统货币理论中存在“不可能三角”,即一国无法同时实现货币政策的独立性、汇率稳定与资本自由流动,最多只能同时满足两个目标,而放弃另外一个目标。
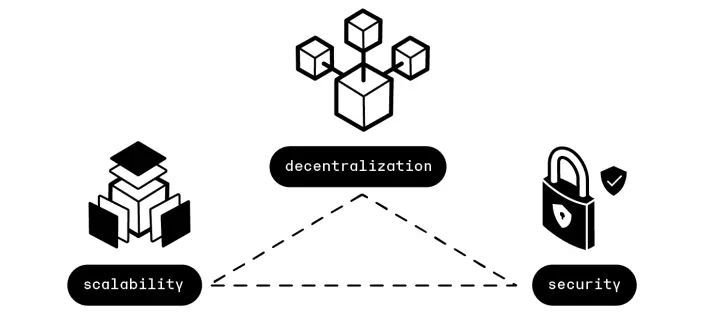
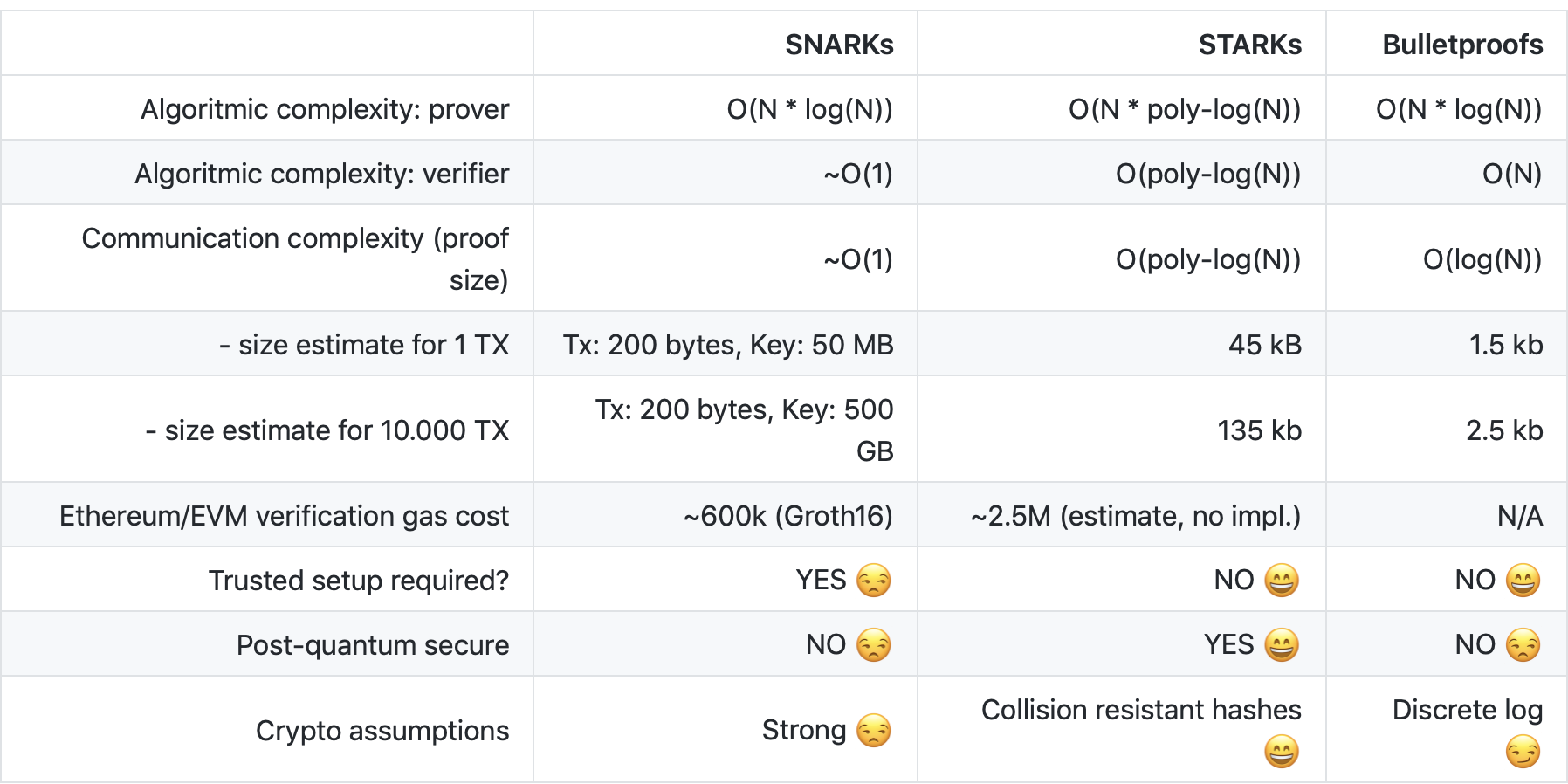
相类似,当前的区块链技术也存在“不可能三角”,即无法同时达到可扩展(Scalability)、去中心化(Decentralization)、安全(Security),三者只能得其二。
- 可扩展性:每秒可以处理大量交易。
- 去中心化:拥有大量参与区块生产和验证交易的节点。
- 安全性:获得网络的多数控制权需要非常高昂的成本。
目前很多区块链会在三者中有所权衡,比如以太坊和比特币比较关心的就是去中心化和安全性。而有一些新公链更注重的是可扩展性和安全性。
从比特币创世开始,一直到以太坊网络中Crypto Kitties游戏的出现。主流公链项目最被人诟病的地方就是低下的TPS,以太坊15左右的TPS完全无法给大多数应用提供实时稳定的支持,这与当前互联网行业动辄上万TPS的业务形成了鲜明的对比。
扩展性也许是排在第一位的问题。扩展性问题已经成为很多系统的坟墓。这是一个重大而艰巨的挑战。-Vitalik Buterin
zk-Rollup
对于以太坊而言,过去几年内关于以太坊扩容的方案不断出现。其主流的方案如下所示:

链上扩容
分片(Sharding)技术
Sharding一词本来源于数据库的术语,表示将大型数据库分割为很多更小的、更易管理的部分,从而能够实现更加高效的交互。区块链分片是指对区块链网络进行分片,从而增加其扩展性。根据最新的以太坊2.0规范,以太坊区块链会被分为1024个分片链,这也意味着以太坊的TPS将提高1000倍以上。但目前Sharding方案仍然在跨分片通信、欺诈识别、随机分配与选举安全性等方面存在不足。
链下扩容
状态通道(State Channel)
指代用于执行交易和其他状态更新的“链下”技术。但是,一个状态通道内发生的事务仍保持了很高的安全性和不可更改性。如果出现任何问题,我们仍然可以回溯到链上交易中确定的稳定版本。
侧链(Sidechain)技术
侧链是平行于主链的一条链,由侧链上的验证者把一条链的最新状态提交给主链上的智能合约,这样持续推进的一类系统。侧链通常使用PoA(Proof-of-Authority)、PoS(Proof of Stake)等高效的共识算法。它的优势在于代码和数据与主链独立,不会增加主链的负担,缺陷在于它的安全性弱、不够中心化,无法提供审查抗性、终局性和资金所有权保证。
Rollup技术
顾名思义,就是把一堆交易卷(Rollup)起来汇总成一个交易,所有接收到这个交易的节点只去验证执行结果,而不会验证逻辑。因此Rollup交易所需Gas费会远小于交易Gas费总和,TPS也增加了。主流的Rollup技术可以分为两类:
zk-Rollup
基于零知识证明的Layer2扩容方案,采用有效性验证方法(VP),默认所有交易都是不诚实的,只有通过有效性验证才会被接受。ZkRollup在链下进行复杂的计算和证明的生成,链上进行证明的校验并存储部分数据保证数据可用性。
Optimistic Rollup
乐观的Rollup协议,采用欺诈证明方法,即对链上发布的所有Rollup区块都保持乐观态度并假设其有效,它仅在欺诈发生的情况下提供证据。乐观Rollup的优势在于能使得原生Layer1上的solidity合约可以无缝移植到Layer2,从而最大程度提升了技术人员的研发体验,目前主流方案包括Optimism和Arbitrum。
Plasma方案
通过智能合约和Merkle树建立子链,每个子链都是一个可定制的智能合约,子链共存并独立运行,从而大幅降低主链的TPS压力。
从中长期来看,随着 ZK-SNARK 技术的改进,ZK rollups 将在所有用例中胜出。— Vitalik Buterin
zkEVM
ZK-Rollup早期为人诟病的地方是不能兼容 EVM,不能支持智能合约功能,例如 Gitcoin 捐赠主要支付途径的 zkSync 1.0 仅能支持转账等基本功能。同时,由于不同 ZK 应用有各种专用电路,无法相互调用,可组合性差。因此市场急需能够支持以太坊智能合约的ZK-Rollup,而其中关键门槛就是能够支持零知识证明的虚拟机。随着引入 EVM 兼容的 zkVM,zk-rollups 才开始支持以太坊 dApps。

Comparison
由于 ZK-EVM 并没有统一的设计标准,所以每个项目方基于不同角度在兼容 EVM 和支持 ZK 之间权衡设计出各自方案,目前基本分为两种思路:
- 编程语言层面支持,自定义 EVM 操作码,把 ZK-friendly 的操作抽出来重新设计新的、架构不同的虚拟机,通过编译器将 Soilidity 编译成新的虚拟机操作码
- 字节码层面支持,支持原生 EVM 操作码
对于第一种策略,由于不受原有 EVM 指令集的约束,可以更灵活的将代码编译成对零知识证明更友好的指令集,同时也摆脱了兼容所有 EVM 原有指令集所需要的艰巨而繁重的工作。
对于第二种策略,由于完全支持了 EVM 现有的指令集,其使用的是和 EVM 一样的编译器,因此天然就对现有的生态系统和开发工具完全兼容,同时还更好的继承了以太坊的安全模型。
第一种思路更灵活,工作量更小,但需要花费额外精力在适配上;第二种思路工作量相对来说会大一些,但是兼容性更好,安全性更高。
Starkware zkEVM
Starkware 的 ZK-Rollup 通用解决方案 StarkNet 可以运行任意的以太坊 dApp。开发者可以通过编译器将 Solidity 编译成 StarkNet 的智能合约语言 Cairo,再部署到其 ZK-friendly 的 VM。
zkSync zkEVM
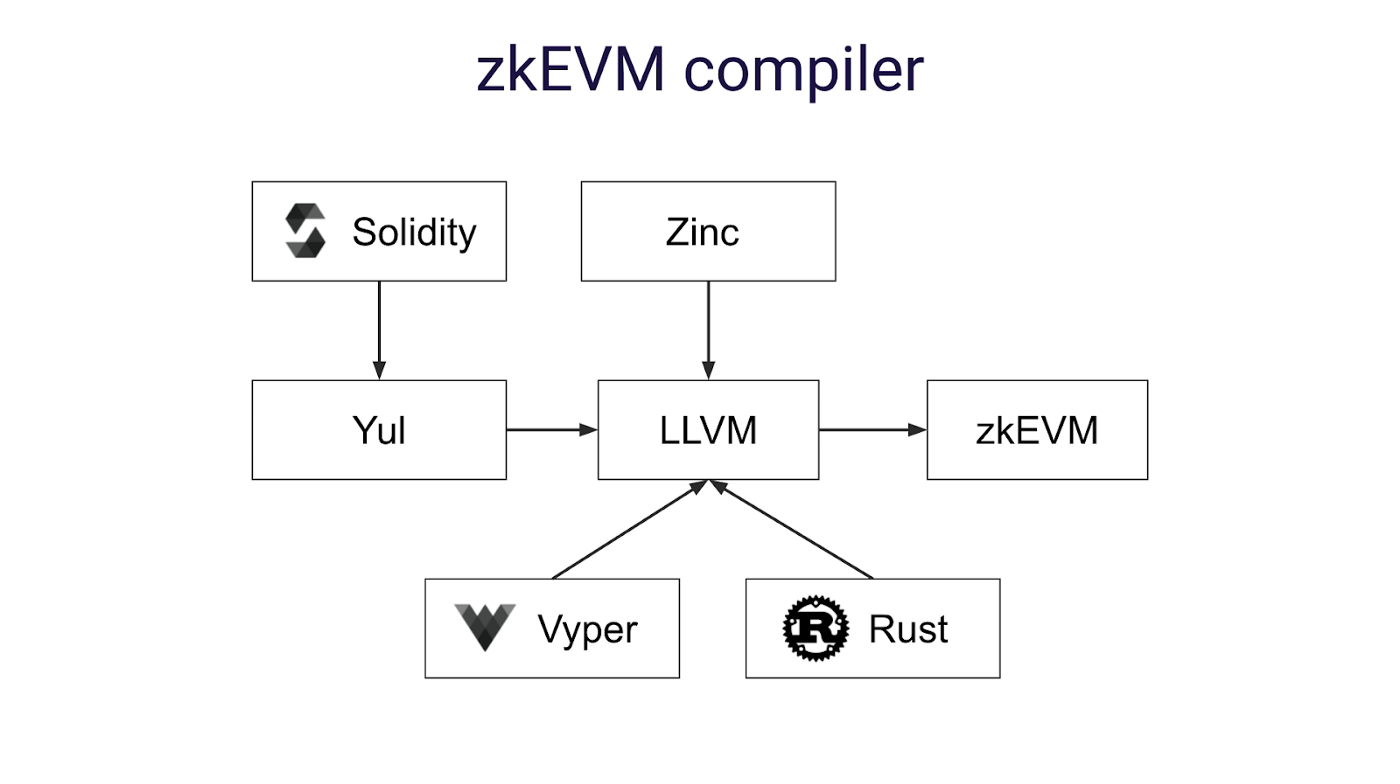
类似 Starkware,zkSync 2.0 通过开发编译器前端 Yul 和 Zinc 来实现 ZK-EVM 功能。Yul 是一种中间 Solidity 表示,可以编译为不同后端的字节码。Zinc 是用于智能合约和通用零知识证明电路的基于 Rust 的语言。它们都是基于开源框架 LLVM,能够实现最高效的 ZK-EVM 字节码。
https://miro.medium.com/max/1400/0*S3TKmlfGRTx5MNkE
与 StarkNet 一样,zkSync zkEVM 在语言层面实现了 EVM 的兼容性,而不是在字节码层面。
Polygon zkEVM
Polygon Hermez 是一个具有 zkVM 的 Polygon zk-rollup,旨在支持 EVM 的兼容性。为此,EVM 字节码被编译成 「微操作码(micro opcodes)」 并在 uVM 中执行,uVM 使用 SNARK 证明和 STARK 证明来验证程序执行的正确性。
Scroll zkEVM
Scroll 是一个EVM等效的zk-Rollup,可以实现与以太坊字节码级别的兼容性,也就是说,所有的EVM操作码和基础层完全相同。Scroll 团队计划为每个 EVM 操作码设计零知识电路。
https://github.com/privacy-scaling-explorations/zkevm-circuits
"Scroll design, architecture, and challenges" (Ye Zhang, Scroll)
Which is better?
https://vitalik.ca/general/2022/08/04/zkevm.html
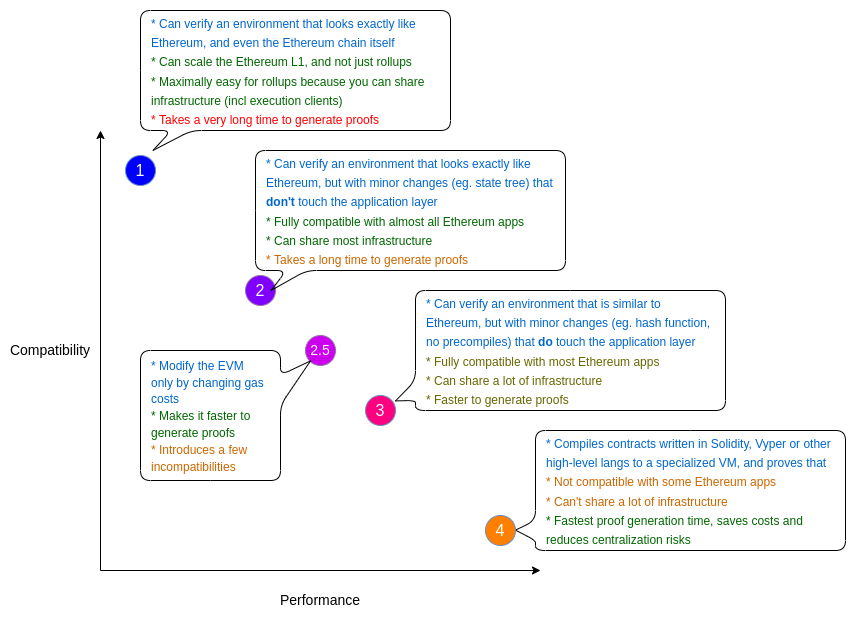
在 Vitalik 的博文里,他将 ZK-EVM 分为几种类型。其中,类型 1 是直接在以太坊上面直接开发 ZK-EVM,这个开发过于复杂而且目前效率太低,以太坊基金正在研究中。类型 2、类型 2.5 和类型 3 是 EVM 等效的 ZK-EVM,Scroll 和 Polygon Hermez 目前处于类型 3 这个阶段,朝着类型 2.5 乃至类型 2 努力。类型 4 是高级语言兼容的 ZK-EVM,包括 Starkware 和 zkSync。这些类型并无好坏之分,而且 ZK-EVM 也没有统一的标准。
从理论上讲,以太坊不需要为 L1 使用单一的 ZK-EVM 实现进行标准化;不同的客户可以使用不同的证明,因此我们继续从代码冗余中受益。— Vitalik Buterin
Overview
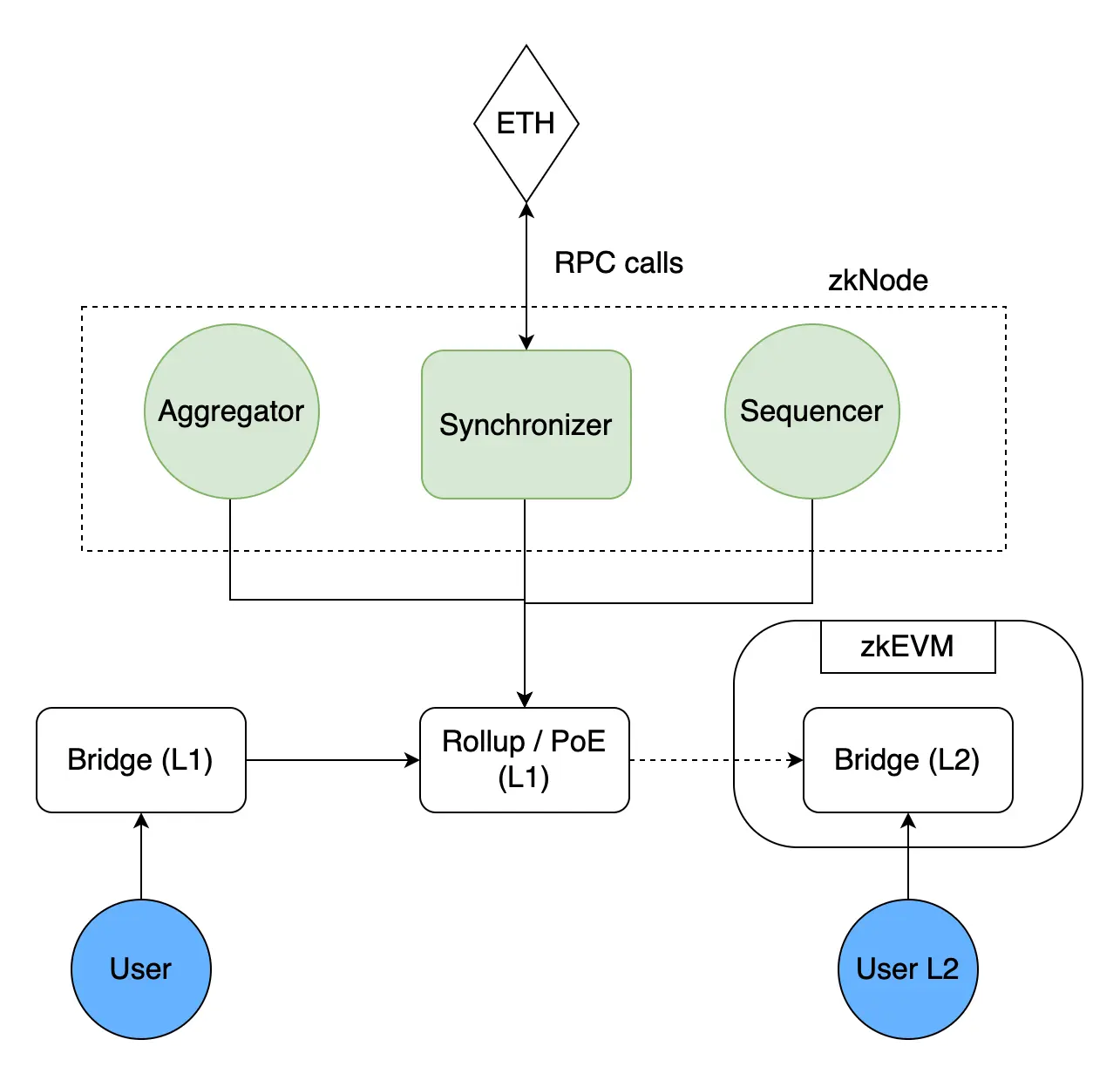
Polygon zkEVM主要包含以下组件:
Proof of Efficiency (PoE) Consensus Mechanism
- zkNode
- Synchronizer
- Sequencers & Aggregators
- RPC
- zkProver
- Bridge
PoE
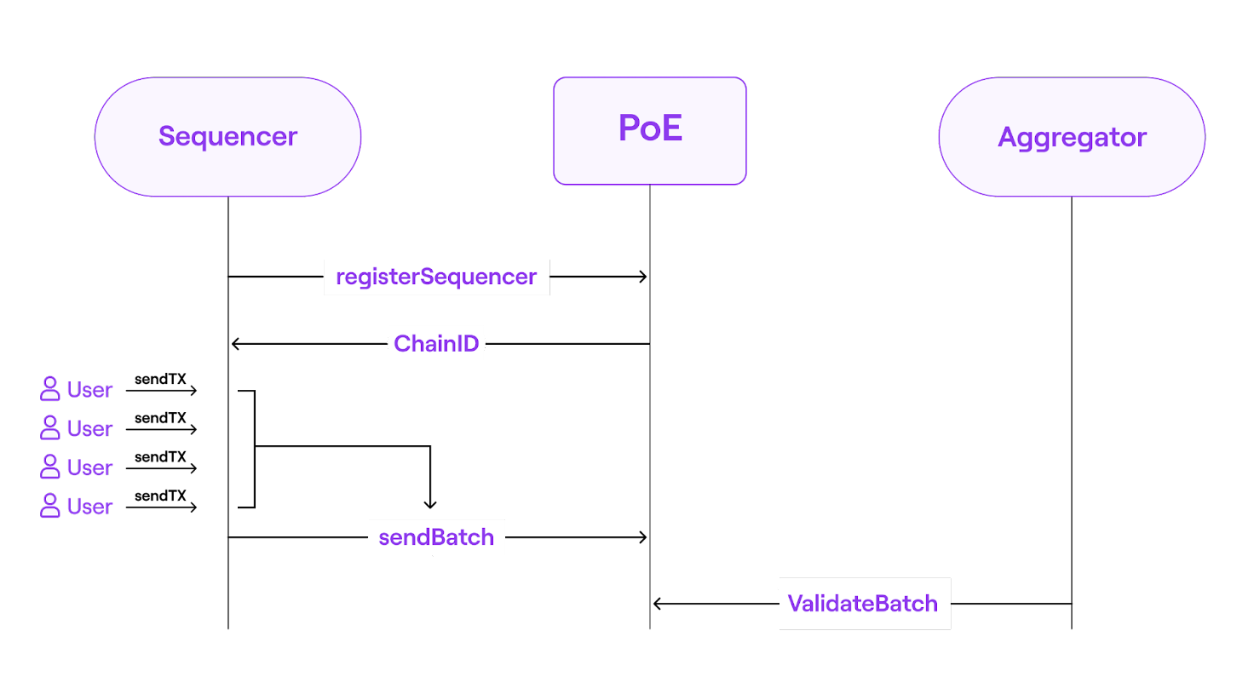
https://wiki.polygon.technology/ko/assets/images/fig2-simple-poe-7cb9c3761a3d3c6482eefba525598cd2.png
Proof-of-Efficiency(PoE)共识算法分2步实现,由不同参与者完成:
1)第一步的参与者称为Sequencer。sequencer负责将L2的交易打包为batches并添加到L1的PoE智能合约中。任何运行zkEVM-Node的参与者,均可成为Sequencer。每个Sequencer都必须以$Matic token来作为抵押物,以此来获得创建和提交batches的权利。Sequencer赚L2的交易手续费,但是只有相应的证明提交后,Sequencer才能获得其所提交的batch内的L2交易手续费。
2)第二步的参与者称为Aggregator。Aggregator负责检查batches的有效性,并提供相应的证明。作为Aggregator,需要运行zkEVM-Node和zkProver来创建相应的零知识证明,赚取Sequencer为batches支付的Matic费用。
PoE智能合约有2个基本的函数:
1)sendBatch:用于接收Sequencer提交的batches。
2)validateBatch:用于接收Aggregator生成的proof,并进行验证。
zkEVM-Node
Basic concept
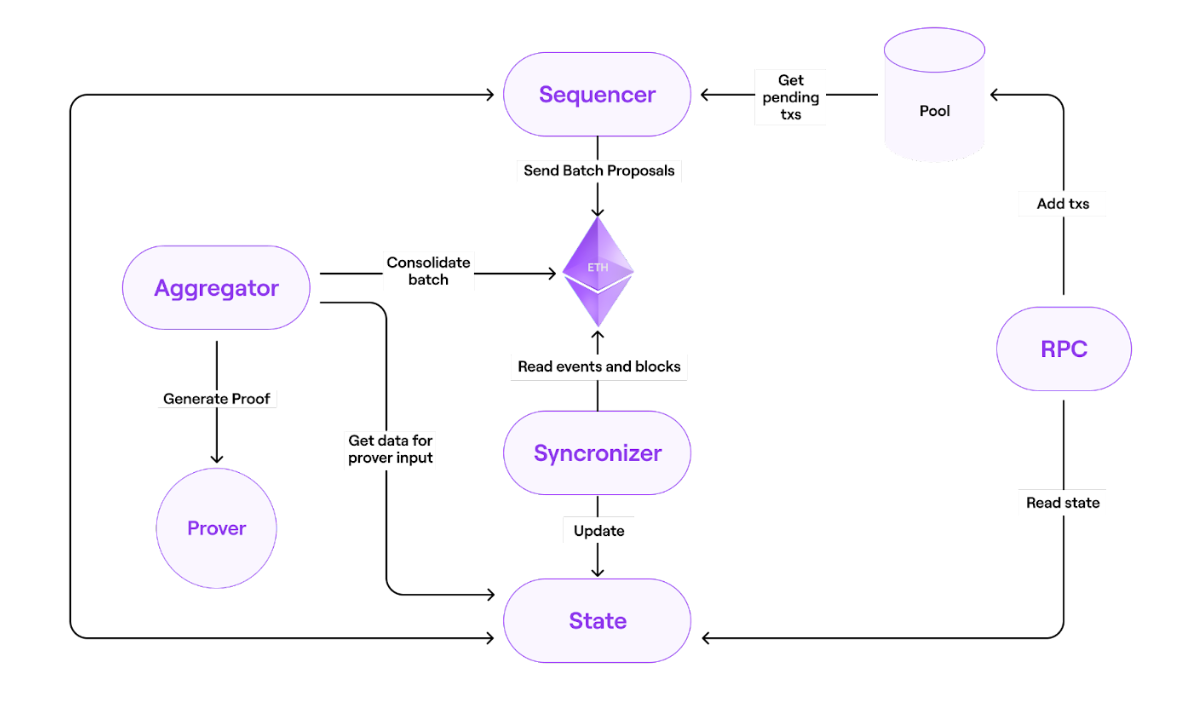
https://wiki.polygon.technology/ko/assets/images/fig3-zkNode-arch-aa4d18996fba1849291ea18e3f11d955.png
- Batch: 为一组使用zkProver来执行或证明的交易,会将batch发送到L1,也会从L1同步batch。
- L2 Block: 目前,所有的L2 block被设置成只包含一个交易,从来能够保证即时的确认。
- RPC:为用户(如metamask、etherscan等)与节点交互的接口。与以太坊RPC完全兼容,并附加了一些额外的端口。如与state交互可获得数据的接口;处理交易的接口;与pool交互存储交易的接口。
- Pool:通过RPC来存储交易的DB,pool中所存储的交易后续可由sequencer来选中或丢弃。
- Sequencer:
- Sequencer 从用户那里接收 L2 交易,将它们预处理为新的 L2 batch,然后将该 batch 作为有效的 L2 交易提交给 PoE 合约。 Sequencer 接收来自用户的交易,并将收取所有已发布交易的交易费。 因此,Sequencer 在经济上受到激励来发布有效交易,以便从中获得最大利润。
- Trusted sequencer: 具有特殊权限的Sequencer。这样做是为了实现快速最终确定并降低与使用网络相关的成本(较低的gas)。
- Permissionless sequencer:任何人都可以参与,但是会带来较慢的最终确认等问题,相应的,抗审查性和去中心化会好一些。目前尚未实现。
- Aggregator:通过生成零知识证明来验证之前提交的batches。它会通过向state发送请求来获得prover所需输入数据。一旦proof生成,即可发送到L1中的智能合约进行验证。
- Synchronizer:负责从以太坊区块链读取事件,通过etherman从以太坊获取数据更新state。Synchronizer从智能合约中获取的数据包括Sequencer发布的数据(交易)和Aggregator发布的数据(有效性证明)。所有这些数据都存储在一个巨大的数据库中,并通过JSON-RPC服务提供给第三方。
- Prover:生成ZK proofs的服务。注意Prover并未在zkEVM-Node中实现,而是从节点的角度将其当成是“黑盒”。当前Prover有2版实现:
- JS参考版本实现——zkevm-proverjs库
- C++生产版本实现——zkevm-prover库

- Etherman:对需与以太坊网络和相关合约交互的方法的抽象。
- State:负责管理存储在StateDB的状态数据(batches、blocks、transactions等),同时State还会处理与executor和Merkletree服务的集成。
- StateDB:为状态数据的持久层。
- Merkletree:该服务中存储Merkle tree,包含了所有的账号信息(如balances、nonces、smart contract code 和 smart contract storage)。Merkletree模块也并未在zkEVM-Node中实现,而是作为节点的一个外部服务实现在zkevm-prover中。
Source Code
./zkevm-node run --genesis ../config/environments/local/local.genesis.config.json --cfg ../config/environments/local/local.node.config.toml --components synchronizer
Sequencer
每个Sequencer都有一个配置,池子,状态,交易管理者,etherman,gpe等
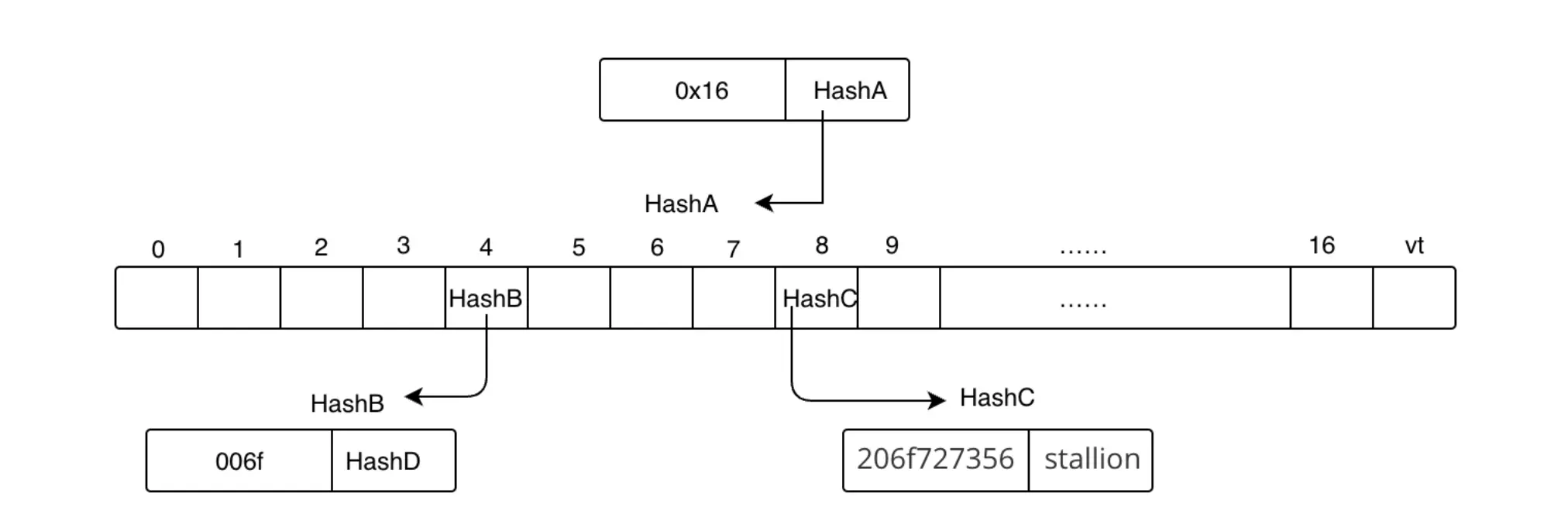
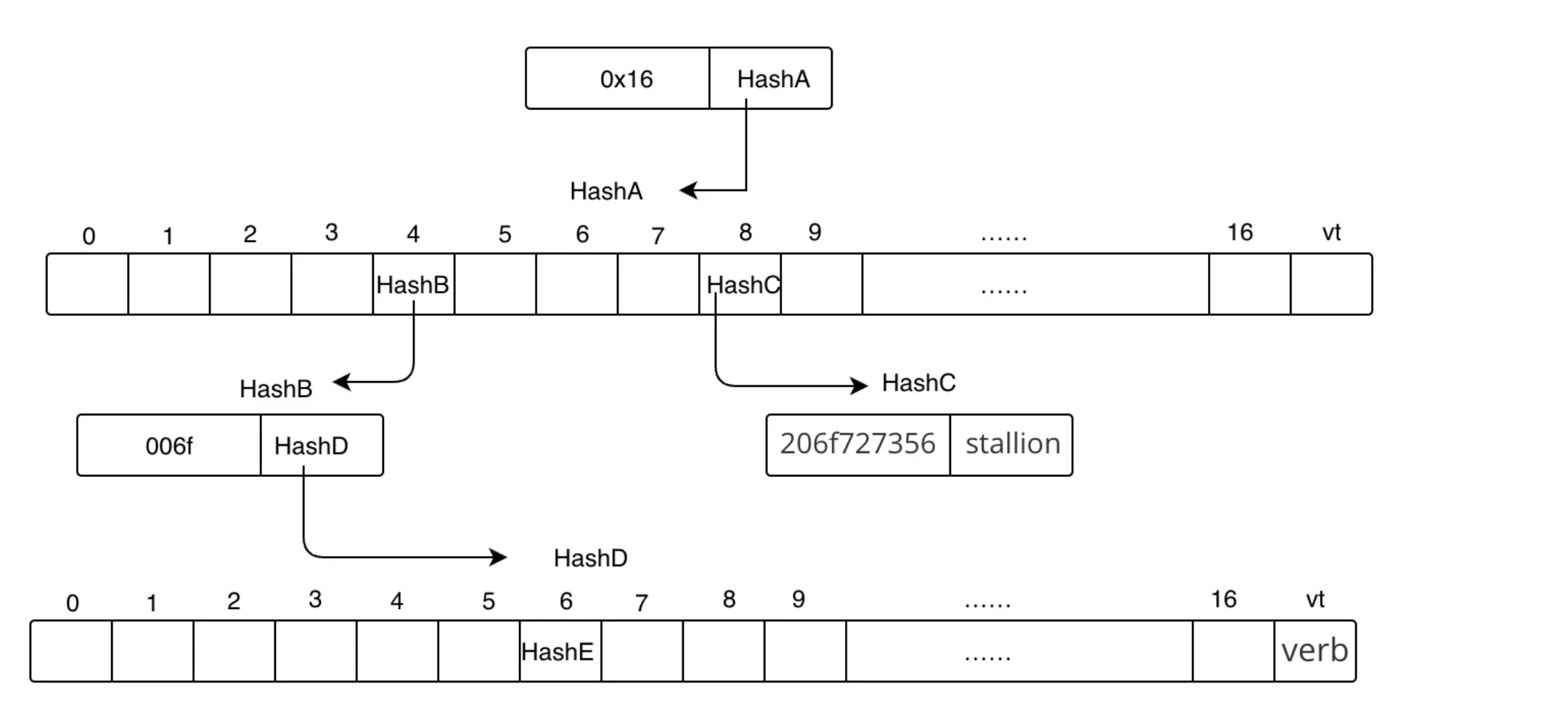
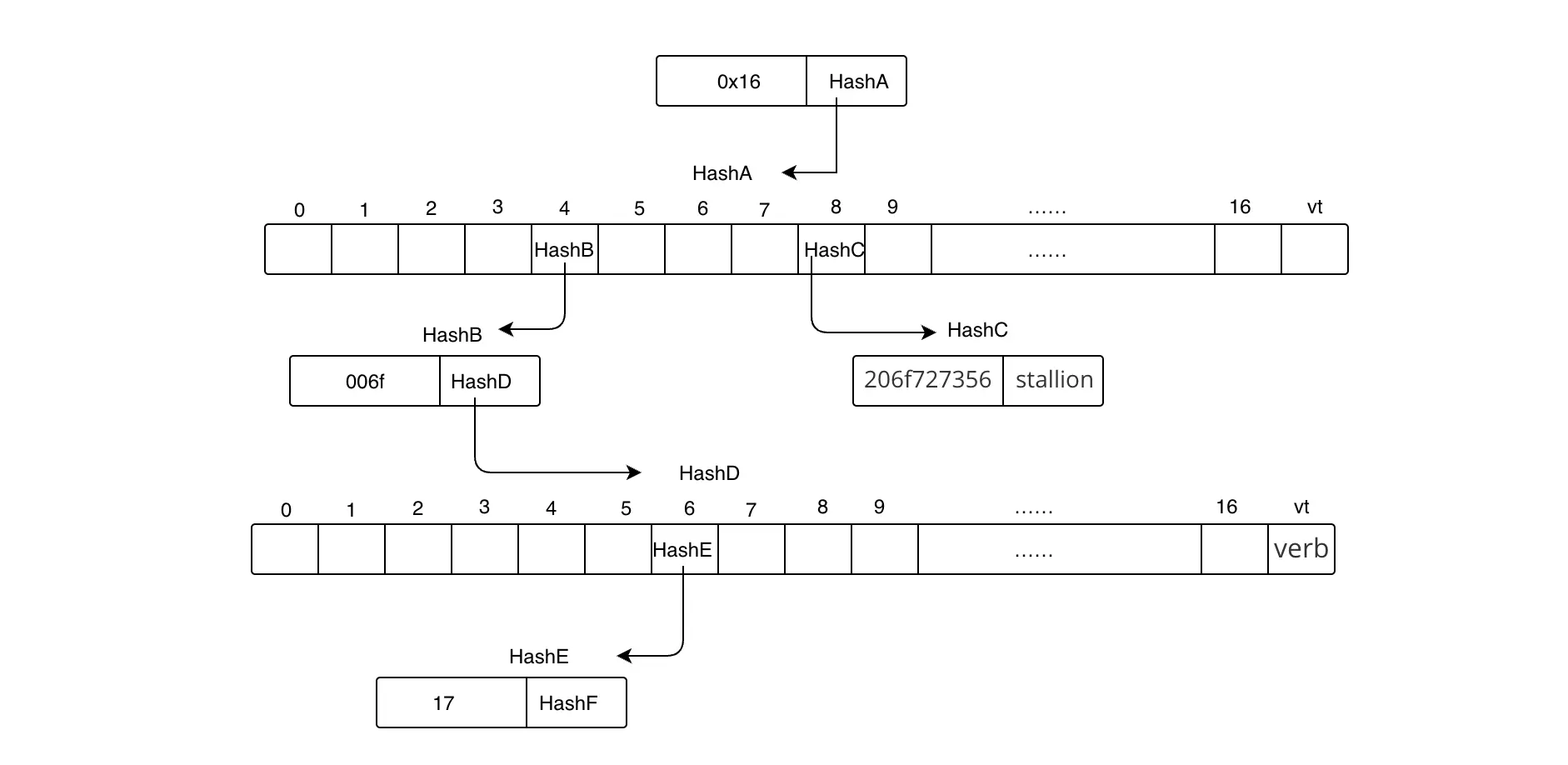
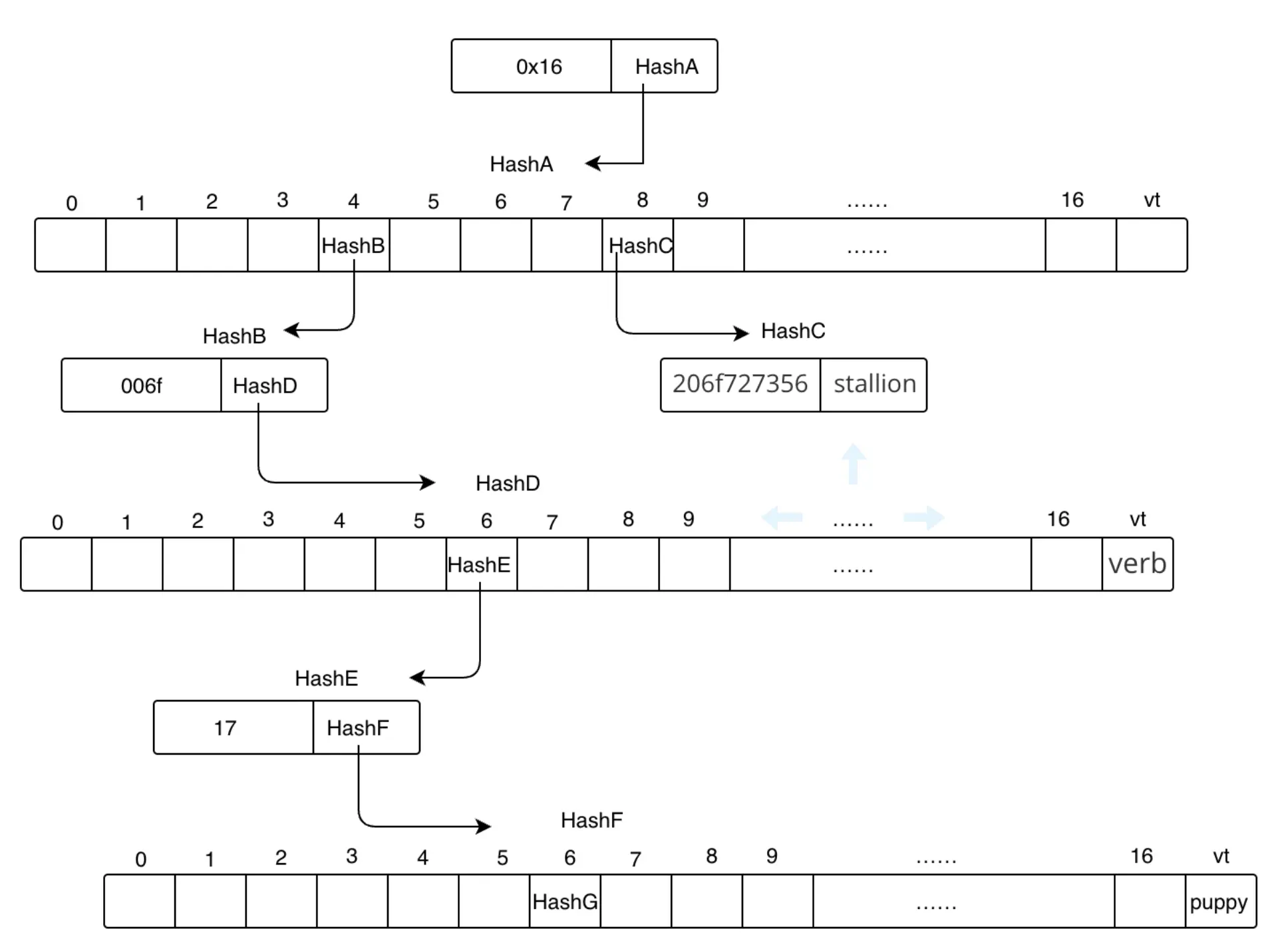
type Sequencer struct {
cfg Config
pool txPool
state stateInterface
txManager txManager
etherman etherman
checker *profitabilitychecker.Checker
gpe gasPriceEstimator
address common.Address
sequenceInProgress types.Sequence
}
start
- 循环调用isSynced,判断synchronizer是否同步完成
- 查询数据库state.virtual_batch执行sql获取lastSyncedBatchNum
- 调用接口从PoE合约中获取lastEthBatchNum
- 如果lastSyncedBatchNum<lastEthBatchNum,说明还没同步完成
- 同步完成后,初始化sequence,获取最新的batchNum
- 如果batchNum为0,创建创世区块
- 否则执行loadSequenceFromState,确定Sequencer中的sequenceInProgress,即确定一个序列
- 启动一个协程,执行trackOldTxs,将pool中已处理过的交易在数据库中删除
- 启动一个协程,执行tryToProcessTx来对交易进行处理
- 启动一个协程,执行tryToSendSequence,将sequence发送到L1
loadSequenceFromState
- 循环检查是否同步完成
- 执行MarkReorgedTxsAsPending,将重组的交易的状态从selected更新为pending
- 获取最新信息lastBatch和这个块是否被关闭了,如果关闭了:
- 开始一个状态交易
- 获取最新的global exit root,并构造一个进行时的上下文
- 调用OpenBatch将新的batch加入state中,batchnumber+1
- 更新Sequencer中的sequenceInProgress
- 否则,如果没有关闭
- 根据batchNumber获取所有交易
- 新建一个Sequence并设为当前Sequencer处理中的Sequence
trackOldTxs
- 获取即将要从pool中删除的交易的txHashes
- 根据txHashes中的hash,直接在数据库中删除
tryToProcessTx
- 检查同步
- 检查当前sequence是否应该被关闭,即batch中的交易数量是否超过了最大限制
- 备份当前sequence
- 处理sequenceInProgress中的txs
- 更新状态
tryToSendSequence
- 检查同步
- 获取需要被发送给L1的sequence数组
- 调用SequenceBatches,重试发送sequences给eth
Aggregator
type Aggregator struct {
cfg Config
State stateInterface
EthTxManager ethTxManager
Ethman etherman
ProverClients []proverClientInterface
ProfitabilityChecker aggregatorTxProfitabilityChecker
}
start
- aggregator中会建立很多对Prover的RPC连接,对aggregator中的每一个proverClient,都启动一个协程,调用tryVerifyBatch
- 启动一个协程,循环调用tryToSendVerifiedBatch
tryVerifyBatch
- 检查网络是否同步
- 调用getBatchToVerify获取需要被verify的state.Batch
- 根据获取的batch调用buildInputProver构建一个inputProver
- 在proverClients中找一个闲置的prover
- 调用GetGenProofID,这个函数会根据上面的inputProver生成一个genProofRequest,并调用prover的genProof生成一个proof,返回一个proofID
- 执行sql语句,将proof插入到state里面
- 调用getAndStoreProof,获取proof.Proof并更新
tryToSendVerifiedBatch
- 检查是否同步
- 调用GetLastVerifiedBatch获取最新的确认过的lastVerifiedBatch
- 调用GetGeneratedProofByBatchNumber获取proof
- 如果proof不为空,调用VerifyBatch,将proof发送给智能合约
- 成功后再删除proof
VerifyBatch
最后会调用POE的VerifyBatch进行验证
Synchronizer
Sync
- 获取dbTx
- 获取最新的区块lastEthBlockSynced,如果获取不到,用genesis区块
- commit dbTx
- 循环进行同步
- 调用syncBlocks从特定的块同步到最新块
- 从合约获取最新batch number:latestSequencedBatchNumber
- 从state获取latestSyncedBatch
- 如果latestSyncedBatch >= latestSequencedBatchNumber说明,合约的状态全部同步完成,就调用syncTrustedState
RPC
NewServer
在调用NewServer的时候,会调用registerService注册serviceName和service,保存在serviceMap中,serviceMap中包含service和funcMap
具体的:例如eth服务ethEndpoints,会遍历ethEndpoints的所有方法,并保存在funcMap中。
目前的serviceName:
const (
// APIEth represents the eth API prefix.
APIEth = "eth"
// APINet represents the net API prefix.
APINet = "net"
// APIDebug represents the debug API prefix.
APIDebug = "debug"
// APIZKEVM represents the zkevm API prefix.
APIZKEVM = "zkevm"
// APITxPool represents the txpool API prefix.
APITxPool = "txpool"
// APIWeb3 represents the web3 API prefix.
APIWeb3 = "web3"
)
start
- 初始化json rpc server,包括host和port
- 调用handle处理请求,从request中解析出serviceName和funcName,再从serviceMap和funcMap中获取service和funcData并调用相关函数进行处理,获取结果
zkProver
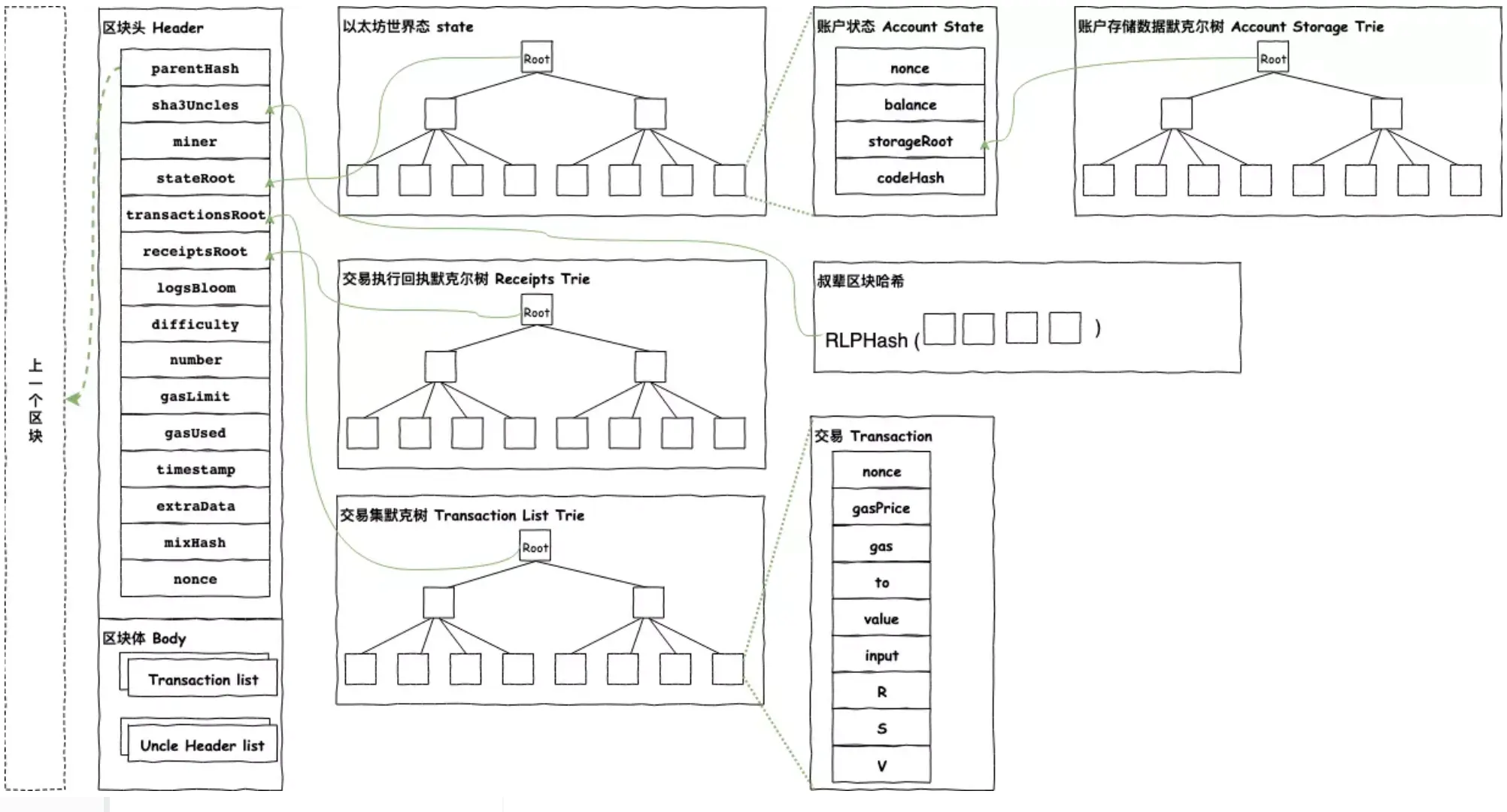
Polygon zkEVM 中交易的证明全部由zkProver来处理。通过电路来保证交易执行的有效性。zkProver 以多项式和汇编语言的形式执行复杂的数学计算,随后在智能合约上进行验证。
Interation with Node and Database

如上面的流程图所示,整个交互分为4步:
- 节点将 Merkle 树的内容发送到数据库以存储在那里
- 节点然后将输入交易发送到 zkProver
- zkProver 访问数据库并获取生成证明所需的信息。 这些信息包括Merkle树根、相关siblings的键和hash等
- zkProver 然后生成交易证明,并将这些证明发送回节点
Components
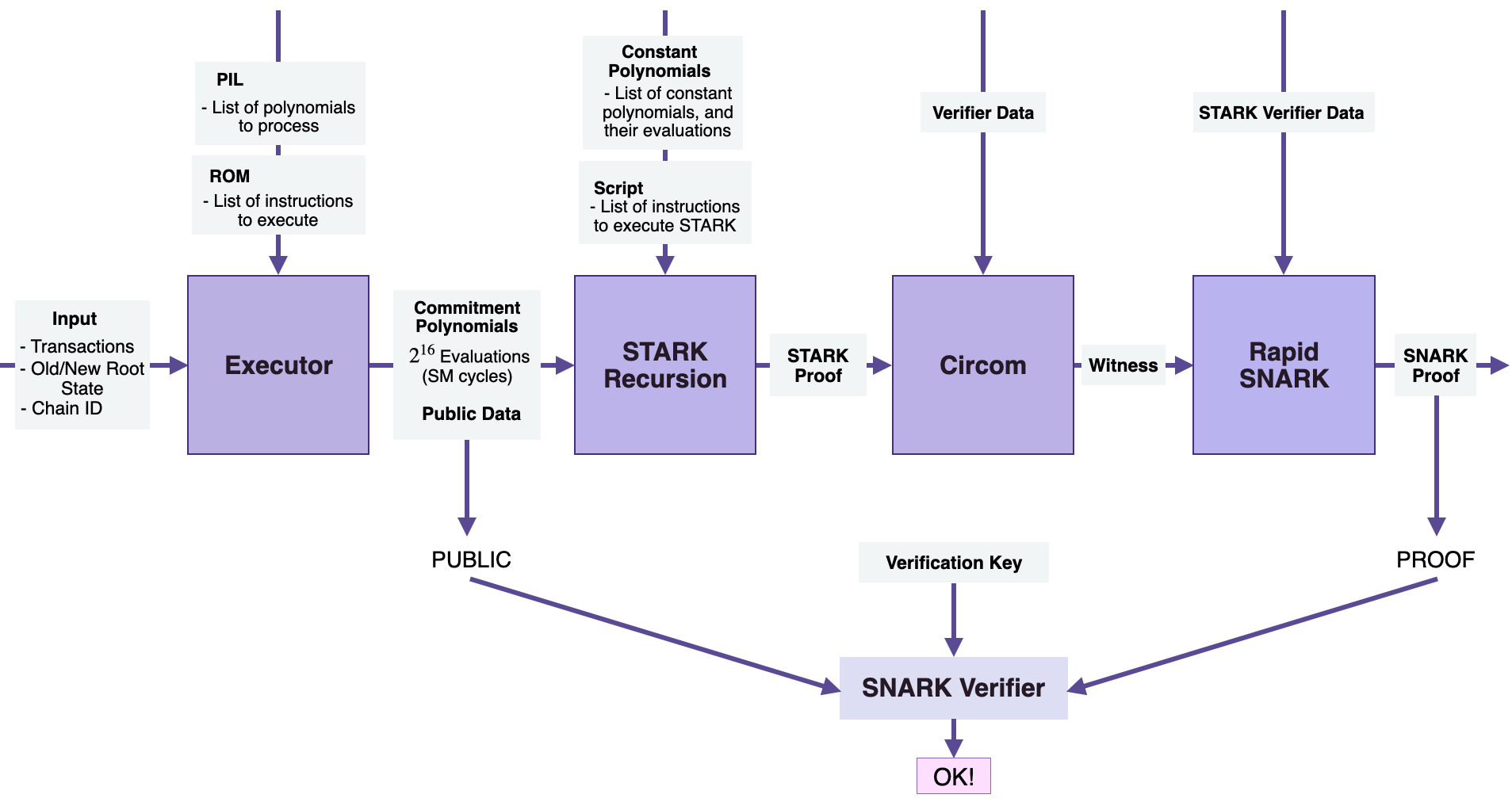
而zkProver的内部可以看作由以下四个部分组成:
Exector
Executor其实就是Main State Machine Executor。它将交易、新旧状态根等作为输入。
同时Exector还使用:
- PIL(Polynomial Identity Language)和一些寄存器
- ROM:存储与执行相关的指令列表。
有了这些,Executor会生成承诺多项式和一些公共数据,这些公共数据构成了 zk-SNARK 验证器输入的一部分。
STARK Recursion
Main State Machine Executor将交易和相关数据转换为承诺多项式之后会作为STARK 递归组件的输入:
- 承诺多项式
- 常数多项式
- 脚本,它是指令列表,为了生成 zk-STARK 证明
为了促进快速 zk-STARK 证明,STARK 递归组件使用Fast Reed-Solomon Interactive Oracle Proofs of Proximity (RS-IOPP),也称为 FRI,用于每个 zk-proof。
Circom Library
最初的Circom论文将其描述为定义算术电路的电路编程语言和编译器。
- 包含一组关联的 Rank-1 约束系统 (R1CS) 约束的文件
- 一个程序(用 C++ 或 WebAssembly 编写),用于有效地计算对算术电路所有连线的valid assignment。
STARK 递归组件生成的单个 zk-STARK 证明会作为 Circom 组件的输入。
Circom是 zkProver 中使用的电路库,用于为 STARK 递归组件生成的 zk-STARK 证明生成witness。
zk-SNARK Prover
最后一个组件是 zk-SNARK Prover,或者说Rapid SNARK。
Rapid SNARK是一个 zk-SNARK 证明生成器,用 C++ 和英特尔汇编语言编写,可以非常快速地生成Circom输出的证明。目前支持PLONK/Groth16.
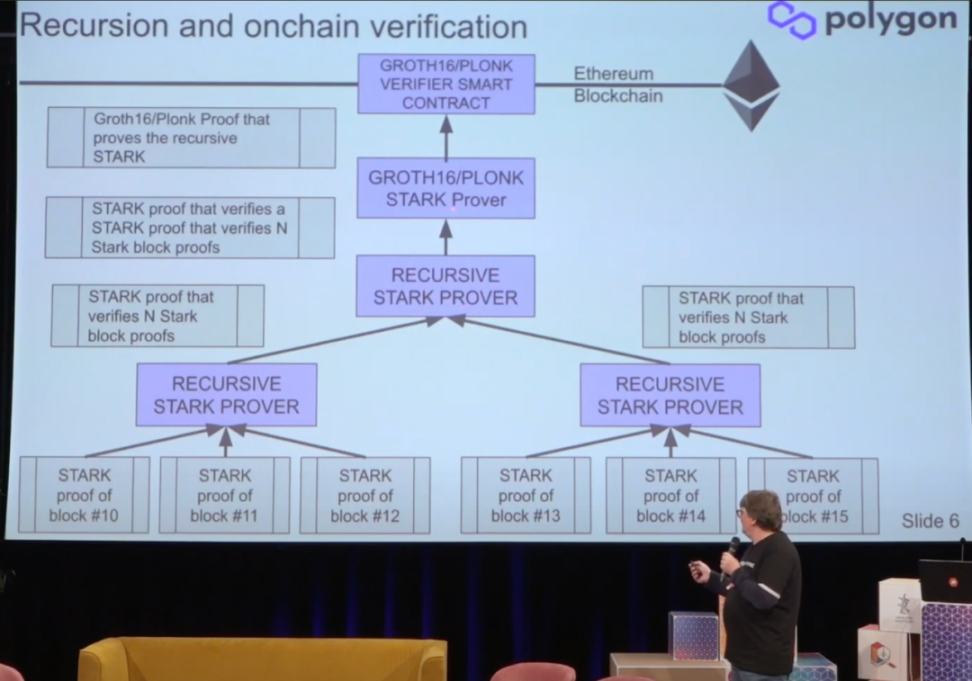
之所以采用两套证明系统是因为STARK 证明的生成速度更快,但是证明的规模却很大,在链上验证的时候开销也很大,SNARK 由于更小的证明规模和更快的验证速度,所以在以太坊上验证会更便宜。
https://github.com/matter-labs/awesome-zero-knowledge-proofs
Polygon Hermez zkEVM 使用一个 STARK 证明电路来生成状态转换的有效性证明,用 SNARK 证明验证 STARK 证明的正确性(可以认为是生成「证明的证明」),并将 SNARK 证明提交到以太坊进行验证。
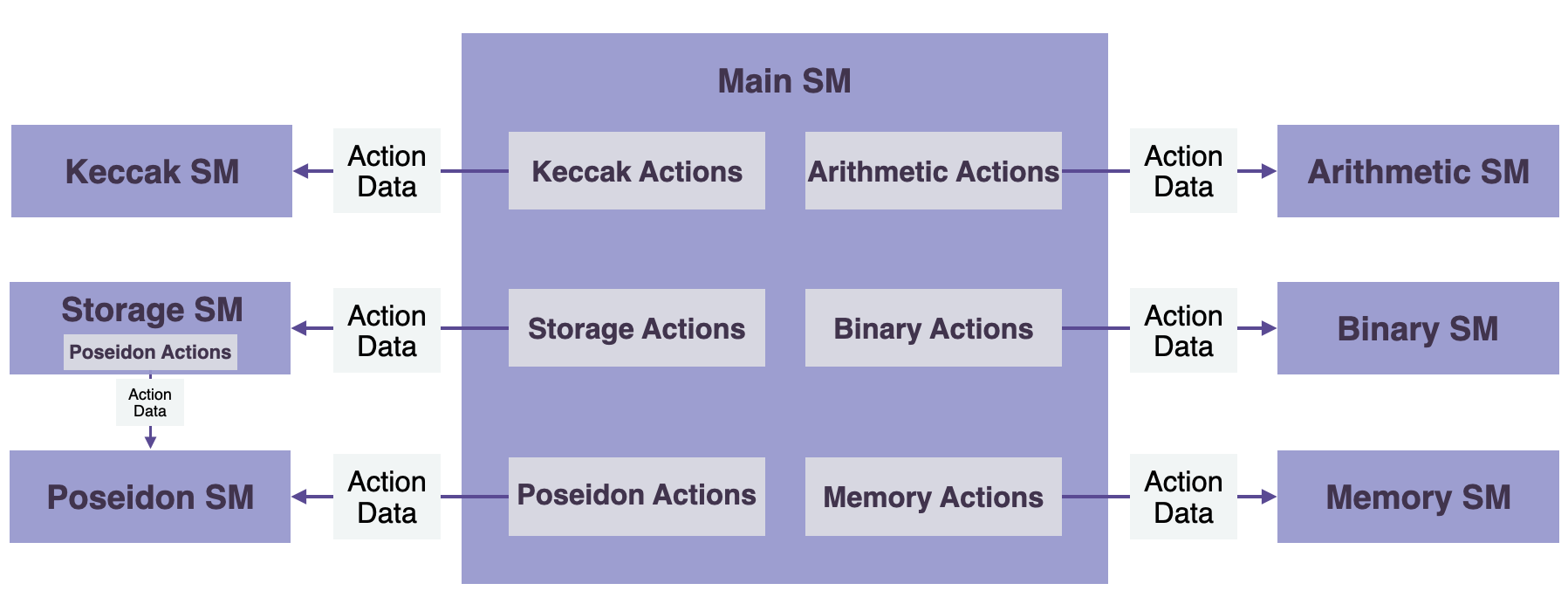
State Machines
zkProver 遵循模块化设计,包含14个状态机,分别对应不同的一些操作:
- The Main State Machine
- Secondary state machines:The Binary SM, The Storage SM, The Memory SM, The Arithmetic SM, The Keccak Function SM, The PoseidonG SM
- Auxiliary state machines:The Padding-PG SM, The Padding-KK SM, The Nine2One SM, The Memory Align SM, The Norm Gate SM, The Byte4 SM, The ROM SM
How to run
Requirement
zkEVM-Prover: 128vCPU, 1T RAM Recommended by Hermez Team
Config
zkEVM-Node config: https://github.com/0xPolygonHermez/zkevm-node/blob/develop/config/environments/public/public.node.config.toml
zkEVM-Prover config:https://github.com/0xPolygonHermez/zkevm-prover/blob/main/config/config_prover.json
Notes
- prover如果配置了statedb为local的话会把数据暂时存在内存中,没有做持久化,一旦重启prover会丢失数据。
- 在zkevm-contrant下deployment/deployment_v2-0/deploy_parameters.json 中配置好trustedSequencerAddress,保证zkevm-node/config/environments中的node.config.toml中etherman中的PrivateKeyPath配置项的keystore文件对应的是该地址的私钥,否则Sequencer提交交易会报错。
- trustedSequencerAddress不要用hermez官方仓库的私钥对应的地址。
- 如果修改了l2的genesis相关配置需要保证合约目录下的deployment/deployment_v2-0/genesis.json和node目录下的config/envirment/中的genesis对应起来。
Resources
Github:https://github.com/0xPolygonHermez
Docs:
https://wiki.polygon.technology/ko/docs/zkEVM/introduction
https://docs.hermez.io/zkEVM/Overview/Overview/
转载自:https://learnblockchain.cn/article/5336


{kind=link}
{kind=link}